import os
import glob
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision.transforms as transforms
import torchvision.models as models
import numpy as np
from torch.utils.data import DataLoader, Dataset, SubsetRandomSampler
from torchvision.datasets import ImageFolder
from PIL import Imagedata_root = '/content/drive/MyDrive/경로'device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
devicedef display_images(image_paths, title, max_images=4):
plt.figure(figsize=(12, 3))
for i, image_path in enumerate(image_paths[:max_images]):
img = plt.imread(image_path)
plt.subplot(1, max_images, i+1)
plt.imshow(img)
plt.title(title)
plt.axis('off')
plt.show()#카테고리 정하기
categories = ['Train santa', 'Train normal', 'Val santa', 'Val normal', 'Test santa', 'Test normal']#이미지 읽어오기
for category in categories:
image_paths = glob.glob(f'{data_root}/{category.lower().replace(" ", "/")}/*')
# print(image_paths)
display_images(image_paths, category)
print(f'{category} 총 이미지 수: {len(image_paths)}')




#데이터 분포 그래프 확인하기
plt.figure(figsize=(10, 6))
plt.bar(categories, [len(glob.glob(f'{data_root}/{category.lower().replace(" ", "/")}/*')) for category in categories], color=['blue', 'orange', 'green', 'red'])
plt.title('Number of Images per Category')
plt.xlabel('Category')
plt.ylabel('Number of Images')
plt.xticks(rotation=45)
plt.show()

#compose()=한꺼번에 사이즈 변환
#이미지 전처리
#모델에 넣을때는 무조건 텐선형으로 넣어야함
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.RandomRotation(30),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.458, 0.406], std=[0.229, 0.224, 0.225])
])#ImageFolder는 리스트로 변경해주는 코드
train_dataset = ImageFolder(f'{data_root}/train', transform=transform)
val_dataset = ImageFolder(f'{data_root}/val', transform=transform)
# 데이터로더만들기
# 학습시켜주거나 검증할때 묶어주는 단위(=데이터로더)
train_loader = DataLoader(dataset=train_dataset, batch_size=16, shuffle=True)
val_loader = DataLoader(dataset=val_dataset, batch_size=16, shuffle=False)
class VGG19(nn.Module):
def __init__(self, num_classes=1000):
super(VGG19, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, padding=1),
# 메모리 절약, 입력 텐서의 원본 데이터가 변경
nn.ReLU(inplace=True),
nn.Conv2d(64, 64, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(64, 128, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(128, 128, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(128, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(256, 512, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2)
)
self.classifier = nn.Sequential(
nn.Linear(512 * 7 * 7, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, num_classes)
)
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
# 사전 학습된 VGG19 모델 불러오기
pretrained_vgg19 = models.vgg19(pretrained=True)
#껍데기가 있는 모델
model = VGG19(num_classes=1000)클래스를 1천으로 준 이유는 사전학습된 vgg19와 맞춰주려고했습니다.
# 사전 학습된 모델의 features 부분에서 가중치 추출
pretrained_keys = set(pretrained_vgg19.features.state_dict().keys())이렇게 되면 가중치를 추출 할 수 있습니다.
전이학습된 부분에서 학습된 부분을 가져온거죠!
# state_dict 키와 모델의 파라미터 이름이 일치하지 않으면 오류가 발생
# strict=False 설정하면 일부 파라미터가 다르더라도 일치하는 부분만 로드, 나머지는 무시
result = model.features.load_state_dict(pretrained_vgg19.features.state_dict(), strict=False)이름이 일치하지않으면 오류가 발생하게되는데 그건 strict때문에 그렇습니다.
그래서 False로 설정하게 되면 일부 파라미터가 다르더라도 일치하는 부분만 로드되고 나머지는 무시됩니다.
# 복사 후 커스텀 모델의 features 부분에서 가중치 추출
custom_keys = set(model.features.state_dict().keys())
# 커스텀 모델과 사전 학습된 모델 모두에 존재하는 가중치
successfully_copied_keys = pretrained_keys.intersection(custom_keys)
# 커스텀 모델에는 있지만 사전 학습된 모델에 없는 가중치
missing_keys = custom_keys - pretrained_keys# 사전 학습된 모델에는 있지만 커스텀 모델에 없는 가중치
unexpected_keys = pretrained_keys - custom_keys
# 알수있는것 : 교집합 가중치를 갖고있는건 없다는것임.
print('successfully_copied_keys: ', successfully_copied_keys)
print('missing_keys: ', missing_keys)
print('unexpected_keys: ', unexpected_keys)미싱키, 언익스펙티드키는 없고 석세스풀리키만 나오게됩니다.
#파라미터 고정해주기
for param in model.features.parameters():
param.requires_grad = False
학습이안되도록 고정시킵니다.
#output을 1개로 한것
model.classifier[6] = nn.Linear(4096, 1)
for param in model.classifier.parameters():
param.requires_grad = True재학습을 해야되는 부분인 6번을 재학습해줍니다.
내보내는건 1개로 내보내고 Sigmoid(0~1사이)로 내보냅니다.
model = model.to(device)
model
#BCE는 2개의 바이너리로 나뉘는 함수
loss_func = nn.BCEWithLogitsLoss()
def validate_model(model, val_loader, loss_func):
model.eval() #eval모드
val_loss = 0.0
correct = 0
total = 0
with torch.no_grad():
for inputs, labels in val_loader:
inputs, labels = inputs.to(device), labels.to(device)
labels = labels.float().unsqueeze(1) #unsqueeze차원 맞춰주기
outputs = model(inputs)
val_loss += loss_func(outputs, labels).item()
predicted = torch.sigmoid(outputs) > 0.5
total += labels.size(0)
correct += (predicted == labels).sum().item()
val_loss /= len(val_loader)
val_accuracy = 100 * correct / total
return val_loss, val_accuracy
def train_model(optim_name, model, train_loader, val_loader, loss_func, num_epochs=10):
if optim_name == 'SGD':
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
elif optim_name == 'Adam':
optimizer = optim.Adam(model.parameters(), lr=0.001, betas=(0.9, 0.999))
elif optim_name == 'RAdam':
optimizer = optim.RAdam(model.parameters(), lr=0.001, betas=(0.9, 0.999))
else:
raise ValueError(f'Unsupported optimizer: {optim_name}')
train_losses = []
val_losses = []
val_accuracies = []
for epoch in range(num_epochs):
model.train()
running_loss = 0.0
for inputs, labels in train_loader:
inputs, labels = inputs.to(device), labels.to(device)
labels = labels.float().unsqueeze(1)
optimizer.zero_grad()
outputs = model(inputs)
loss = loss_func(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
train_loss = running_loss / len(train_loader)
train_losses.append(train_loss)
val_loss, val_accuracy = validate_model(model, val_loader, loss_func)
val_losses.append(val_loss)
val_accuracies.append(val_accuracy)
print(f'[{optim_name}] Epoch {epoch + 1}, Train Loss: {train_loss:.6f}, Val Loss: {val_loss:.6f}, Val Accuracy: {val_accuracy:.2f}%')
return train_losses, val_losses, val_accuraciestrain_losses_Adam, val_losses_Adam, val_accuracies_Adam = train_model(
'Adam', model, train_loader, val_loader, loss_func
)각 adam으로 학습을 시키는데 시간이 조금 걸립니다.
# 학습 손실과 검증 정확도 그래프 그리기
plt.figure(figsize=(15, 10))
# 학습 손실 그래프
plt.subplot(3, 1, 1) # 3행 1열의 첫 번째 위치
plt.plot(train_losses_Adam, label='Adam')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training Loss Over Epochs')
plt.legend()
# plt.ylim(0, 0.2)
# 검증 손실 그래프
plt.subplot(3, 1, 2) # 3행 1열의 두 번째 위치
plt.plot(val_losses_Adam, label='Adam')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Validation Loss Over Epochs')
plt.legend()
# plt.ylim(0, 1.5)
# 검증 정확도 그래프
plt.subplot(3, 1, 3) # 3행 1열의 세 번째 위치
plt.plot(val_accuracies_Adam, label='Adam', color='green')
plt.xlabel('Epoch')
plt.ylabel('Accuracy (%)')
plt.title('Validation Accuracy Over Epochs')
plt.legend()
# plt.ylim(80, 100)
plt.tight_layout()
plt.show()
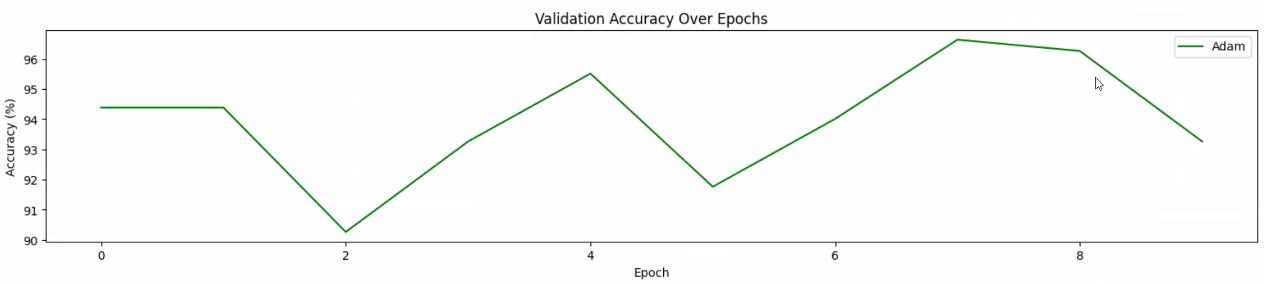
8정도를 가중치를 잡으면 될것으로 예상할 수있습니다.
#잘 예측하는지 확인하기
def load_and_transform_image(image_paths, transform):
image = Image.open(image_path).convert('RBG')
return transform(image).unsqueeze(0).to(device)#클래스별로 경로 주어주고 시각화시키기
class_folders = {
'santa': f'{data_root}/test/santa',
'normal': f'{data_root}/test/normal'
}
plt.figure(figsize=(20, 8))
counter = 1
for class_name, folder_path in class_folders.items():
image_paths = glob.glob(os.path.join(folder_path, "*"))
selected_paths = image_paths[:5]
for image_path in selected_paths:
image = load_and_transform_image(image_path, transform)
model.eval()
with torch.no_grad():
outputs = model(image)
probs = torch.sigmoid(outputs).item()
prediction = 'santa' if prbs >=0.5 else 'normal'
plt.subplot(2, 5, counter)
plt.imshow(Image.open(image_path))
plt.title(f'True: {class_name}, Pred: {prediction}')
plt.axis('off')
counter += 1
plt.tight_layout()
plt.show()
'AI > 컴퓨터 비전' 카테고리의 다른 글
| [DL] 케글을 활용한 강아지 품종 분류 (1) | 2024.09.24 |
|---|---|
| [DL] VGG19를 활용한 균열 VS 정상 벽 분류해보기 (0) | 2024.09.20 |
| [DL] AlexNet을 활용한 안경착용 vs 안경 미착용 구분/완료 (1) | 2024.09.08 |
| [DL] AlexNet을 활용한 <깔끔한 방 VS 지저분한 방> 분류하기 (0) | 2024.08.26 |
| [DL] 컴퓨터 비전 데이터셋 활용링크 (1) | 2024.08.25 |



