호호 강사님이 아주 재미있는 썰을 말씀해주셨다.
떡볶이집는 파리바게트 근처에 오픈해야 장사가 잘 된다는 썰인데 떡볶이를 그닥 좋아하진 않지만
이런 썰이 진짜인지 확인하는것을 좋아하는편.. 꽤 흥미로운 주제였다.
그래서 정말 열심히 들으려고 노력했지만 오우 이번은 아주 어려웠던.......
그래도 프로젝트 기록을 하겠습니다.
import pandas as pd
df = pd.read_csv('소상공인시장진흥공단_상가(상권)정보_서울_202303.csv')
df
df.info()
서울시 값이고 대부분이 null값이 없이 잘 들어가있는걸 확인할 수 있습니다.
떡볶이집 선택하기
shop변수에 들어갈 떡볶이집 5곳을 선택했습니다. 신전, 죠스, 엽떡, 청년다방, 감탄떡볶이를 구성했습니다.
shop = ['신전떡볶이', '죠스떡볶이', '엽기떡볶이', '청년다방', '감탄떡볶이']
파리바게트(파리바게뜨)데이터 필터링
파리바게트 라고 하는 사장님, 파리바게뜨라고 하는 사장님이 있으니 contains() 매소드를
사용해서 True,False를 반환하게 만들어줍니다.
data = df['상호명'].str.contains('파리바게트|파리바게뜨')|(or)표시를 해서 파리바게트, 파리브게뜨를 모두 걸러줄 수 있게 만듭니다.
df_paris = df.loc[data, ['상가업소번호', '상호명', '경도', '위도']].copy()
df_paris
loc를 이용해서 true인 값들(파리바게트, 파리바게뜨)만 가져오기로 합니다. 상가업소번호, 상호명, 경도, 위도,
를 만들어줍니다.
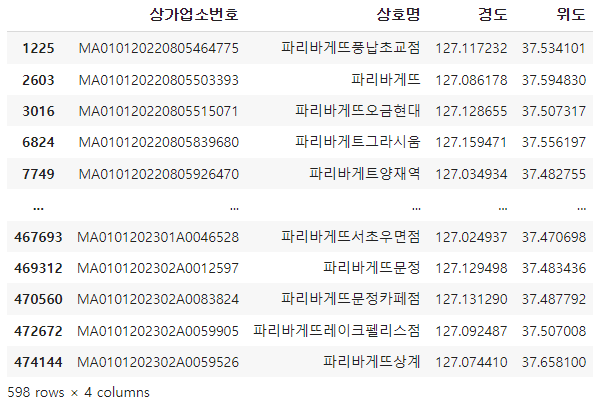
총 598개가 있다는것을 알 수 있습니다.
그렇지만 인덱스가 좀 중구난방이라서 정리좀 해주겠습니다.
df_paris = df_paris.set_axis(['업소번호', '업소상호명', '업소경도', '업소위도'], axis=1).reset_index(drop=True)
df_paris
변경되었습니다.
떡볶이 프렌차이즈 데이터 필터링
원본데이터말고 copy한 데이터를 사용하겠습니다.
df_shop = df.copy()
df_shop['상호명'] = df_shop['상호명'].str.extract('({})'.format('|'.join(shop)))
df_shop['상호명']중괄호에는 .format()이 들어가게 됩니다. 또 format에는 .join을 이용해서 shop의 값을 넣게 됩니다.
그렇게 되면 신전떡볶이|(or)죠스떡볶이|(or)엽기떡볶이|(or)청년다방|(or)감탄떡볶이가 됩니다.

떡볶이집인애들은True, 아니면NaN이 됩니다.
여기서 df_shop을 보면 상호명에 NaN인것들이 굉장히 많겠죠?
그러면 불필요한 데이터들이 많아지니까! 내가 원하는 컬럼들만 갖고오는것을 한 줄 코드로 만들어봤습니다.
df_shop = df_shop.dropna(subset=['상호명']).iloc[:, [0, 1, 14, 37, 38]].reset_index(drop=True)
df_shop1) dropna(subset['상호명']) == 상호명에 NaN이 있으면 날려라
2) iloc[:, [0, 1, 14, 37, 38]] == 상가업소번호, 상호명, 시군구명, 경도, 위도 를 살릴겁니다.
3) .reset_index(drop=True) == 전에있던 인덱스는 drop하고 인덱스를 새로생성시킴
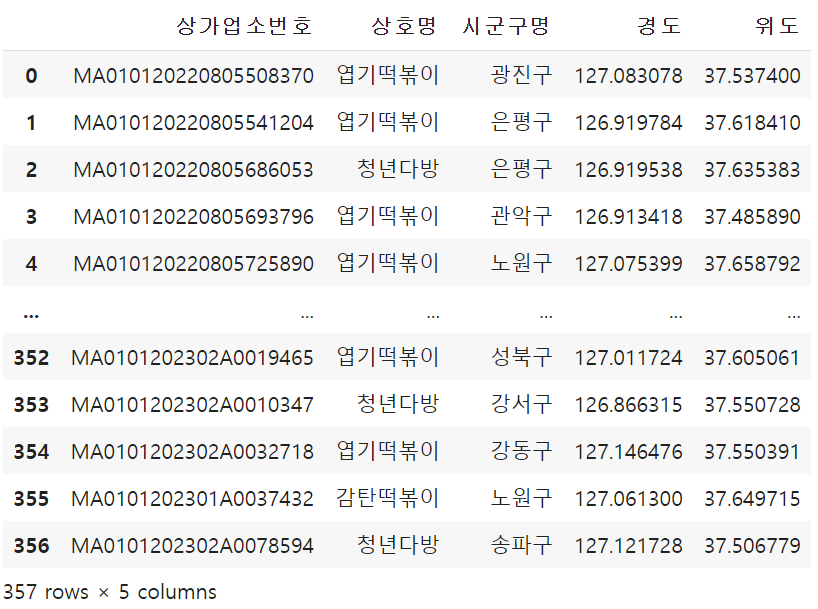
이러면 파리바게트지점 데이터1개, 프렌차이저 떡볶이집 데이터 2로 총 2개가 있습니다.
프로젝트 시작의 궁금했던것처럼 이 둘이 정말 가까운곳에 입점해있는지를 알기 위해서는
거리를 계산해주어야합니다.
그런데 속초 파바랑 서울 엽떡이랑 비교하면 안되겠죠?
그간 공부했던걸 활용해보면서 곱집합을 구해보려고 합니다.
곱집합은 merge할때 cross에서 했었어요 1:다 로 다 엮어보는방법이죠 :)
그리고 최단거리만 남겨두면 되겠죠!
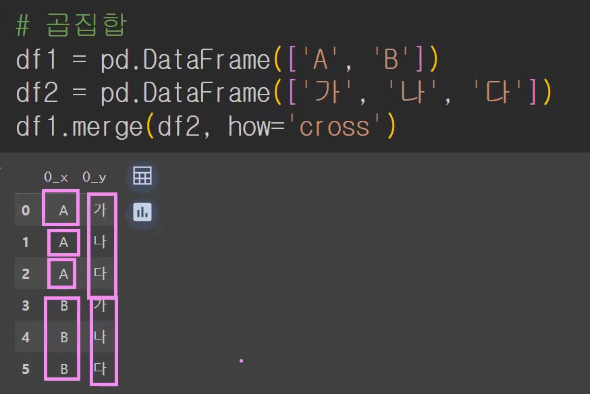
하버사인공식 (2:58~~~~~)
# 두 지점의 위도와경도를 입력하면 거리를 구해주는 모듈
!pip install haversine
파리에서 서울까지의 거리를 확인하기
from haversine import haversine
seoul = [37.541, 126.986]
paris = [48.8567, 2.3508]
print(haversine(seoul, paris, unit='km'))
#(8968.562580161477)
print(haversine(seoul, paris, unit='m'))
#(8968562.580161477)df_shop.shape
#(357, 5)
df_paris.shape
#(598, 4)
파리바게트와 떡볶이거리의 최소거리구하기
-merge이용함으로 곱집합이 됩니다.
df_cross = df_shop.merge(df_paris, how='cross')
df_cross
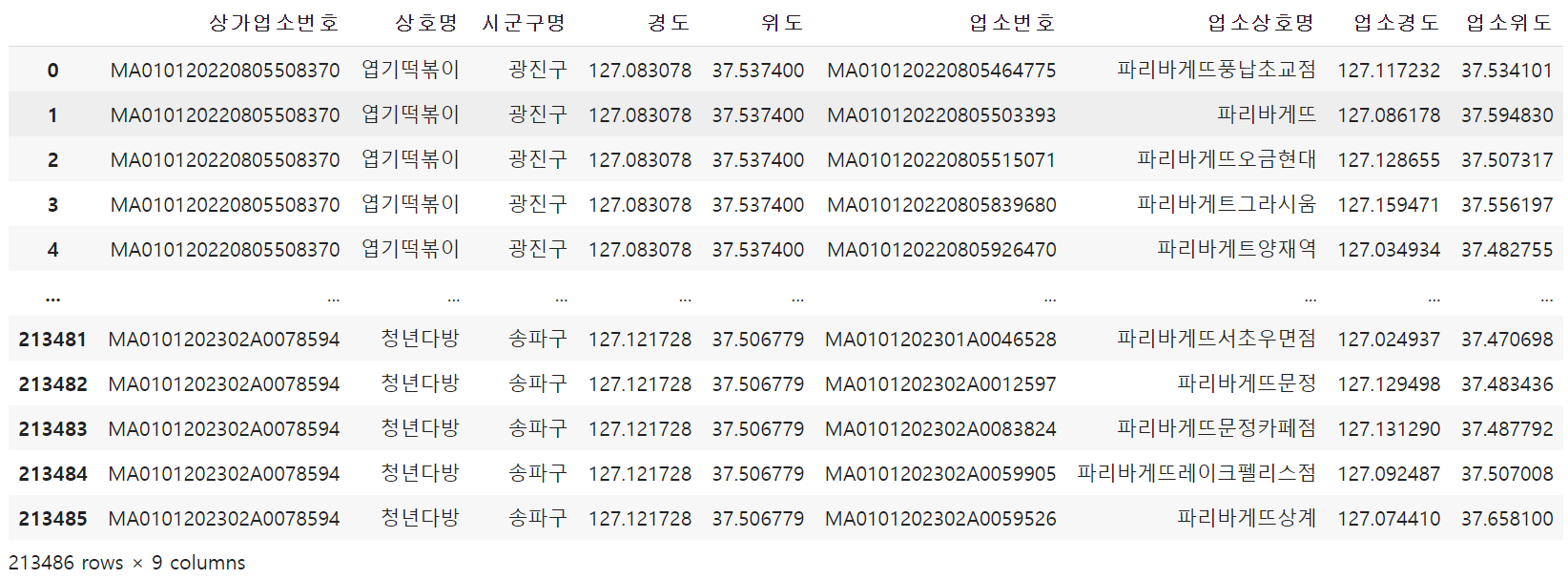
데이터를 357*598개를 cross를 하니 213486가 됩니다.
엽기떡볶이 1을 모든 파리바게트와 연결해보고 최소만남기는겁니다.
파생변수를 만들어서 거리 확인하기
-lambda를 사용하기
df_cross['거리'] = df_cross.apply(
lambda x: haversine([x['위도'], x['경도']],
[x['업소위도'], x['업소경도']],
unit='m'), axis=1)
df_cross위도경도, 다른좌표의 위도경도를 넘기면 계산이 됩니다.
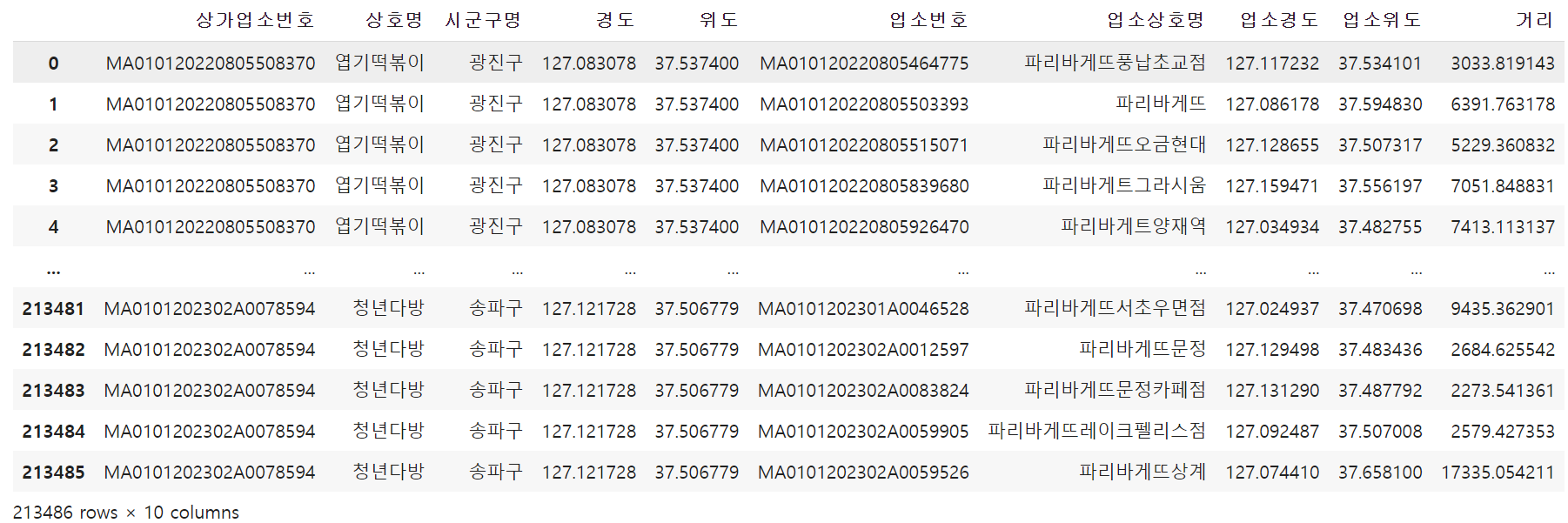
# 개별떡볶이 매장과 파리바게트와의 최소거리
df_dis = df_cross.groupby(['상가업소번호', '상호명'])['거리'].min().reset_index()
df_dis상가업소번호가 같으면 같은 매장입니다.

엽떡은 45m, 죠스323m, 등등 보면 최소거리가 정말 짧다는것을 확인할 수 있습니다.
각 프렌차이즈 별 파리바게트와의 평균 거리
df_dis.groupby('상호명')['거리'].mean()
파리바게트와 떡볶이들의 평균거리는 330미만으로 있다는것을 확인할 수 있습니다.
df_dis.groupby('상호명')['거리'].agg(['mean', 'count'])#agg():다중 집계작업을 간단하게 해주는 함수
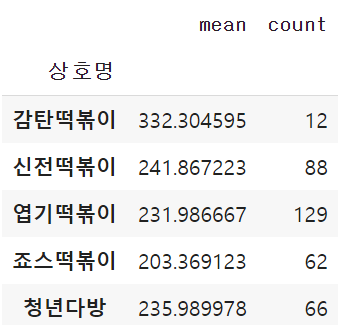
거리를 입력하면 프렌차이즈별 파리바게트와의
평균 거리와 매장개수를 출력하는 함수
def distance(x):
dis = df_dis['거리'] <= x
return df_dis[dis].groupby('상호명')['거리'].agg(['mean', 'count'])distance(50)
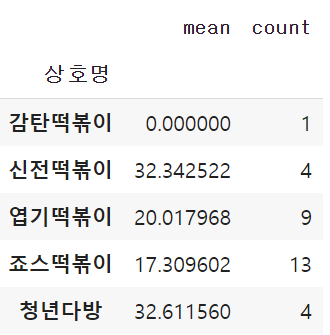
50m안에 있는 업체들은 감탄1개 신전4개 엽떡9개 죠스13개 청년다방4개 라는것을 확인할 수 있습니다.
고로!
어느정도의 입점유무를 확인하고 오픈할 수 있겠다 라는것을 확인할 수 있습니다.
파이썬 시각화 모듈이용하여 그래프 확인해보기
!pip install pandasecharts
df_100 = distance(100).reset_index()
df_100100m안쪽에있는 떡볶이 가게를 확인할 수 있습니다. 이 표를 시각화하도록 하겠습니다.
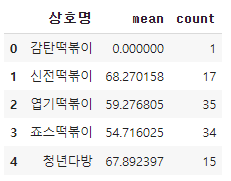
import IPython
from pandasecharts import echart판다스차트중에서 echart를 사용하겠습니다.
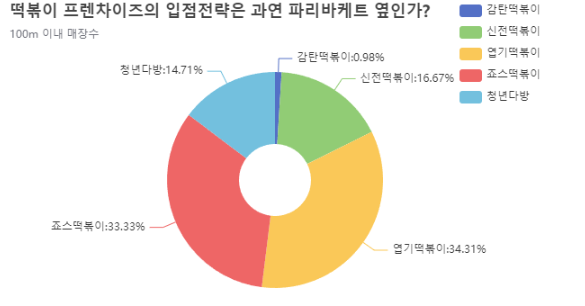
df_100.echart.pie(x='상호명', y='count', figsize=(600, 400),
radius=['20%', '60%'], label_opts={'position':'outer'},
title='떡볶이 프렌차이즈의 입점전략은 과연 파리바케트 옆인가?',
legend_opts={'pos_right':'0%', 'orient':'vertical'},
subtitle='100m 이내 매장수').render()
IPython.display.HTML(filename='render.html')
from pyecharts.charts import Timeline, GridTimeline과 Grid를 가지고 타임라인을 가지고옵니다.
타임라인은 100m입니다!
grid는
tl = Timeline({'width':'600px', 'height':'400px'})
pie1 = df_100.echart.pie(x='상호명', y='count', figsize=(600, 400),
radius=['20%', '60%'], label_opts={'position':'outer'},
title='떡볶이 프렌차이즈의 입점전략은 과연 파리바케트 옆인가?',
legend_opts={'pos_right':'0%', 'orient':'vertical'},
subtitle='100m 이내 매장수')
tl.add(pie1, '100m').render()
IPython.display.HTML(filename='render.html')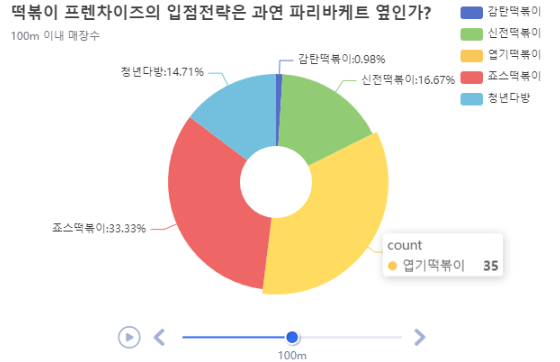
여기서 밑에 100m는 움직일 수 없습니다.
tl = Timeline({'width':'600px', 'height':'400px'})
for i in [1000, 100, 50, 30]:
df_d = distance(i).reset_index()
pie1 = df_d.echart.pie(x='상호명', y='count', figsize=(600, 400),
radius=['20%', '60%'], label_opts={'position':'outer'},
title='떡볶이 프렌차이즈의 입점전략은 과연 파리바케트 옆인가?',
legend_opts={'pos_right':'0%', 'orient':'vertical'},
subtitle='{}m 이내 매장수'.format(i))
tl.add(pie1, '{}m'.format(i)).render()
IPython.display.HTML(filename='render.html')
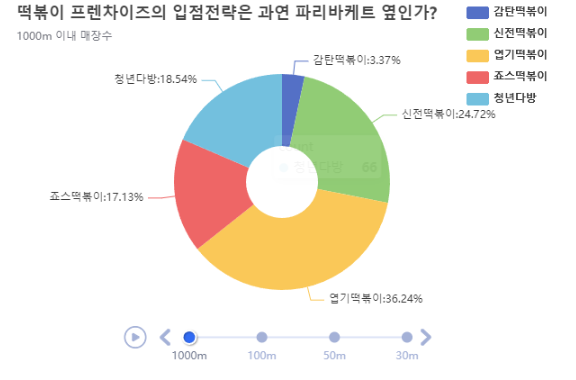
for i in 함수를 사용하여서 작성해서 시각화를 시킨 모습입니다.
이것같은경우에는
reder.html로 파일이 자동생성되어서 다운로드해서 파일을 다운받으면 html파일로 다운이가능하고
첨부할수도있습니다.
매소드 리뷰
| 매소드 | 설명 |
|
contains()
|
특정 문자열 포함 여부에따라서 True, False 를 반환
|
| .set_axis(['']) | 필드명 변경가능 |
| .reset_index | index를 다시 세팅 |
| .reset_index(drop=True) | 원래있던 인덱스를 날려버리고 새로운 인덱스 생성 |
| extract() | 특정 문자열을 포함하고 있으면 그 문자를 반환하고 포함하지 않으면 NaN으로 반환 |
| agg() | 다중 집계작업을 간단하게 해주는 함 |
'데이터 분석 및 시각화' 카테고리의 다른 글
| [ML] 의사 결정 나무(decision tree)_bike 데이터 활용 (2) | 2024.07.05 |
|---|---|
| [ML] 사이킷런(Scikit-learn) (0) | 2024.06.30 |
| [ML] 머신러닝(Machine Learning) (0) | 2024.06.28 |
| [데이터 시각화] 서울시 따릉이 API를 이용한 실시간 잔여 자전거 대수 확인하기 (0) | 2024.06.27 |
| [데이터 시각화] 전국 도시공원 데이터 활용 (0) | 2024.06.23 |



