이번에는 다양한 도시공원데이터들을 활용해서 얼마나 퍼져있는지 확인하려고 합니다
임포트해보겠습니다.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as snspark = pd.read_csv('전국도시공원표준데이터.csv', encoding='ms949')
park여기서 encoding='ms949'로 윈도우즈에 맞게 인코딩까지 해준 후 데이터를 뽑아봅니다.
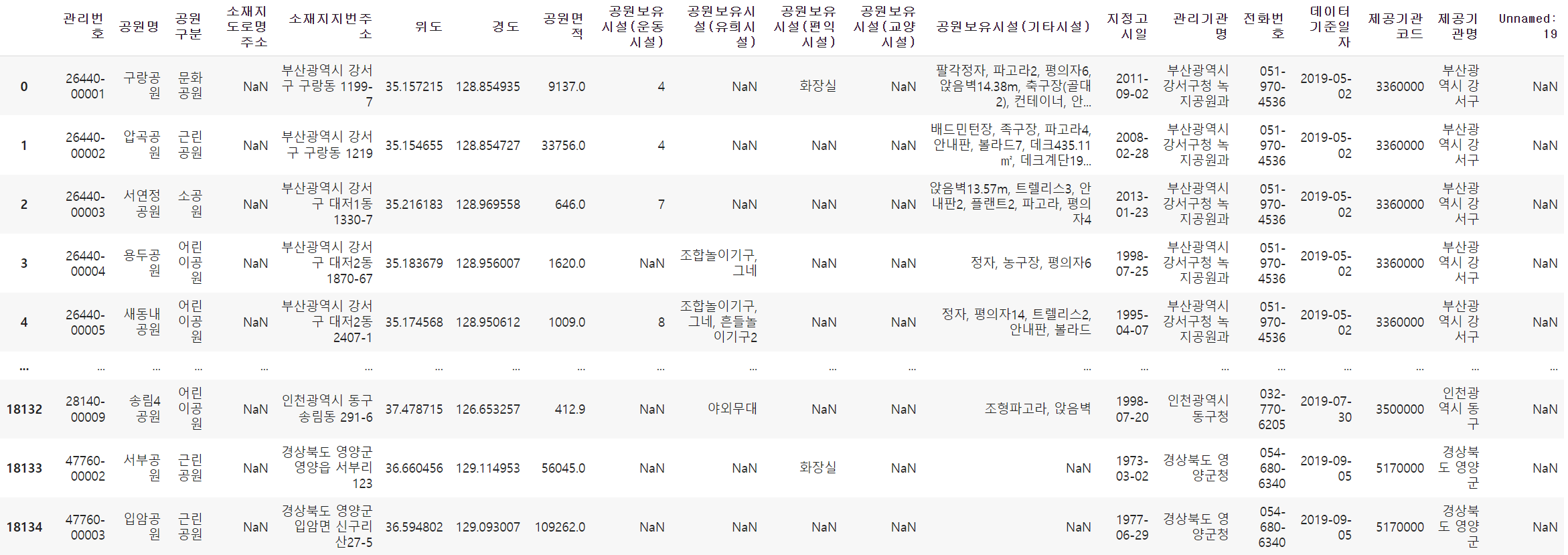
park.shape
#(18137, 20)이번에도 값들이 굉장히 많이있다는것을 볼 수 있습니다.
한글도 사용할 것이라 한글폰트도 설치 해줍니다.
#한글폰트 설치
!sudo apt-get install -y fonts-nanum
!sudo fc-cache -fv
!rm ~/.cache/matplotlib -rfpark 칼럼 확인
park.columnsIndex(['관리번호', '공원명', '공원구분', '소재지도로명주소', '소재지지번주소', '위도', '경도', '공원면적',
'공원보유시설(운동시설)', '공원보유시설(유희시설)', '공원보유시설(편익시설)', '공원보유시설(교양시설)',
'공원보유시설(기타시설)', '지정고시일', '관리기관명', '전화번호', '데이터기준일자', '제공기관코드', '제공기관명',
'Unnamed: 19'],
dtype='object')칼럼을 확인해보면 이렇게 많이 있는 것을 확인할 수 있고
여기서 제가 필요없다고 생각하는 칼럼들은 drop해보겠습니다.
park.drop(columns=['공원보유시설(운동시설)','공원보유시설(유희시설)','공원보유시설(편익시설)', '공원보유시설(교양시설)','공원보유시설(기타시설)',
'지정고시일','관리기관명','Unnamed: 19'], inplace=True)inplace=True를 적용함으로서 바로 저장까지 했습니다.
park.head()
필요없는 데이터들은 모두제거가 되고 그대로 바로 잘 적용된것을 확인할 수있습니다.
scatter표시하기
park.plot.scatter(x='경도', y='위도', figsize=(8,10), grid=True)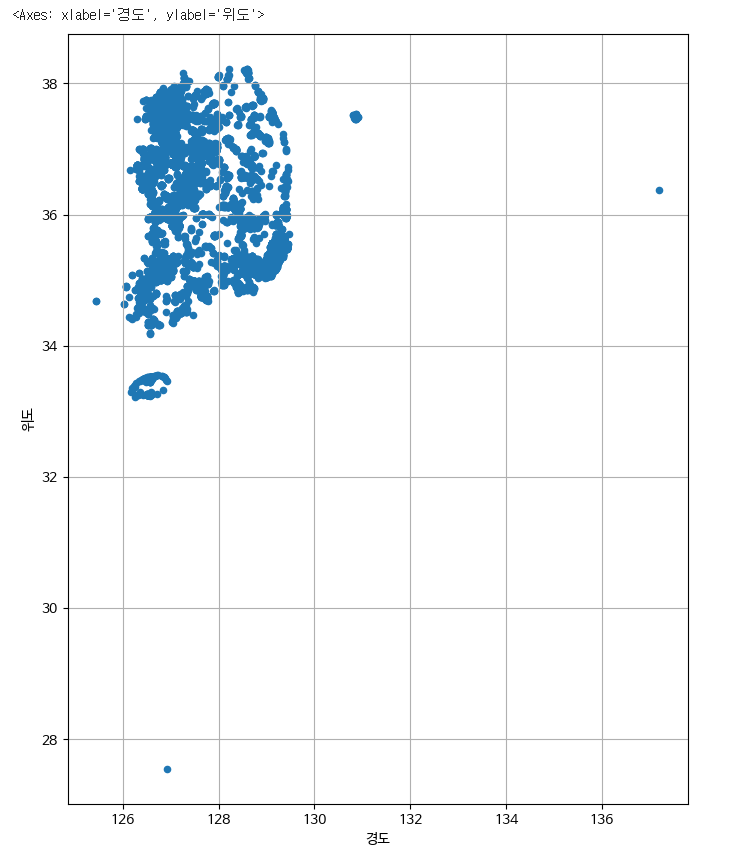
boxplot
- 데이터의 분포를 시각화하는데 유용
- 주로 데이터의 중앙값(중위수, median), 사분위수(Q1[25%], Q2[50%], Q3[75%], Q4[100%]), 이상치 등을 표현해줍니다.
- 상자 : Q1과 Q3 사이의 범위, 내부선(Q2, 중앙값)
- 수염 : 데이터의 최소값과 최대값. 아래수염(Q1 - 1.5*IQR), 위쪽 수염(Q3 + 1.5*IQR)
- IQR == Q3-Q1, 데이터의 변동성을 평가하는데 사용
- 수염을 벗어나는 값들은 이상치로 간주됨(확인이 필요, 일정하게 데이터가 연결되어있다면 이사치가 아닐 가능성이 높음)
sns.boxplot(y=park['위도'])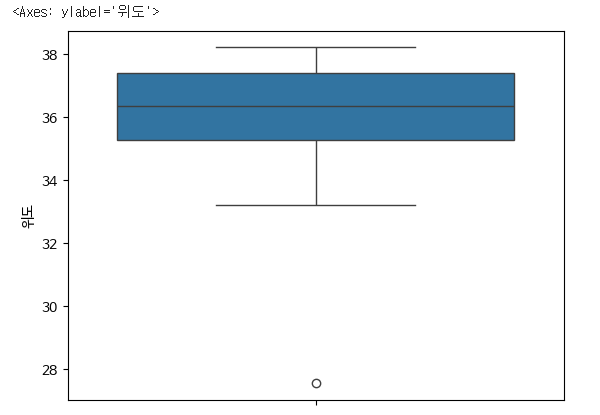
sns.boxplot(y=park['경도'])

위도와 경도의 이상치로 판별되는 데이터를 확인
park.loc[(park['위도']<32) | (park['경도']>132) ] #시리즈의 연산처리 |:or
이상치로 나오는것은 총 2개로 확인되고있습니다.
park = park.loc[(park['위도']>=32) & park['경도'] <= 132]
park.shape
#(18137,12)park.head()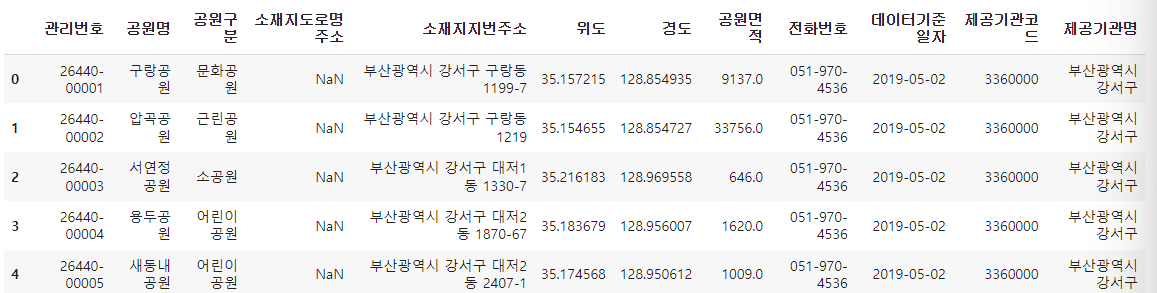
'소재지도로명주소'가 입력되지않고,
'소재지지번주소'만 입력된 데이터를 확인
park.loc[park['소재지도로명주소'].isnull() & park['소재지지번주소'].notnull()]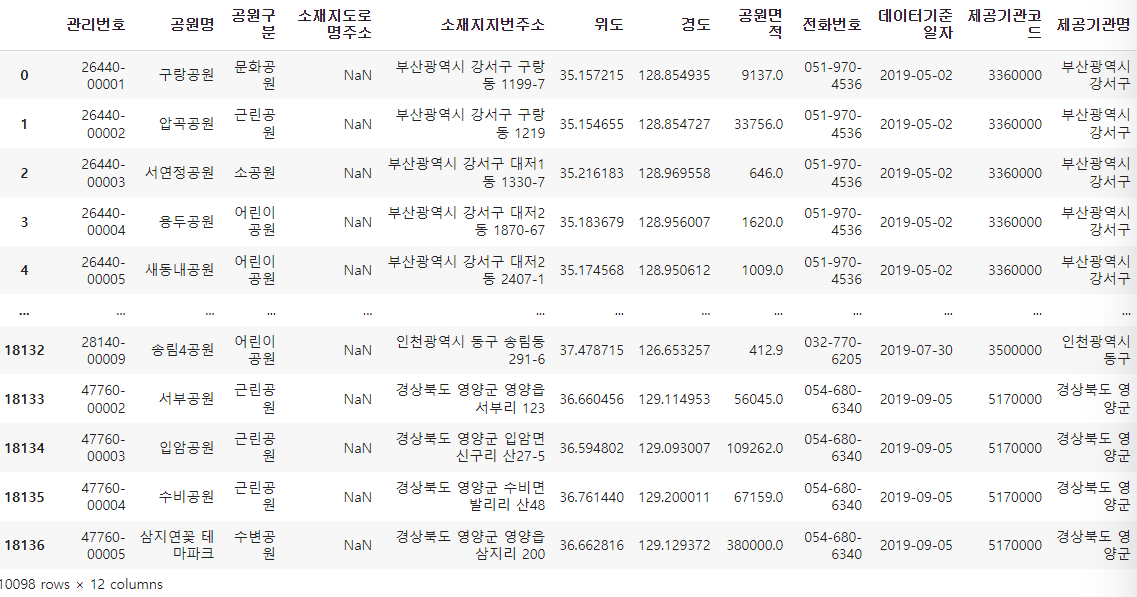
'소재지도로명주소'가 입력되지 않은데이터는 '소재지지번주소'로 대신 채우기
park['소재지도로명주소'].fillna(park['소재지지번주소'], inplace=True)
park.loc[park['소재지도로명주소'].isnull() & park['소재지지번주소'].notnull()]
'소재지도로명주소'에서 '시도'만 추출하여 '시도'파생변수만들기
park['소재지도로명주소'].str.split(' ') #[부산광역시, 강서구, 구랑동, 1199-7]
데이터프레임으로 데이터가 분리되고, 인덱싱, 슬라이싱이 가능해집니다.
park['소재지도로명주소'].str.split(' ', expand=True)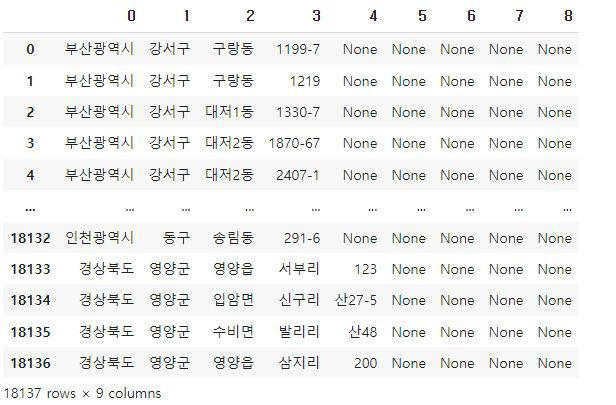
park['시도'] = park['소재지도로명주소'].str.split(' ', expand=True)[0]
park.head()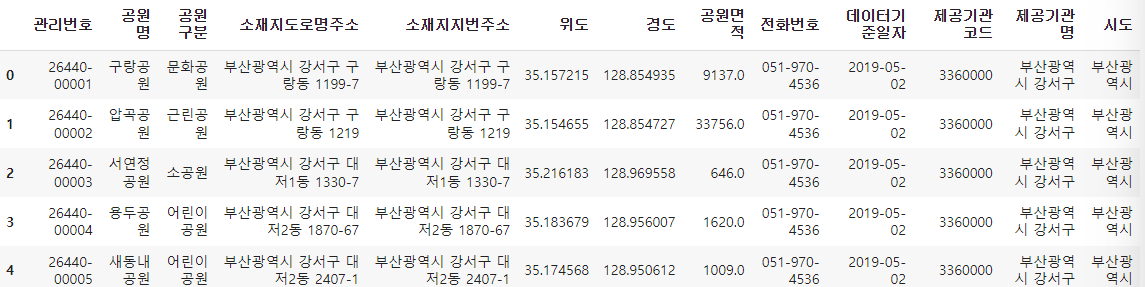
맨 오른쪽에 시도라는 파생변수가 생긴것을 확인할 수 있습니다.
park['시도'].value_counts()
여기서 이상치인 강원 을확인할 수 있고
강원-->강원도 로 변경하도록 해서 데이터처리를 하겠습니다.
park['시도'][park['시도'] == '강원'] = '강원도'park['시도'].value_counts()
강원도가 647 ---> 648로 상승한것을 확인할 수 있습니다.
scatterplot을 이용하여 시각화하기
plt.figure(figsize=(8,10))
sns.scatterplot(data=park, x='경도', y='위도', hue='시도')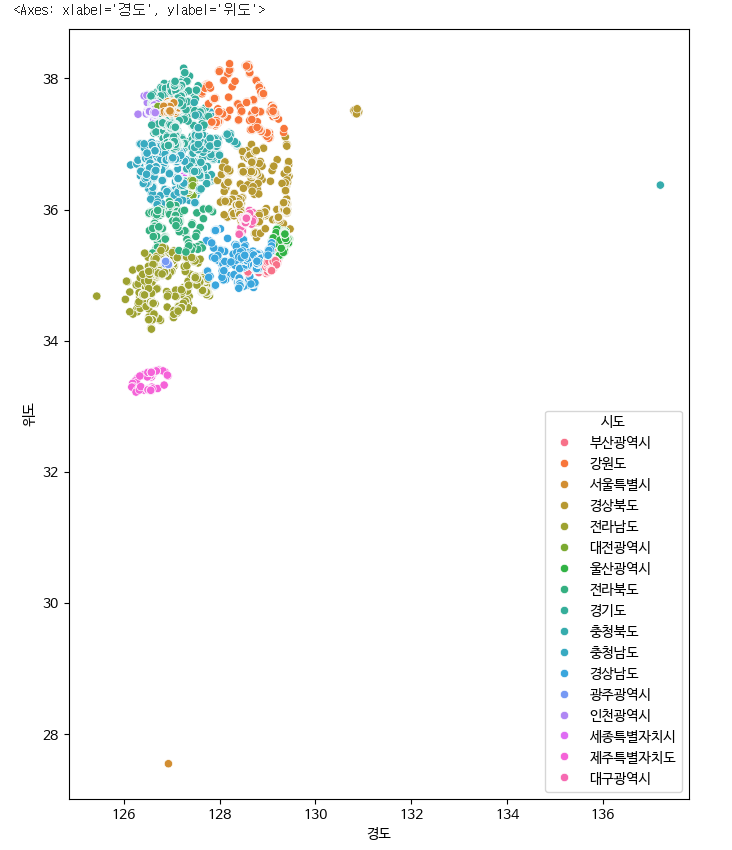
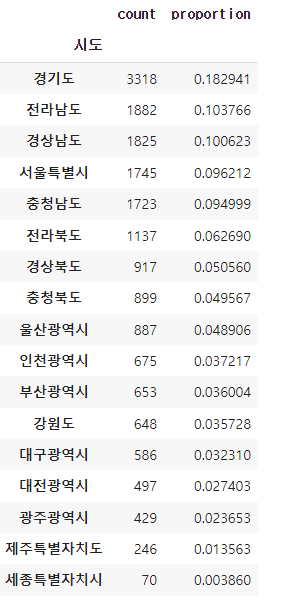
park_sido =pd.DataFrame(park['시도'].value_counts())
park_sido
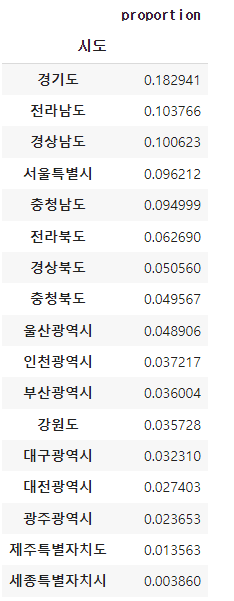
park_sido_normalize =pd.DataFrame(park['시도'].value_counts(normalize=True))
park_sido_normalize# value_counts(normalize=True): 전체 합계에 대한 비율이 계산되어서 나옵니다.
park_sido_ascending =pd.DataFrame(park['시도'].value_counts(ascending=False))
park_sido_ascending#value_counts(ascending=False): 내림차순으로 정렬

pd.concat([park_sido, park_sido_normalize], axis=1)#시도별 합계 데이터(park_sido)와 비율데이터(park_sido_normalize)를 병합
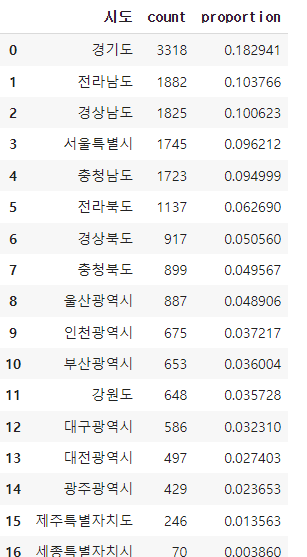
park_sido = park_sido.merge(park_sido_normalize, left_index=True, right_index=True).reset_index()
park_sido#같은 인덱스를 참고해서 merge할 수 있음
컬럼이름 변경하기
park_sido.columns = ['시도', '합계', '평균']
park_sido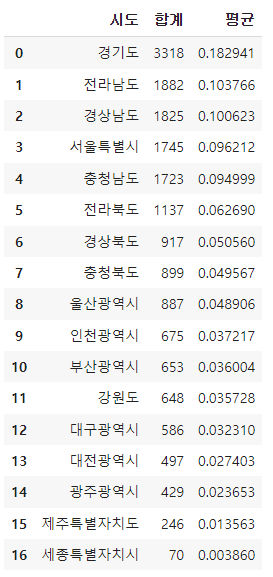
바그래프로 시각화하기
plt.figure(figsize=(12,8))
plt.xticks(rotation=45)
sns.barplot(data=park_sido, x='시도', y='합계')
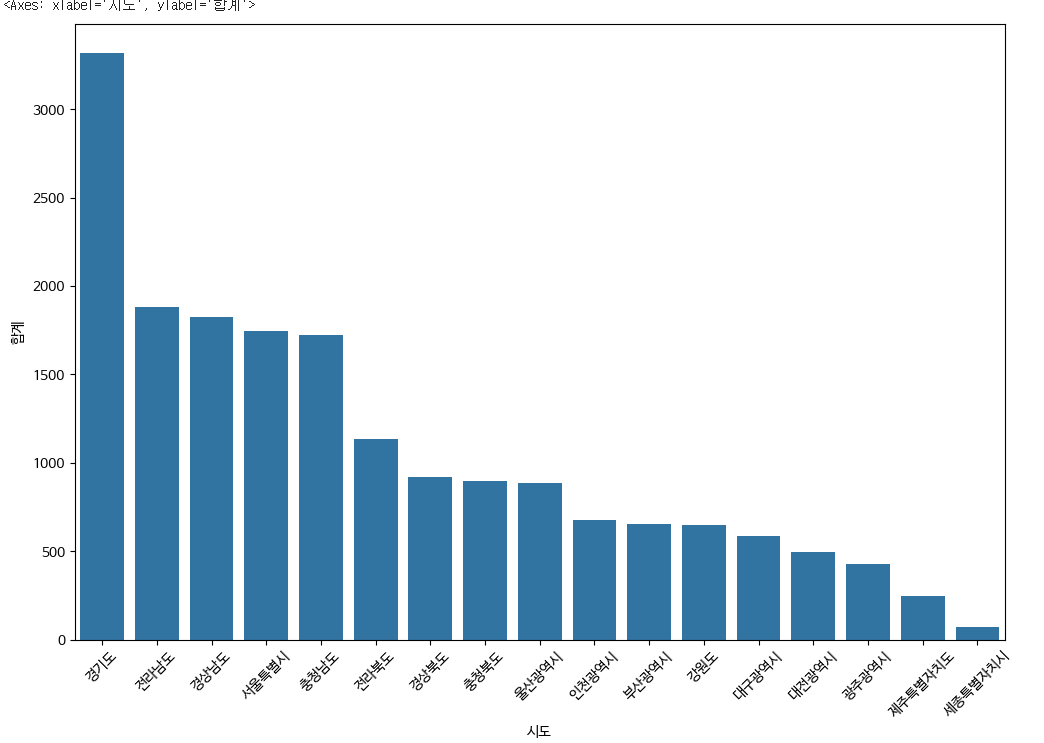
바그래프로 시각화 x,y축 변경해보기
plt.figure(figsize=(12,8))
sns.barplot(data=park_sido, x='합계', y='시도')
'데이터 분석 및 시각화' 카테고리의 다른 글
| [ML] 머신러닝(Machine Learning) (0) | 2024.06.28 |
|---|---|
| [데이터 시각화] 서울시 따릉이 API를 이용한 실시간 잔여 자전거 대수 확인하기 (0) | 2024.06.27 |
| [seaborn] 상권별 업종 밀집 통계 데이터(2) (0) | 2024.06.22 |
| [Matplotlib] 상권별 업종 밀집 통계 데이터 (0) | 2024.06.21 |
| [Matplotlib] 가상 온라인 쇼핑몰 데이터 다루기 (1) | 2024.06.20 |



