1. Iris DataSet
- DataSet : 특정한 작업을 위해 데이터를 관련성 있게 모아놓은 것
- 사이킷런 데이터셋 페이지
from sklearn.datasets import load_irisiris = load_iris()
iris
print(iris['DESCR'])
class는 3가지 독립변수는 4가지 입니다.
data =iris['data']
data
한 줄이 값이고 그게 150개가 있다는것
2.레이블 확인
target = iris['target']
target
0번꽃, 1번꽃, 2번에대한 부분 출력을 확인할 수 있음 150개
컬럼명으로 쓸만한 이름이 4가지가 있다는것을 확인할 수 있습니다.
feature_names = iris['feature_names']
feature_names


3. padnas를 이용 및 확인
import pandas as pd
df_iris = pd.DataFrame(data, columns=feature_names)
df_iris
target.shape
#(150,0)4. 변수 추가(없는 컬럼만들기)
df_iris['target']=target
df_iris
일반적으로 1만개 이상이면 데이터가 있다 라고하고
1만개 이하면 조금 부족하다고 생각해볼 수 있습니다.
트레이닝 데이터가 많으면 학습데이터는 60%, 검증을 35~40%
트레이팅데이터가 좀 적으면 학습은80%, 검증은 20%정도로 합니다.
사이킷에 위와같이 나눠주는 모듈이있습니다.
from sklearn.model_selection import train_test_split-실무에서는 test로 비율을 나누어주고 test를 또 가서 나눠주며 검증합니다.
# train_test_split(독립변수, 종속변수, 테스트사이즈, 시드값 ...)
X_train, X_test, Y_train, Y_test = train_test_split(df_iris.drop('target', axis=1),
df_iris['target'],
test_size=0.2,
random_state=2024)여기서 시드값이란 섞이는 값이라고 합니다. 그래서 숫자 아무거나 사용하면 됩니다.
꼭!알아야할 부분
머신러닝은 데이터의 확률영역입니다.
시드값은 섞이는 상수값입니다 예를들어 2024라고 하면 그 숫자로 알고리즘을 넣어서 섞어줍니다.
그리고 항상 2024로 섞는건 동일합니다. 1번이 3번가있고 뭐 이런게 고정적이 됩니다.
만약 결과를 봤는데 잘 나왔다고 끝이아니라 다른 검증들도 해봐야되는데
섞임값이 고정적이여야 데이터 전처리를 다시해보던지 모델을 적합하지 않았는지 확인할 수 있습니다.
X_train.shape, X_test.shape
#((120, 4), (30, 4))
#트레이닝 라벨값 #테스트 라벨값
Y_train.shape, Y_test.shape
#((120,), (30,))5. sklearn.svm & 검사
from sklearn.svm import SVC
from sklearn.metrics import accuracy_scoreSVC란
정밀하게 분류해주는 알고리즘입니다. 리니어같은경우에는 X,Y를 합쳐져서 한번에 분리해주지만
SVC는 다차원적으로 확인할 수 있습니다.
6. 객체만들기
svc = SVC()
svc.fit(X_train, Y_train)
7. 검증하기
y_pred = svc.predict(X_test)
y_pred

8. 검증& 비하기(2)
print('정답률: ', accuracy_score(Y_test, y_pred))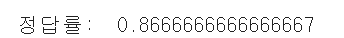
9. 정답률이 만족스럽지 않기에 데이터를 다시 섞도록 합니다.
X_train, X_test, Y_train, Y_test = train_test_split(df_iris.drop('target', axis=1),
df_iris['target'],
test_size=0.2,
random_state=2023)*섞임정도를 변경해봄 *2024->2023
X_train
svc.fit(X_train, Y_train)
y_pred = svc.predict(X_test)
y_pred
print('정답률: ', accuracy_score(Y_test, y_pred))
#정답률 : 1.010. 높은정답률을 보고 데이터 넣어서 확인해보기
# 6.7 3.3 5.7 2.1
y_pred = svc.predict([[6.8, 3.2, 5.6, 2.2]])
y_pred데이터를 4개 6.7, 3.3, 5.7, 2.1을 기준으로 살짝 바꿔서 데이터를 넣어봤습니다.
예측된 결과가 어떤건지 확인해봤습니다.

2번꽃이 나왔습니다.
잘 맞네요
리뷰
| 사용 | 설명 |
| train_test_split(독립변수, 종속변수, 테스트사이즈(비율), 시드값(섞이는 값)) | test스플릿트 사용방법입니다. |
'AI 컴퓨터 비전프로젝트' 카테고리의 다른 글
| [ML] 선형 회귀_Rent값 예측 모델 만들기(2) (0) | 2024.07.04 |
|---|---|
| [ML] 선형 회귀_Rent값 예측 모델 만들기(1) (0) | 2024.07.02 |
| [Python] 판다스(pandas) 데이터 프레임 합치기,산술연산, 원핫인코딩 등 (1) | 2024.06.18 |
| [Python] 판다스(pandas)를 이용한 데이터 다루기 (0) | 2024.06.14 |
| [Python] 넘파이, 행렬, 정렬 (2) | 2024.06.13 |



