1. 판다스(Pandas)
- 데이터 분석을 위한 파이썬 라이브러리 중 하나로, 표 형태의 데이터나 다양한 형태의 데이터를 쉽게 처리하고 분석할 수 있게 해줍니다.
- 데이터프레임(DataFrame)이라는 자료구조를 제공
#판다스 설치
#판다스 임포트
import pandas as pd
2. Series와 DataFrame
2-1. Series
- Series는 1차원 배열과 같은 자료구조로 하나의 열(cloum)을 나타냄
- Series의 각 요소는 인덱스(index)와 값(value)으로 구성되어 있음
- 값은 넘파이의 ndarray 기반으로 저장됨
- Series는 다양한 데이터 타입을 가질 수 있으며 정수, 실수, 문자열 등 다양한 형태의 데이터를 담을 수 있음
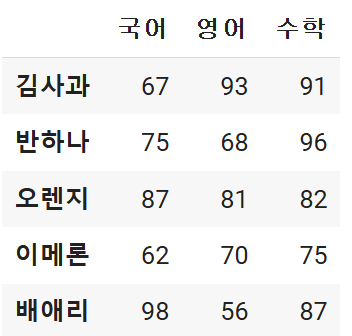
0 67
1 75
2 90
3 62
4 98
dtype: int64저장되지 않은 값이기에 찍어주고 사라집니다. 이 부분을 저장하기 위에서는 아래처럼 변수를 만들어주고 저장합니다.
김사과 67
반하나 75
오렌지 90
이메론 62
배애리 98
dtype: int64실제로 인덱스, 벨류인지확인하기
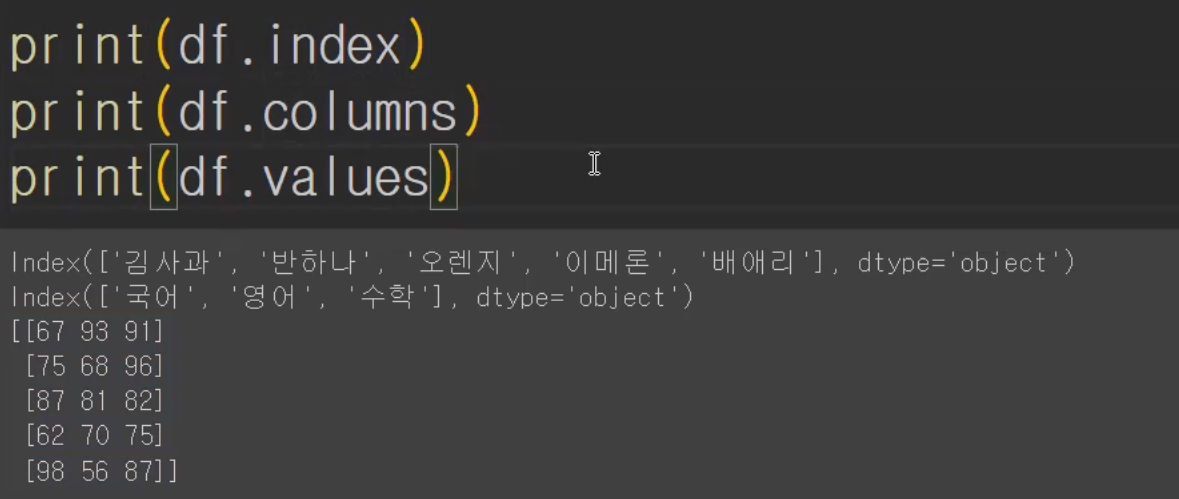
▶ Index(['김사과', '반하나', '오렌지', '이메론', '배애리'], dtype='object')
여기서 object는 str으로 생각해도 됩니다.
[67 75 90 62 98]
numpy.ndarray2-2. DataFrame(★★★★★)
- 데이터프레임은 판다스 라이브러리에서 제공하는 중요하고 강력한 데이터 구조로 2차원의 테이블 형태 데이터를 다룸
- 데이터프레임의 요소는 인덱스(index),열(column),값(value)으로 구성되어 있음
- 데이터프레임은 행과 열로 이루어져있으며 각 열은 다양한 데이터 타입을 가질 수 있음
- 값은 넘파이의 ndarray기반으로 저장
pd.DataFrame(data, idx..)등 순서가 정확히 맞아야합니다. 순서가 안맞으면 error뜸
그런데 파이썬에서는 파라미타명으로 쓰면 순서가 안 맞아도 데이터가 잘 들어가게 됩니다.
pd.DataFrame(index=idx, columns=col, data=data)
이 부분을 df라는 변수에 저장하겠습니다.
출력
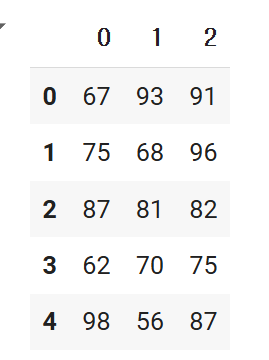
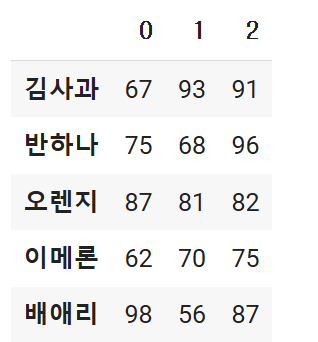
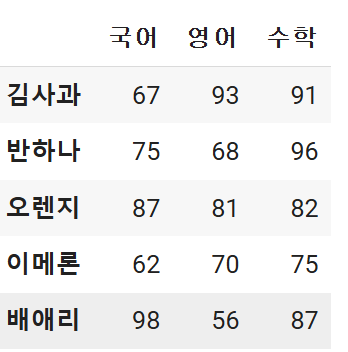
이렇게 모든 자료가 잘 들어가있음을 확인할 수 있습니다.
2-3. 딕셔너리를 사용하여 데이터프레임 생성하기
dic을 넣으면 columns가 됩니다. 그래서 index만 넣으면 됩니다.
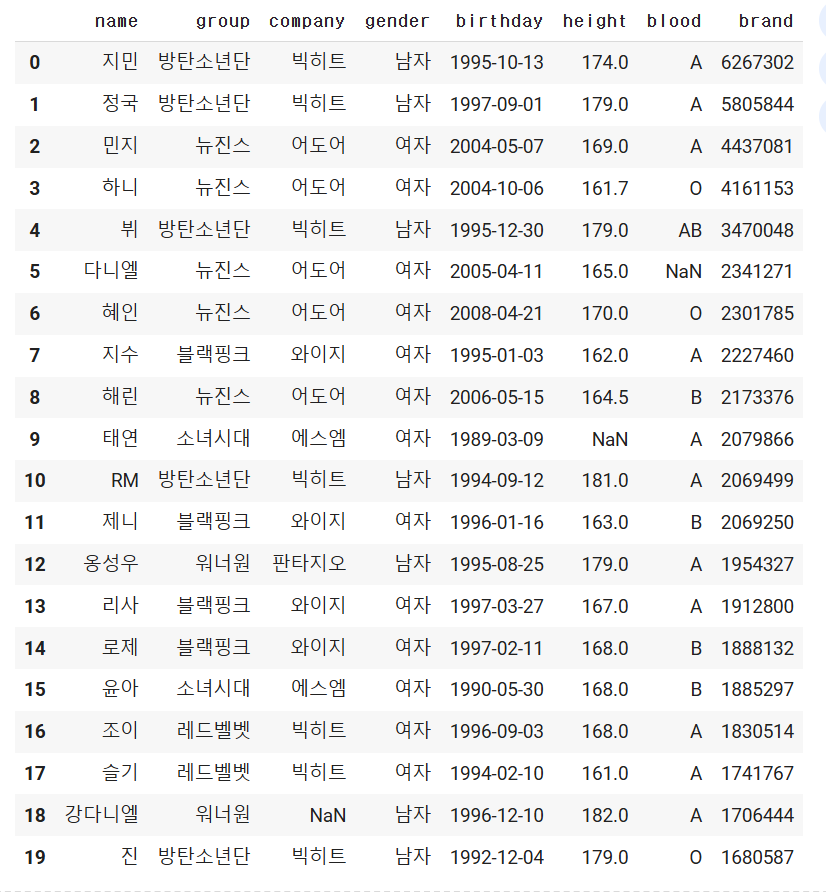
3. CSV 파일 읽어오기(구글코랩)
*데이터 프레임 기본정보 예제를 하기 위해서는 정확하지않은 혹은 임의적인 파일을제작하여 수업을 진행했습니다
- CSV(Comma Separated Value)의 약자로 데이터를 쉼표로 구분한 파일
드라이브로 연결하기 -> 경로는 각각 다르기때문에 각자 경로를 가져와서 붙여넣습니다.
df = pd.read_csv('경로')
df이렇게 되면 csv파일이 판다스로 나오게 됩니다.
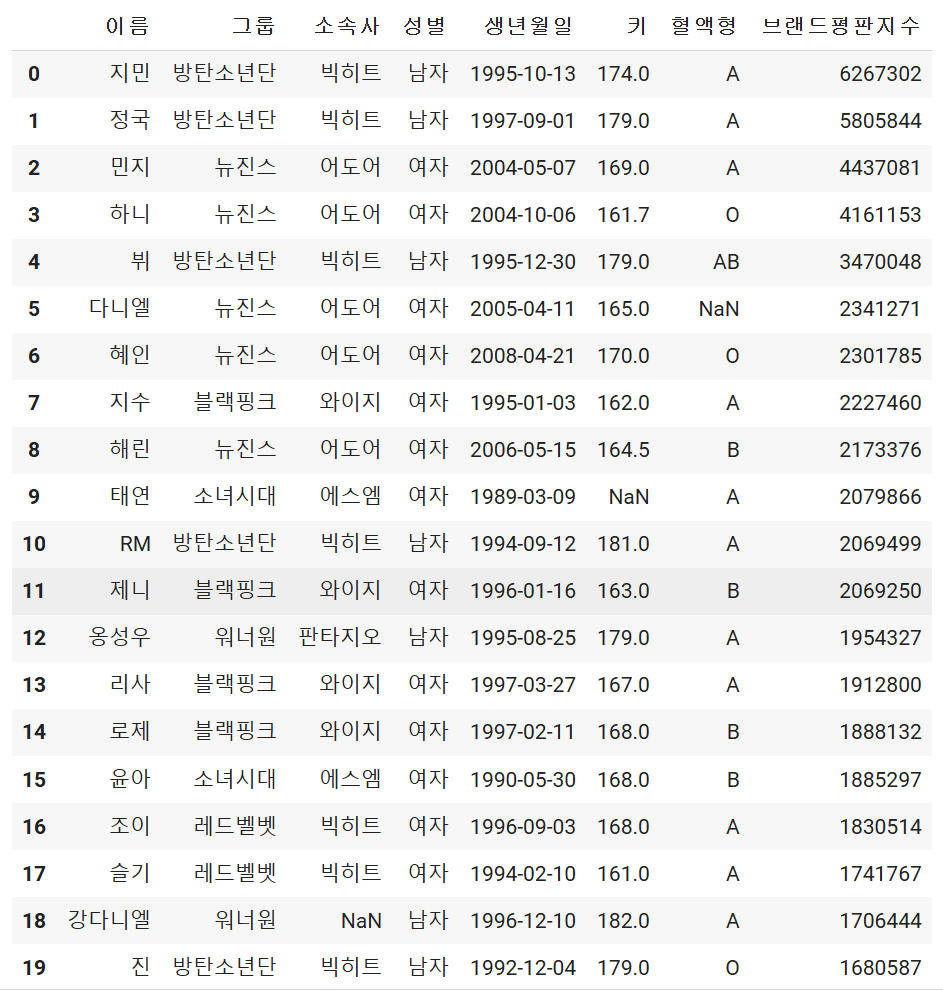
4. 데이터프레임 기본정보 알아보기
#info(): 행(row), 열(column)의 기본적인 정보와 데이터 타입을 반환
#Dtype에는 str이 없어서 object를 str로 생각하면 됩니다.
df.info()
#null값 확인하기
총 데이터가 20개인 dsv파일이었는데 19인건 값이 없다는 말입니다.
object는 strf로 dtype을 확인할 수 있습니다.
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 20 entries, 0 to 19
Data columns (total 8 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 이름 20 non-null object
1 그룹 20 non-null object
2 소속사 19 non-null object
3 성별 20 non-null object
4 생년월일 20 non-null object
5 키 19 non-null float64
6 혈액형 19 non-null object
7 브랜드평판지수 20 non-null int64
dtypes: float64(1), int64(1), object(6)
memory usage: 1.4+ KB
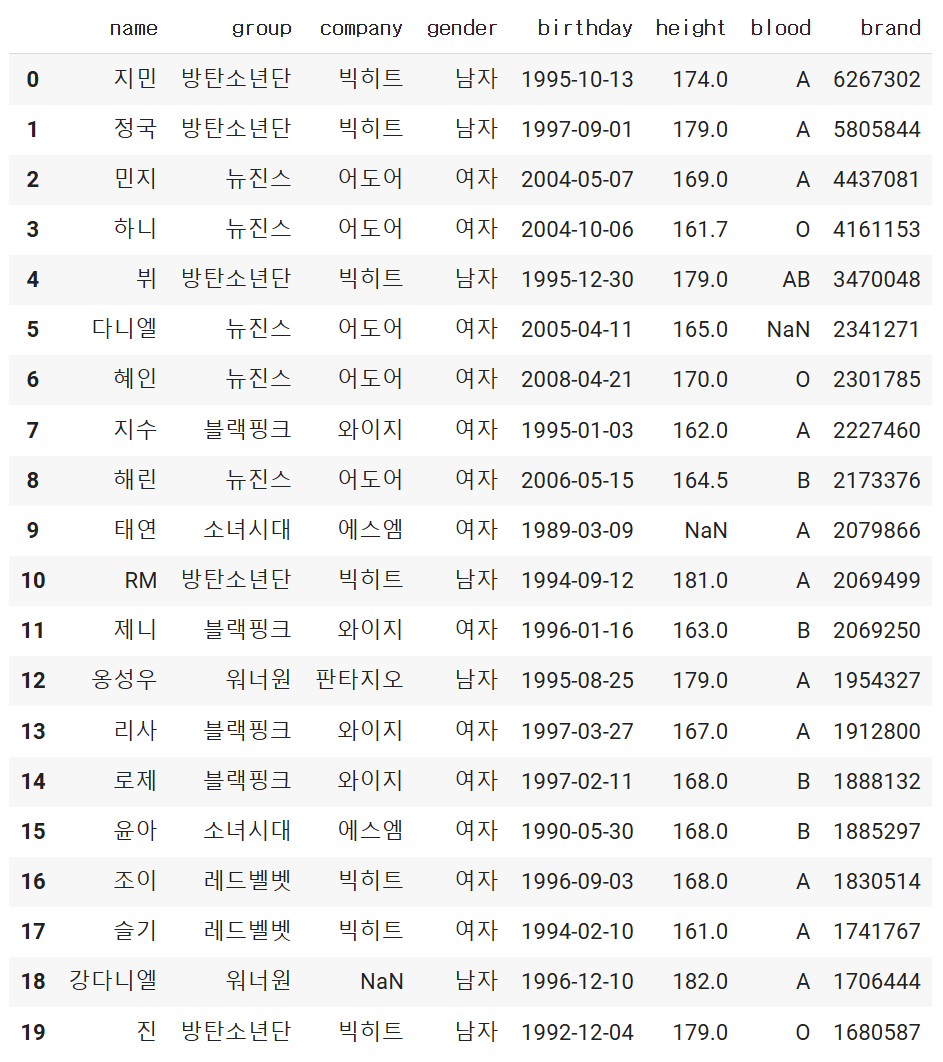
#컬럼명 변경하기
print(df.columns) #Index(['이름', '그룹', '소속사', '성별', '생년월일', '키', '혈액형', '브랜드평판지수'], dtype='object')
new_columns = ['name', 'group', 'company', 'gender', 'birthday', 'height', 'blood', 'brand']
df.columns = new_columns
print(df.columns)
#출력된 값
Index(['name', 'group', 'company', 'gender', 'birthday', 'height', 'blood',
'brand'],
dtype='object')
df을 하게되면 데이터프레임을 확인할 수 습니다.
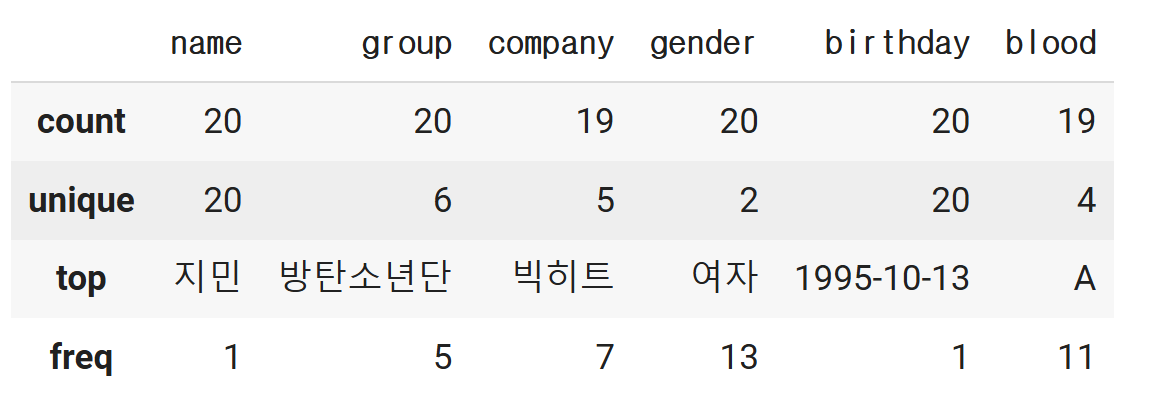
# describe(): 통계 정보를 반환
# 기본 값은 수치통계 정보만 반환해줍니다.
df.describe()
df.describe(include=object)
#Top: 최빈값을 의미합니다.
#freq: 최빈값의 빈도를 의미합니다.



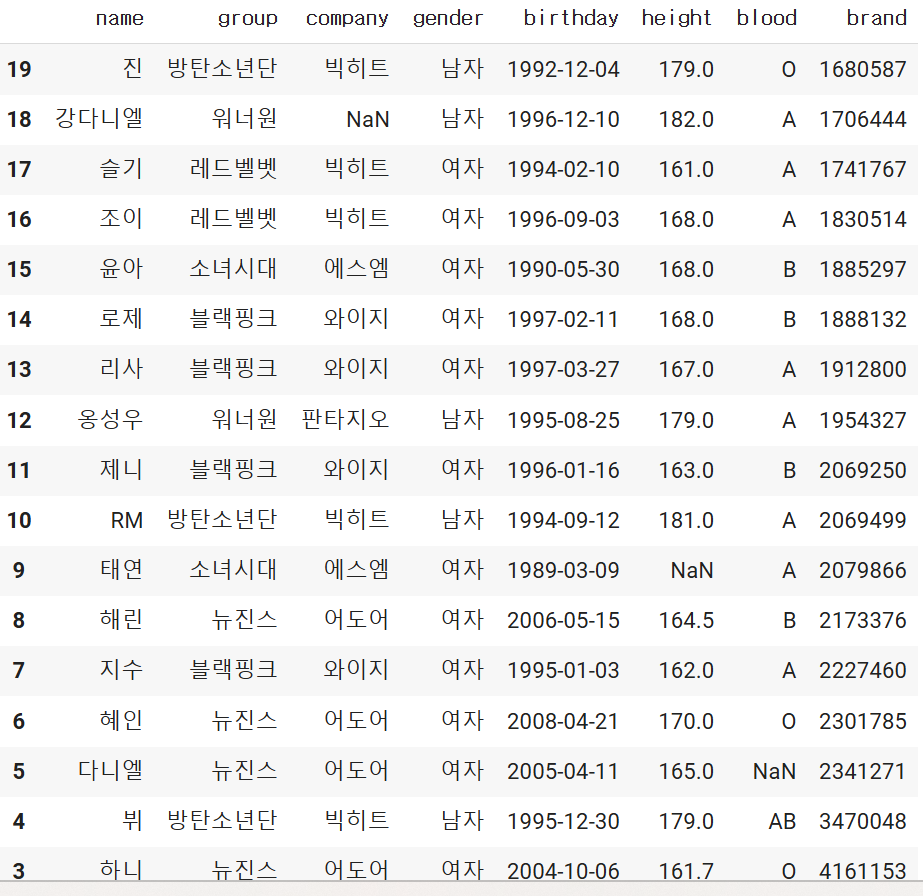
2차정렬로 두개를 한 번에 묶고싶을떄는 리스트를 사용할 수 있습니다.
5. 데이터 다루기
범위 선택하기

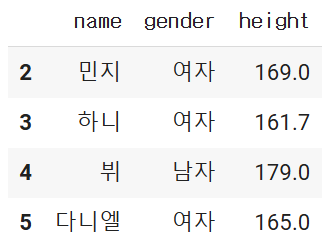






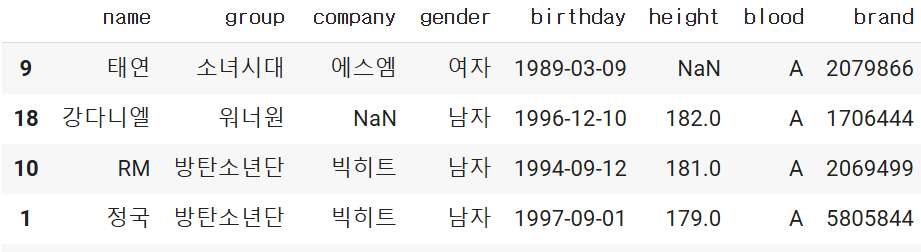
문제
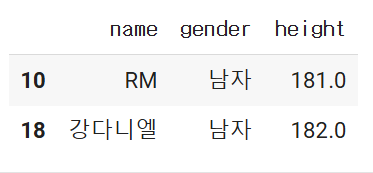
- 키가 170cm이상인 연예인의 이름, 성별, 키, 브랜드평판지수를 가져오는 df를 만드시오.
- 단 loc를 사용
df.loc[df.['height']>= 170], ['name', 'gender', 'height', 'brand']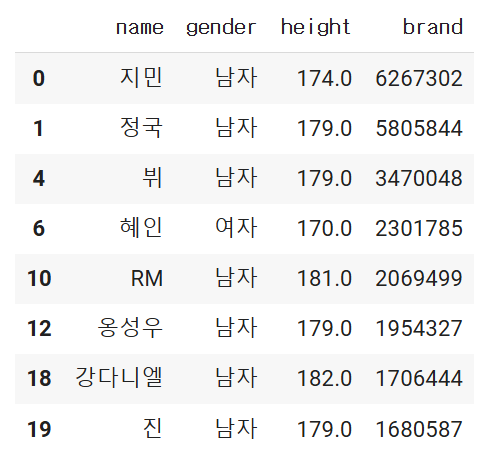

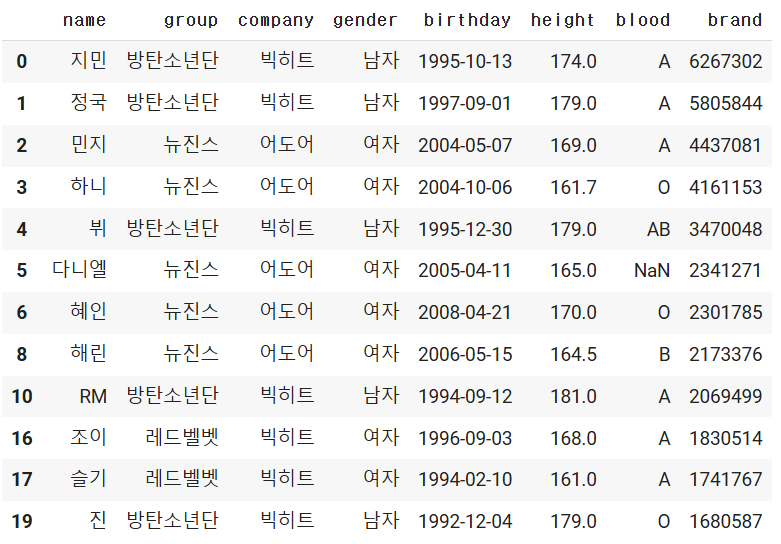
6. 결측값(Null, NaN)
- 비어있는 값, 판다스에서는NaN(Not a Number)로 표기 된 것은 모두 결측값으로 취급






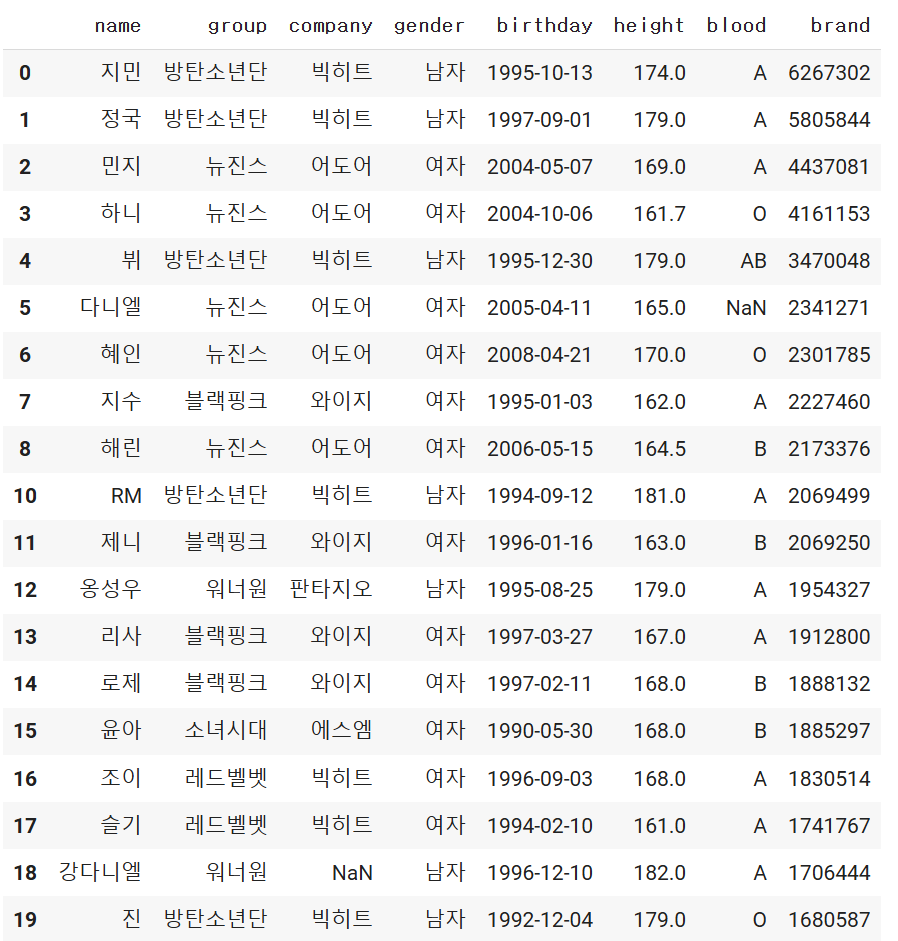
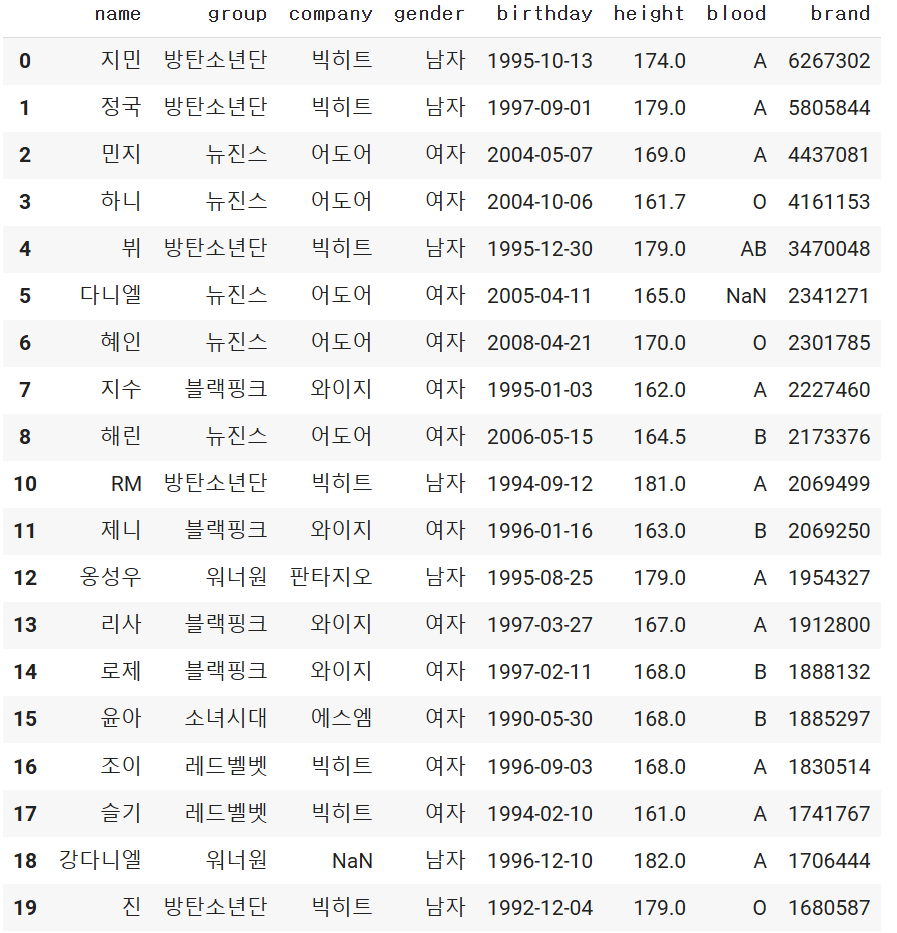
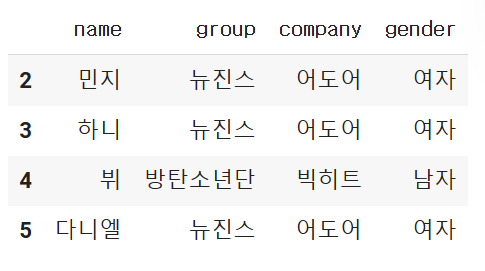
문제
- 회사가 존재하는 연예인의 이름, 회사, 그룹, 성별의 데이터를 출력
- 단, loc사용
df.loc[df.['company'].notnull(), ['name','company','group','gender']




저장되지않았기에 0이라고 저장되어있지 않습니다.
그래서 df_copy 매소드를 써서 하나 복사를 해서 데이터를 사용해보겠습니다.
df_copy = df.copy()
df_copyNaN값에 평균을 넣어보겠습니다
height = df_copy['height'].mean()
height평균값은
170.53684210526316입니다.
이제 fillna를 이용하여 키 부분에 평균값을 낸 데이터값을 넣어줍니다.
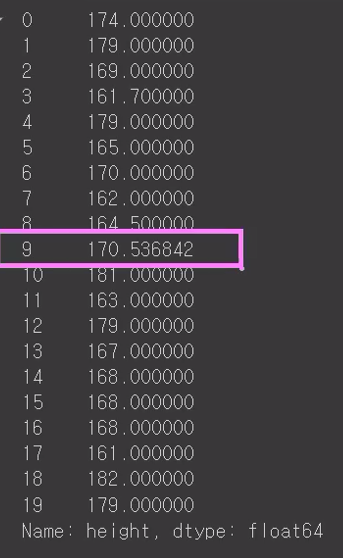
위 사진처럼 적용된걸 확인 할 수 있습니다.
확인 했으니 다시 원래대로 돌려놓도록 하겠습니다.
를 하면 다시 NaN으로 돌아갑니다.
이번에는 평균이 아니라 중위값을 넣어보도록 하겠습니다.
확인해보겠습니다.
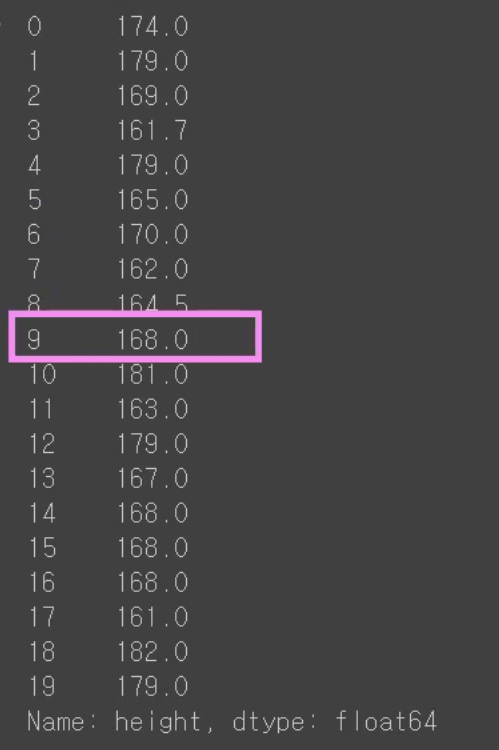
다시 원상복귀 시키겠습니다.
#dropna(): 결측값이 있는 행 또는 열을 제거. 결측값이 한개라도 있는 경우 삭제
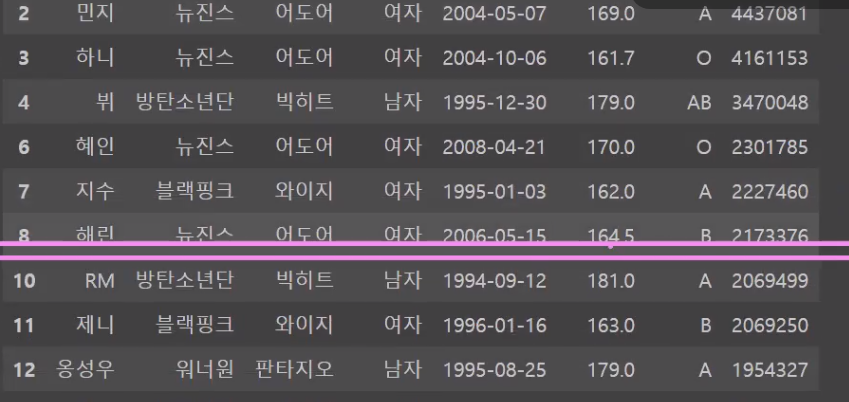
널값이었던 9번행 이 날라가는걸 볼 수 있습니다.
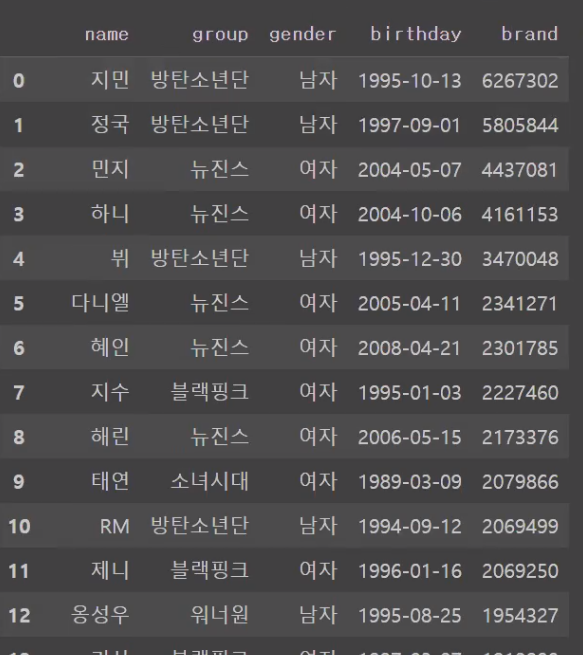
열이 많이 사라지는것을 볼 수있습니다. (많이 사용하는 편은 아닙니다)
7. 행, 열 추가 및 삭제하기
- 행을 추가할 때 dict형태의 데이터를 만들고 append() 매소드를 사용하여 데이터를 추가해보자
- ignore_index=True 옵션을 추가해야 에러가 발생하지 않음
#김사과 데이터 합침
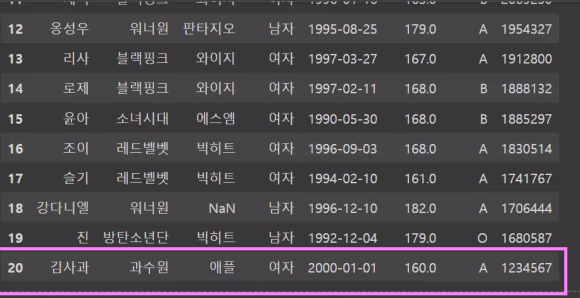
문제
- nation이라는 열을 추가하고, nation에 모든 데이터는 '대한민국'이라고 저장
- 단, '김사과'님의 국적을 '미국'으로 변경하고 loc를 사용하여 출력

맨 오른쪽에 대한민국 이라는 nation이 추가되었습니다.

이렇게 하면 20번 데이터가 사라져있을거고 다시 출력하면 저장한것이 아니기에 다시 보일겁니다.
# 열 여러개 지우기
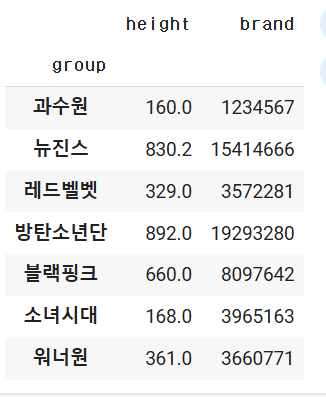
8.통계함수
9. 그룹
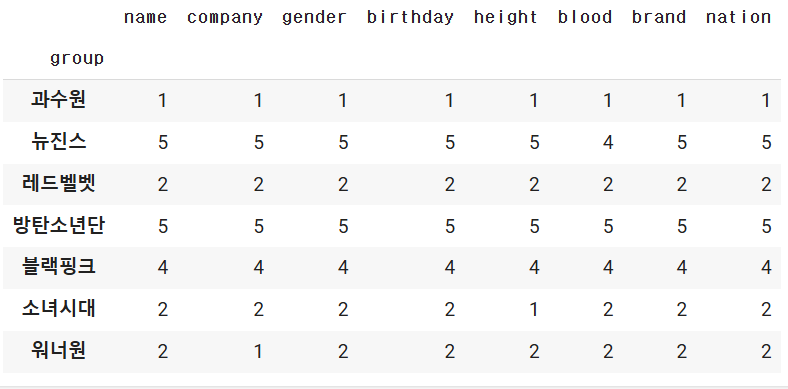
에러발생
▶에러나는 이유 :: 모든것들이 숫자가 아니기 떄문에 평균치를 낼 수 없습니다.
이런 오류를 해결하기 위한 매소드는 numeric_only=True를 사용하면 됩니다.
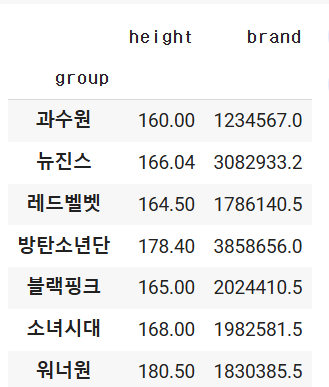
df.groupby('group').sum(numeric_only=True)
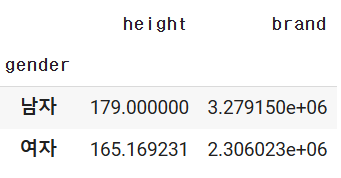
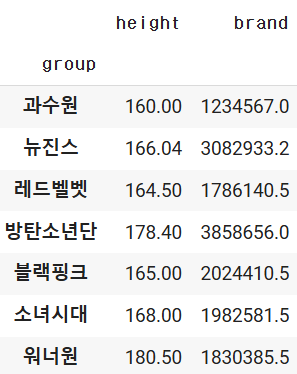
문제
- 혈액형별로 그룹을 맺고, 성별로 또 그룹을 나눈 후 키의 평균값에 대한 데이터를 출력
df.groupby(['blood','gender'])['height'].mean(numeric_only=True)

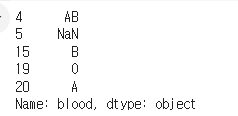
10.중복값 제거하기


중복되는 숫자를 제외하고 가장 처음에나온 A형,O형 등을 보여줍니다.



'AI > 머신러닝' 카테고리의 다른 글
| [ML] 아이리스 데이터셋(Iris DataSet) (1) | 2024.07.01 |
|---|---|
| [Python] 판다스(pandas) 데이터 프레임 합치기,산술연산, 원핫인코딩 등 (1) | 2024.06.18 |
| [Python] 넘파이, 행렬, 정렬 (2) | 2024.06.13 |
| [Python] Streamlit으로 초간단 번역 서비스만들기 (1) | 2024.06.09 |
| 데이터베이스와 MongoDB (0) | 2024.06.06 |



