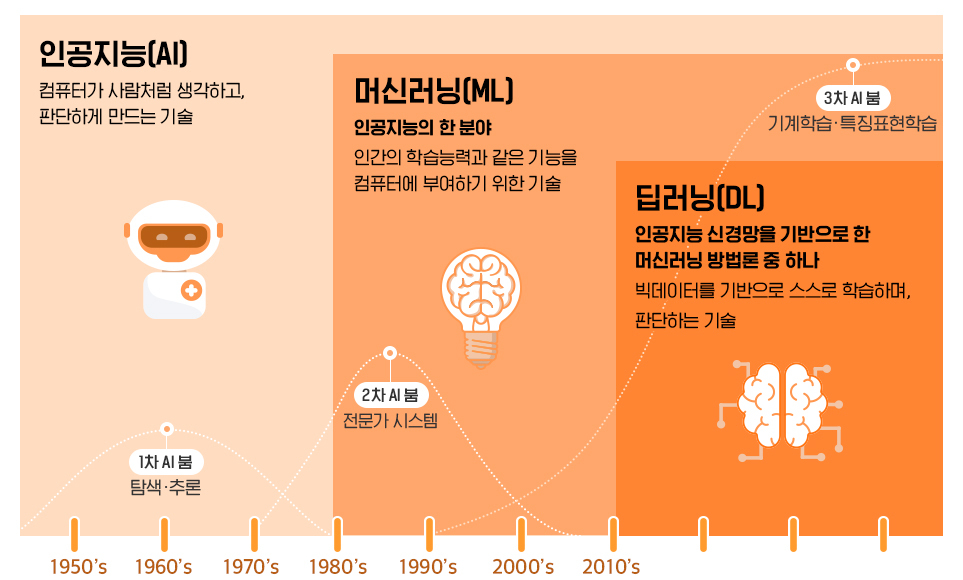
1. 머신러닝(Machine Learning)
- 인공지능: 인공(Artificial) + 지능(Interlligence)
- 1956년 : 인간의 지능을 복제하거나 능가할 수 있는 지능형 기계를 만들고자하는 컴퓨터 과학 분야
- 개발자에 의한 인공지능, 데이터에 의한 인공지능
- 지금 내가 공부하는건 데이터에 의한 인공지능
- 이것이 바로 머신러닝이라고 합니다.
- 머신러닝 : 데이터를 기반으로 한 학습(learning)하는 기계(machine)
- 1997년 : 기계가 기존 데이터에서 학습하고 해당 데이터를 개선하여 의사결정 또는 예측을 할 수 있도록 하는 ai의 하위 집합.
- 딥러닝 : 깊은(deep) 신경만 구조의 머신러닝
- 2017년 신경망 레이어를 사용하여 데이터를 처리하고 결정을 내리는 기계 학습 기술
- Generative AI
- 2021년 프롬포트나 기존 데이터를 기반으로 새로운 문서, 시각, 청각, 컨텐츠를 생성하는 기술
- ChatGPT
- 2022: GPT(Generative Pre-trained Transformer) 시리즈를 기반으로 하는 OPENAI가 개발한 대화형 Ai모델
- 2022: GPT(Generative Pre-trained Transformer) 시리즈를 기반으로 하는 OPENAI가 개발한 대화형 Ai모델
2. 머신러닝의 정의
- 배경: 데이터를 대량으로 수집 처리할 수 있는 환경이 갖춰짐으로 머신러닝으로 할 수 있는 일들이 많아짐
- 머신러닝은 데이터로부터 특징이 패턴을 찾아내는 것이기 때문에 데이터가 가장 중요함
- 인공지능의 하나 분야로 컴퓨터가 학습할 수 있도록 알고리즘과 기술을 개발하는 분야
- "무엇(x:데이터)으로 무엇(y)을 예측하고 싶다"의 f(함수)를 찾아내는 것
- x:입력변수(독립변수), y:출력변수(종속변수), f모형(머신러닝 알고리즘)
3.머신러닝으로 할 수 있는 것
3-1. 회귀(Regression)
- 시계열(시간적인 변화를 연속적으로 관측한 데이터)데이터 같은 연속된 데이터를 취급할 때 사용하는 기법
- 예측하는 용도로 많이 사용합니다.
3-2. 분류(Classification)
- 주어진 데이터를 클래스별로 구별해 내는 과정으로 데이터와 데이터의 레이블값을 학습시키고 어느 범주에 속한 데이터인지 판단
- 예) 스팸메일인지 아닌지구별해주는 시스템을 개발
3-3. 클러스터링(Clustering)
- 분류와 비슷하지만 데이터에 레이블(정답)이 없음
- 유사한 속성들을 갖는 데이터를 일정한 수의 군집으로 그룹핑하는 비지도 학습
- 예) sns데이터를 통해 소셜 및 사회 이슈를 파악
4. 학습
4-1. 지도 학습(Supervised Learning)
- 문제와 정답을 모두 학습시켜 예측 또는 분류하는 문제
- y=f(x)에 대하여 입력변수(x)와 출력변수(y)의 관계에 대하여 모델링 하는 것
- y(종속변수)에 대하여 예측 또는 분류하는 문제
4-2. 비지도 학습(Unspervised Learning)
- 출력 변수(y)가 존재하지않고, 입력 변수(x)간의 관계에 대해 모델링 하는 것
- 군집분석 : 유사한 데이터끼리 그룹화
4-3. 자기지도 학습(Self-Supervised Learning)
- 데이터자체에서 스스로 레이블을 생성하여 학습에 이용하는 방법
- 다량의 Lable이 없는 Raw Data로부터 데이터 부분들의 관계를 통해 Lable을 자동으로 생성하여 지도 학습에 이용하는 비지도 학습 기법
- gpt,bert모델
4-4.강화 학습(Reinforcement Learning)
- 결정을 순차적으로 내려야 하는 문제에 적용
- 레이블이 있는 데이터를 통해서 가중치와 편향을 학습하는 것과 비슷하게 보상이라는 개념을 사용하여 가중치와 편향을 학습하는 것
'데이터 분석 및 시각화' 카테고리의 다른 글
| [ML] 사이킷런(Scikit-learn) (0) | 2024.06.30 |
|---|---|
| [데이터 시각화] 떡볶이 프렌차이즈의 입점전략은 바로 이것. (0) | 2024.06.29 |
| [데이터 시각화] 서울시 따릉이 API를 이용한 실시간 잔여 자전거 대수 확인하기 (0) | 2024.06.27 |
| [데이터 시각화] 전국 도시공원 데이터 활용 (0) | 2024.06.23 |
| [seaborn] 상권별 업종 밀집 통계 데이터(2) (0) | 2024.06.22 |



