파이썬을 사용하게되면 믿고 쓰게되는 모듈이 몇가지 있는데 그 중 가장 많이쓰이는 것이 넘파이입니다.
구글코랩은 보통 많이 쓰여있어서 설치되어있지만 파이참이나 주피터를 사용할 때에는 따로 설치해주어야 합니다.
1. 넘파이(Numpy)
- 파이썬에서 사용되는 과학 및 수학 연산을 위한 강력한 라이브러리
- 주로 다차원 배열을 다루는 데에 특화되어 있어, 데이터 분석, 머신러닝, 과학 계산 등 다양한 분야에서 널리 사용 됩니다.
- 넘파이 배열(ndarray / 앤디어레이) 는 데이터를 담는 자료구조입니다
자료구조는 전에배웠던 리스트, 튜플, 딕셔너리,세트=(컬렉션) 가있습니다.
앤디어레에이는 리스트와 비슷하지만 속도가 매우빠르고 사용빈도도 굉장히 높습니다.
- 넘파이 배열은 C언어로 구현되어 있습니다.
- 넘파이 배열은 큰 데이터셋에서 수치 연산을 수행할 때 뛰어난 성능을 보이며, 메모리 사용을 최적화시키고 효율적으로 관리할 수 있습니다.
2. 넘파이의 주요 특징과 기능
2-1. 다차원 배열 (N-dimensional array)
- 넘파이의 핵심은 다차원 배열 ndarry
- ndarray는 동일한 자료형을 가지는 원소들로 이루어져있음
▷저장할때 같은 데이터타입만 저장할 수 있습니다
▷ 예를들어 숫자만 저장하면 숫자만, 문자만 저장하면 문자만 저장할 수 있습니다
▷ 출력하면 2차원으로 출력되는걸 확인할 수 있습니다
예시 ) [[1,2,3]
[4,5,6]]
#1차원
#2차원 /대괄호 2개
#임포트
별명을np라고 함
#타입, 출력 확인
2-2. 리스트와 ndarray의 변환
- 나중에 데이터를 구하고 머신러닝, 딥러닝 모델에 넣으려고 하면 데이터프레임 / ndarry로 집어 넣게 되어있습니다.
리스트로 되어있던걸 ndarray로 변환할때가 굉장히 많고, 파이썬의 함수나 다른 프로금의 파라미터를 넣게되는데 이런 경우에는 ndarray로 넣게되면 에러가 떠서 ndarry로 넣어야하기에 리스트와 ndarray를 변환하는건 정확하게 숙지하고 자유자재로 쓸 수 있어야할것같습니다.
#리스트 -> ndarray
# ndarray -> 리스트
- tolist매소드 사용하면 ndarray를 list로 변경할 수 있습니다.
to list 를 합쳐서 사용하는듯..
2-3. ndarray의 데이터 타입
- 넘파이의 ndarray는 동일한 자료형을 가지는 원소들로 이루어져 있습니다
하나의 넘파이안에는 같은 타입만 들어갈 수 있다는 이야기 입니다.
- 다양한 데이터 타입을 지원하기는 합니다.
여러가지 타입으로 ndarray를 만들 수 있다는 이야기 입니다.
데이터타입을 정확하게 몰라서 한번 찾아본 결과
(작은 타입 ---------------->큰타입)
bool < int < float < str < object 입니다.
#확인해보기
list는 다양한 자료형을 넣어서 저장할 수 있는 특징이 있습니다.
정수 실수 문자형, bool, 문자열로 이루어진 list1도 잘 저장되는것을 확인할 수 있습니다.
#ndarray 타입 확인하기
#ndarray 요소중 가장 큰 데이터값으로 변경된 현상(1)
정수 < 실수
#ndarray 요소중 가장 큰 데이터값으로 변경된 현상(2)
bool은 가장 작은 요소 타입이므로 정수 < 실수니까 실수로 변경됨
True=1 , Flase = 0 이기때문에 1.0 / 0으로 변경되는것을 확인할 수 있습니다.
#ndarray 요소중 가장 큰 데이터값으로 변경된 현상(3)
'1'을 str로 묶었습니다.
str이 가장 크기에 print를 해보면 모두 ' ' 으로 따옴표가 붙습니다.
#억지로 형 변환을 시키는 방법
dtype을 사용해서 변경할 수 있습니다.
#모든 데이터 타입을 int로 변경
#모든타입을 int로 변경
'1'이라는 str가 있고 그보다 작은 int로 해도 int로 출력되는 이유는 '1'의 따옴표 를 없애면 int의 형태로 표현할 수 있기때문입니다. 예측되는 숫자라면 바뀝니다
'일'이라고 하면 에러가 납니다.
2-4. ndarray의 인덱싱과 슬라이싱
ndarray의 속성중 shape라는 속성이 있는데
shape : 튜플형태로 차원을 알려줍니다.
#shape 확인
shape를 찍게 되면 차원을 알 수 있습니다.
지금 데이터가 5개가 있어서 (5,)으로 표현됩니다.
단 1차원이라서 데이터가 1개고 튜플 특징중 데이터가 하나만있을때에는 마지막에 , 를 찍어줘야하기에
값은 (5,) 로 표현됩니다.
#인트
#튜플에 데이터 1개다 라고 생각함
#인덱싱
인덱싱은 차원이 축소됩니다.(한 단계 내려간다)
그래서 따옴표가 없이 별도로 데이터가 하나씩 사라져서 나옵니다.
#슬라이싱
슬라이싱의 차원은 변화가 없습니다. 그래서 대괄호가 유지되어있습니다.
#2차원 배열
3행 4열이라서 (3,4)로 표현이 됩니다.
나오는 순서는 (행,열) 로 됩니다.
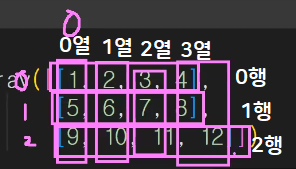
#2차원 배열인덱싱중 행 가져오기
#0행 가져오기(정석)
#윗줄 단축형
#더 단축형
#2차원 배열인덱싱중 열 가져오기
- 열 가져오는 방법은 1개밖에 없음
-뒤에값은 없어도 되지만 앞에 값은 있어야하고, 아예 0으로 써버리면 행이되어버리기때문에
한 가지 방법밖에없다.
모든 행은 다 가져오되, 0열만 가져와라 라는 코드입니다.
여기서 궁금한 점은 인덱싱도 아닌데 왜 , 이 사라졌을까 가 궁금했습니다.
이유는 Numpy의 출력형식 때문이고 Numpy는 배열을 보다 쉽게 읽기 쉽게 표시하기 위해서 쉼표 없이 요소를 출력한다는 점을 배웠습니다.
ndarray의 출력 형식은 다음과 같은 규칙을 따릅니다:
- 각 행은 한 줄에 출력됩니다.
- 행 사이에는 줄바꿈이 들어갑니다.
- 요소들 사이에는 쉼표가 없고, 대신 공백으로 구분됩니다.
Numpy의 배열을 쉼표로 구분된 형식으로 출력하려면 배열을 리스트로 변환해야합니다.
print(ndarr2d.tolist())#출력 값
[[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]]
2-5. Fancy Indexing
- 정수 배열이나 불리언 배열을 사용하여 배열의 일부를 선택하는 방법
- 여러 개의 요소를 한 번에 선택하거나 조건에 맞게 선택할 수 있음
#Fancy Indexing
해당 번호에 대한 데이터를 뽑아올 수 있습니다.
#2차원 Fancy Indexing
#print된 값
array([[1, 2, 3, 4],
[5, 6, 7, 8]])0,1 행을 다 가져오고 열은 아무거나 다 가져오기
2-6. Boolean Indexing
-불리언 값으로 이루어진 배열을 사용하여 조건을 충족하는 원소만 선택하는 방법
-True인 값이 프린트 되게 됩니다.
-중요한것은 갯수가 맞아야 합니다.
#Boolean Indexing
#print된 값
array(['😊', '😍', '😒'], dtype='<U1')
#Boolean Indexing(2차. 연산자 활용)
#print된 값
array([ 8, 9, 10, 11, 12])
3. 행렬 연산 (vision에서도 100%필요)
-넘파이에서는 다차원 배열인 ndarray를 사용하여 행렬 연산을 수행합니다.
-행렬 연산은 선형 대수와 관련이 깊어 데이터 과학, 머신러닝, 통계 등 다양한 분야에서 사용됩니다.
-행렬 연산의 기본은 shape가 무조건 같아야 합니다. (각 포지션끼리 플러스가 되기때문에)
#행렬 덧셈
#print된 값
array([[4, 6, 8],
[3, 5, 7]])#행렬 뺼셈
#print된 값
array([[-2, -2, -2],
[ 1, 1, 1]])
#행렬 원소별 곱셈
#print된 값
array([[ 3, 8, 15],
[ 2, 6, 12]])
#행렬 원소별 나눗셈
#print된 값
array([[0.33333333, 0.5 , 0.6 ],
[2. , 1.5 , 1.33333333]])
#행렬 원소별 곱셈
#print된 값
array([[ 3, 8, 15],
[ 2, 6, 12]])#행렬곱(matrix murtiplication)
-행렬곱을 사용하는 상황 : 데이터를 가지고예측하거나, 구별하거나, 영상처리를 할 때 그 값들이 비슷한지 판단할때 사용합니다. 그 이유는 모든 데이터 연산에서 머신러닝과 딥러닝은 방정식 연산으로 이루어져있습니다.
선형,곡선으로 사용하는 방정식을 많이 쓰이게 되는데 그 떄 선형 변환을 표현하고 계산하는 도구로 사용합니다.
행렬이 공간을 다른 공간으로 변환하는 작업을 할 때 사용합니다.
-선형 연립방정식을 행렬 형태로 나타내고 이를 풀기 위해 행렬 곱을 사용합니다.
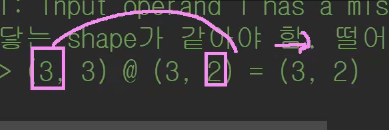
-조건 : 맞닿는 shape가 같아야 합니다. 떨어져있는 shape가 결과 행렬이 됩니다.
예를들어 (2,3) @ (2,3) 이 되면 맞닿지 행렬이 같지 않으니 안됩니다.
(3,3)@(3,2) 이런건 되겠죠 결과 값은 (3,2)가 됩니다.
#print된 값
#print된 값
#ndarry로 곱하기
#print된 값
array([[22, 28],
[22, 28],
[31, 40]])#전치행렬
- 기존 전치행렬의 행과 열을 바꾼 새로운 행렬
- T를 사용합니다.
#ndarr1 // print된 값
[[1 2 3]
[2 3 4]]
#ndarr1.T // print된 값
[[1 2]
[2 3]
[3 4]]
#역행렬
- 주어진 정사각 행렬에 대한 곱셈 연산으로 단위 행렬을 얻을 수 있는 행렬
- 단위행렬 : 주 대각선의 원소가 모두 1이고 나머지 원소가 모두 0인 정사각행 행렬
- np.linalg.inv(arr)이 역행렬을 구하는 함수입니다.


#np.linalg.inv // print된 값
[[-2. 1. ]
[ 1.5 -0.5]]#arr @ np.linalg.inv // print된 값
[[1.0000000e+00 0.0000000e+00]
[8.8817842e-16 1.0000000e+00]]
4. 순차적인 값 생성
#반복문 넣어보기
#반환되는 값은 ndarray
5. 정렬
-리스트에서 sort매소드 사용, inplace로 하면 값이 저장됨
-sort매소드를 사용할 수 없는 튜플같은건 sorted 함수를 사용하기도 했음
이것은 inplace연산을 하지 못하기때문에 다시 변수에 담아주어야 함
#정렬
#오름차순 정렬
array([ 1, 10, 5, 7, 2, 4, 3, 6, 8, 9])inplace연산이 되지 않음을 확인할 수 있습니다. 그러니 꼭 저장을 해주어야한다는것을 알 수 있습니다.
#내림차순 정렬
-reverse=True는 사용할 수 없기에 역순으로 돌리는 -1을 적어주게 됩니다.(슬라이싱 역순잡는 방법)
#출력 값
array([10, 9, 8, 7, 6, 5, 4, 3, 2, 1])
#2차원데이
#출력 값
(3, 4)
#2차원 데이터 정렬(행)
-axis=0은 행정렬을 의미합니다.
#출력 값
array([[ 3, 1, 4, 2],
[ 5, 6, 7, 8],
[11, 10, 12, 9]])
#2차원 데이터 정렬(열)
-axis=1은 행정렬을 의미합니다.
(각 행끼리의 열정렬이라고 생각하면 됩니다.)
#출력
array([[ 9, 10, 11, 12],
[ 1, 2, 3, 4],
[ 5, 6, 7, 8]])
#열정렬 내림차순
#출력
array([[12, 11, 10, 9],
[ 4, 3, 2, 1],
[ 8, 7, 6, 5]])
#열정렬(축의 마지막 방향)
np.sort(ndarr2d, axis=-1
-1은 점점 생기는 축의 마지막 방향입니다. 지금 2차원은 0번과 1번만 있으니까 -1하면 1이 되는거죠
그럼 열방향으로 정렬한것이랑 같은 값이 나옵니다.
-즉 -1은 축방향입니다.
#출력
array([[ 9, 10, 11, 12],
[ 1, 2, 3, 4],
[ 5, 6, 7, 8]])'AI 컴퓨터 비전프로젝트' 카테고리의 다른 글
| [Python] 판다스(pandas) 데이터 프레임 합치기,산술연산, 원핫인코딩 등 (1) | 2024.06.18 |
|---|---|
| [Python] 판다스(pandas)를 이용한 데이터 다루기 (0) | 2024.06.14 |
| [Python] Streamlit으로 초간단 번역 서비스만들기 (1) | 2024.06.09 |
| [Python] 동기와 비동기 처리 및 FastAPI 사용법 (1) | 2024.06.07 |
| AI 컴퓨터 비전 프로젝트_2개월차_데이터베이스와 MongoDB (0) | 2024.06.06 |



