VGG19를 활용한 균열VS정상 벽 분류해보려고 합니다.
먼저 필요한 라이브러리를 임포트 해주도록 하겠습니다.
import os
import glob
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision.transforms as transforms
import torchvision.models as models
import numpy as np
from torch.utils.data import DataLoader, Dataset, SubsetRandomSampler
from torchvision.datasets import ImageFolder
from PIL import Image#데이터 루트 삽입
data_root = '/content/drive/MyDrive/경로'#이미지 출력 함수
def display_images(image_paths, title, max_images=4):
plt.figure(figsize=(12, 3))
for i, image_path in enumerate(image_paths[:max_images]):
img = plt.imread(image_path)
plt.subplot(1, max_images, i+1)
plt.imshow(img)
plt.title(title)
plt.axis('off')
plt.show()#카테고리 정하기
categories = ['Train crack', 'Train normal', 'Val crack', 'Val normal', 'Test crack','Test normal']#이미지 읽어오기
for category in categories:
image_paths = glob.glob(f'{data_root}/{category.lower().replace(" ","/")}/*')
# print(image_paths)
display_images(image_paths, category)
print(f'{category} 총 이미지 수 : {len(image_paths)}')
#bar그래프로 각 몇개인지 알아보기
plt.figure(figsize=(10, 6))
plt.bar(categories, [len(glob.glob(f'{data_root}/{category.lower().replace(" ", "/")}/*')) for category in categories], color=['blue', 'orange', 'green', 'red'])
plt.title('Number of Images per Category')
plt.xlabel('Category')
plt.ylabel('Number of Images')
plt.xticks(rotation=45)
plt.show()#compose()=한꺼번에 사이즈 변환
#모델에 넣을때는 무조건 텐선형으로 넣어야함
transform = transforms.Compose([
transforms.Resize((224,224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5,0.5), (0.5, 0.5,0.5)),
])
#ImageFolder는 리스트로 변경해주는 코드
train_dataset = ImageFolder(f'{data_root}/train', transform=transform)
val_dataset = ImageFolder(f'{data_root}/val', transform=transform)num_of_train = 34550
num_of_val = 3300
train_indices = list(range(num_of_train))
val_indices = list(range(num_of_val))#학습데이터 수가 많아서 무작위 샘플 200개 선택
np.random.shuffle(train_indices)
train_subset_indices = train_indices[:200]
np.random.shuffle(val_indices)
val_subset_indices = val_indices[:200]# 데이터로더만들기
# 학습시켜주거나 검증할때 묶어주는 단위(=데이터로더)
# 배치사이즈 맞추는 이유? 알아보기
train_loader = DataLoader(dataset=train_dataset, batch_size=8, sampler=train_subset_indices)
val_loader = DataLoader(dataset=val_dataset, batch_size=8, sampler=val_subset_indices)vgg19모델
model = models.vgg19(pretrained=True)
model = model.to(device)
model
vgg19(Visual Geometry Group 19)
- 2014년 옥스포드 대학교 연구팀이 개발한 모델 중 하나로 대회에서 높은 성능을 보여주며 유명해졌습니다.
- 주로 이미지 분류, 물체 검출, 이미지 특징 추출 등의 작업에 사용
- 19개의 층을 가지고 있어서 VGG19이라고 부르며, 구조는 간단하지만 깊이가 깊어서이미지 분류 작업에서 우수한 성능을 발휘합니다.
- 총 16개의 컨볼루션 층이 있으며, 모든 컨볼루션 필터의 크기는 3*3입니다.
- 마지막에는 세 개의 FC레이어가 있고 SOFT MAX함수로 연결되어 1000개의 클래스를 예측합니다.
- 여기서 conv는 학습하는 층(이미지를 분석), FC는 예측(최종 판단)을 하는 부분입니다.

for param in model.parameters():
param.requires_grad = Falsemodel.classifier[6] = nn.Linear(4096, 2)
model.classifier[6].requires_grad = True
model.classifier[6]= model.classifier[6].to(device)classifier6번 중
첫번째 레이어에서 4096개를받아서 2개로 내보내겠습니다.
2개로 내보내는 이유는 균열, 정상으로 나누었기때문이고
requires_grad는 TRUE로 주어서 학습을 시킵니다.
GPU로 보내는거까지 하도록 하겠습니다.
loss_func= nn.CrossEntropyLoss()손실함수는 크로스앤트로피를 사용합니다.
손실함수의 의미는 모델이 얼마나 틀렸는지 측정하는 도구이고 함수는 모델이 예측한 값과 실제 정답 사이의 차이를 계산하여, 그 차이를 손실로 표현합니다. 손실이 크면 모델이 예측을 잘못한것이고 손실이 작으면 예측을 잘한 것입니다.
왜 소프트맥스(Sofrmax)를 사용하지 않았을까?
소프트맥스도 예측값을 확률로 변환해주는 함수이고 3개이상의 클래스를 가진 경우에는 사용할 수 있다고 했는데 왜
크로스엔트로피를 사용했을까에 대한 의문이 들었습니다.(2개는 시그모이드)
| Softmax | 예측값을 확률로 변환하는 함수이고 모델의 출력을 클래스별 확률값으로 변환해서 가장 높은 확률을 가진 클래스를 예측값으로 선택함 |
| Cross Entropy | 실제 정답과 소프트맥스를 거친 예측 확률값 사이의 차이를 계산하는 손실함수 |
이로써 즉 크로스앤트로피는 소트프맥스+크로스엔트로피 손실을 한 번에 처리하는 함수이므로
굳이 소프트맥스를 사용하지 않아도 됩니다.
SGD,Adam,RAdam 비교해보기
Adam vs RAdam
- Adam
- 학습률이 각 파라미터에 대해 다르게 조정하는 특징을 가지고 있습니다.
- 각 파라미터의 변화량을 바탕으로 학습률을 조정하기 때문에 빠르게 실제 원하는 값에 수렴할 수 있습니다.
- 첫 번째 모멘텀 추정치(평균)과 두 번째 모멘텀 추정치(분산)을 사용
- 해당 추정치는 파라미터의 업데이트 방향과 크기를 조정하는데 사용됩니다.
- 단점은 처음부터 달리려고 하는 성향이 있음
- RAdam
- Adam의 변형 버전
- Adam의 장점을 유지하면서 학습 초기에 안정성을 높이기 위해 개선
- 초기학습률을 조정하는 방식에서 Adam의 바이어스 보정 단계를 수정하여 학습 초기단계의 안정성을 높인 버전입니다.(초기 학습률을 빠르게 조정하는 문제를 완화)
- 학습 초기의 학습률을 낮추고 일정 시점 이후에는 Adam과 비슷하게 학습률을 조정하게 됩니다.
def train_model(optim_name, model, train_loader, val_loader, loss_func, num_epochs=20):
if optim_name == 'SGD':
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
elif optim_name == 'Adam':
optimizer = optim.Adam(model.parameters(), lr=0.001, betas=(0.9, 0.999))
elif optim_name == 'RAdam':
optimizer = optim.RAdam(model.parameters(), lr=0.001, betas=(0.9, 0.999))
else: #에러직접발생시키기
raise ValueError(f'Unsupported optimizer: {optim_name}')
train_losses = []
val_losses = []
val_accuracies = []
for epoch in range(num_epochs):
model.train()
running_loss = 0.0
for i, data in enumerate(train_loader):
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = loss_func(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
#에포크마다 평균 로스구하기
train_loss = running_loss / len(train_loader)
train_losses.append(train_loss)
#검증
val_loss = 0.0
model.eval()
correct = 0
total = 0
with torch.no_grad():
for inputs, labels in val_loader:
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
loss = loss_func(outputs, labels)
val_loss += loss.item()
val_loss /= len(val_loader)
val_losses.append(val_loss)
val_accuracy = 100 * correct / total
val_accuracies.append(val_accuracy)
print(f'[{optim_name}] Epoch {epoch + 1}, Train Loss: {train_loss:.6f}, Val Loss: {val_loss:.6f}, Val Accuracy: {val_accuracy:.2f}%')
return train_losses, val_losses, val_accuracies
train_losses_SGD, val_losses_SGD, val_accuracies_SGD = train_model(
'SGD', model, train_loader, val_loader, loss_func
)
#val_accuracy = 100%가 찍힘
#모델 초기화 시킨 후 ADam으로 돌려보려고 함
#모델 초기화
model = models.vgg19(pretrained=True)
model = model.to(device)
model
for param in model.parameters():
param.requires_grad = False
model.classifier[6] = nn.Linear(4096, 2)
model.classifier[6].requires_grad = True
model.classifier[6]= model.classifier[6].to(device)train_losses_Adam, val_losses_Adam, val_accuracies_Adam = train_model(
'Adam', model, train_loader, val_loader, loss_func
)
#val_accuracy = 100%가 찍혀버림RAdam실행
#모델 초기화 시킨 후 RADam으로 돌려보려고 함
#모델 초기화
model = models.vgg19(pretrained=True)
model = model.to(device)
model
for param in model.parameters():
param.requires_grad = False
model.classifier[6] = nn.Linear(4096, 2)
model.classifier[6].requires_grad = True
model.classifier[6]= model.classifier[6].to(device)train_losses_RADam, val_losses_RADam, val_accuracies_RADam = train_model(
'RADam', model, train_loader, val_loader, loss_func
)
#val_accuracy = 100%가 찍혀버림# 학습 손실과 검증 정확도 그래프 그리기
plt.figure(figsize=(15, 10))
# 학습 손실 그래프
plt.subplot(3, 1, 1) # 3행 1열의 첫 번째 위치
plt.plot(train_losses_SGD, label='SGD')
plt.plot(train_losses_Adam, label='Adam')
plt.plot(train_losses_RAdam, label='RAdam')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training Loss Over Epochs')
plt.legend()
# 검증 손실 그래프
plt.subplot(3, 1, 2) # 3행 1열의 두 번째 위치
plt.plot(val_losses_SGD, label='SGD')
plt.plot(val_losses_Adam, label='Adam')
plt.plot(val_losses_RAdam, label='RAdam')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Validation Loss Over Epochs')
plt.legend()
# 검증 정확도 그래프
plt.subplot(3, 1, 3) # 3행 1열의 세 번째 위치
plt.plot(val_accuracies_SGD, label='SGD', color='blue')
plt.plot(val_accuracies_Adam, label='Adam', color='green')
plt.plot(val_accuracies_RAdam, label='RAdam', color='orange')
plt.xlabel('Epoch')
plt.ylabel('Accuracy (%)')
plt.title('Validation Accuracy Over Epochs')
plt.legend()
plt.tight_layout()
plt.show()
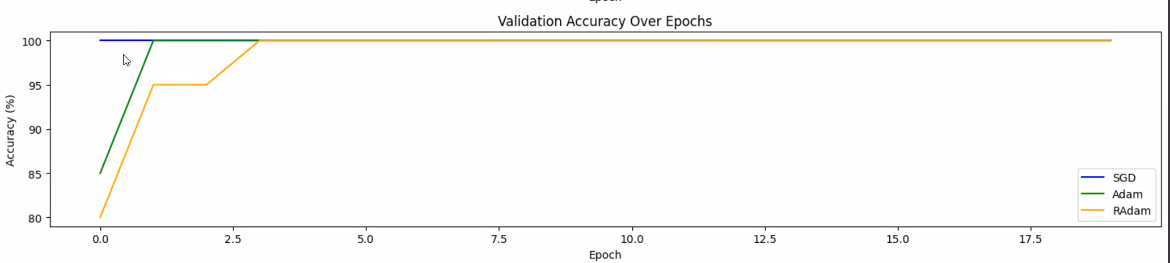
Adam은 급하게 훅 내려가지만 RADAM은 조금 조심스럽게 재려가는것을 확인할 수 있습니다.
class_folders = {
'crack': f'{data_root}/test/crack',
'normal': f'{data_root}/test/normal'
}
plt.figure(figsize=(20, 8))
counter = 1
for class_name, folder_path in class_folders.items():
image_paths = glob.glob(os.path.join(folder_path, "*"))
selected_paths = image_paths[:5]
for image_path in selected_paths:
image = load_and_transform_image(image_path, transform)
image = image.to(device)
model.eval()
with torch.no_grad():
outputs = model(image)
_, predicted = torch.max(outputs, 1)
prediction = 'crack' if predicted.item() == 0 else 'normal'
plt.subplot(2, 5, counter)
plt.imshow(Image.open(image_path))
plt.title(f'True: {class_name}, Pred: {prediction}')
plt.axis('off')
counter += 1
plt.tight_layout()
plt.show()
이런식으로 결과가 거의 다 맞는걸 볼 수 있습니다.
'AI 컴퓨터 비전프로젝트 > [ML,DL]머신러닝,딥러닝' 카테고리의 다른 글
| [DL] 케글을 활용한 강아지 품종 분류 (1) | 2024.09.24 |
|---|---|
| [DL] VGG19을 이용한 산타VS일반인 분류해보기 (2) | 2024.09.10 |
| [DL] AlexNet을 활용한 안경착용 vs 안경 미착용 구분/완료 (0) | 2024.09.08 |
| [DL] AlexNet을 활용한 <깔끔한 방 VS 지저분한 방> 분류하기 (0) | 2024.08.26 |
| [DL] 컴퓨터 비전 데이터셋 활용링크 (1) | 2024.08.25 |



