이번에는 알렉스넷을 활용해서 안경착용, 미착용을 구분하려고합니다.
받은 이미지를 보면 사진 위에 글씨가 있었는데 그 부분을 하나하나 자를수있겠지만 양이 많을때는 사실상 그러기 너무 힘드니까 크롭하는 코드까지 추가해서 예제를 진행해보려고 합니다.
import os
import glob
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision.transforms as transforms
import torchvision.models as models
from torch.utils.data import DataLoader, Dataset
from torchvision.datasets import ImageFolder
from PIL import Image
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
device
#크롭하는 함수만들기
def display_images_center_crop(image_paths, title, max_images=4):
plt.figure(figsize=(12, 3))
for i, image_path in enumerate(image_paths[:max_images]):
image = Image.open(image_path)
width, height = image.size
# 이미지 중앙의 정사각형 영역을 계산
new_edge_length = min(width, height)
left = (width - new_edge_length)/2
top = (height - new_edge_length)/2
right = (width + new_edge_length)/2
bottom = (height + new_edge_length)/2
# 중앙 영역 크롭
image_cropped = image.crop((10, 20, width-10, height-15))
# 크롭된 이미지 시각화
plt.subplot(1, max_images, i+1)
plt.imshow(image_cropped)
plt.title(title)
plt.axis('off')
plt.show()
data_root = '/content/drive/MyDrive/컴퓨터 비전 시즌2/5. 컴퓨터 비전/data/3'#카테고리 정하기
categories = ['Train Glasses', 'Train NoGlasses', 'Val Glasses', 'Val NoGlasses', 'Test Glasses','Test NoGlasses']#이미지 읽어오기
for category in categories:
image_paths = glob.glob(f'{data_root}/{category.lower().replace(" ","/")}/*')
# print(image_paths)
display_images_center_crop(image_paths, category)
print(f'{category} 총 이미지 수 : {len(image_paths)}')
#bar그래프로 각 몇개인지 알아보기
plt.figure(figsize=(10, 6))
plt.bar(categories, [len(glob.glob(f'{data_root}/{category.lower().replace(" ", "/")}/*')) for category in categories], color=['blue', 'orange', 'green', 'red'])
plt.title('Number of Images per Category')
plt.xlabel('Category')
plt.xlabel('Number of Images')
plt.xticks(rotation=45)
plt.show()
transform = transforms.Compose([
transforms.CenterCrop(128),
transforms.Resize((224, 224)),
transforms.RandomHorizontalFlip(), # 이미지를 무작위로 수평 뒤집기
transforms.RandomRotation(30), # 이미지를 30도 무작위로 회전
# 이미지의 밝기, 대비, 채도, 색조를 무작위로 변경
transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1),
transforms.RandomGrayscale(p=0.2), # 20% 확률로 이미지를 그레이스케일로 변환
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])centerCrop은128*128사이즈로 자르는 역할을 하고있습니다.
Random이 들어간건 로테이션을 할수도있고 안할수도있다라는 말입니다.
tensor형으로 바꾸는건 모델에 들어가는 형태가 필수이기때문입니다.
train_dataset = ImageFolder(f'{data_root}/train/', transform=transform)
val_dataset = ImageFolder(f'{data_root}/val/', transform=transform)
train_loader = DataLoader(train_dataset, batch_size=4, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=4, shuffle=False)데이터셋을 만들어주고, transform의 함수까지 적용시켜준 후 그 데이터들을 각각 데이터셋에 넣게됩니다.

class AlexNet(nn.Module):
def __init__(self, num_classes=1000):
super(AlexNet, self).__init__()
self.conv1 = nn.Conv2d(3, 96, kernel_size=11, stride=4, padding=2)
self.conv2 = nn.Conv2d(96, 256, kernel_size=5, padding=2)
self.conv3 = nn.Conv2d(256, 384, kernel_size=3, padding=1)
self.conv4 = nn.Conv2d(384, 384, kernel_size=3, padding=1)
self.conv5 = nn.Conv2d(384, 256, kernel_size=3, padding=1)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2)
self.fc1 = nn.Linear(256 * 6 * 6, 4096)
self.fc2 = nn.Linear(4096, 4096)
self.fc3 = nn.Linear(4096, num_classes)
self.dropout = nn.Dropout()
def forward(self, x):
x = self.maxpool(F.relu(self.conv1(x)))
x = self.maxpool(F.relu(self.conv2(x)))
x = F.relu(self.conv3(x))
x = F.relu(self.conv4(x))
x = self.maxpool(F.relu(self.conv5(x)))
# FC Layer
x = x.view(x.size(0), 256 * 6 * 6)
x = self.dropout(F.relu(self.fc1(x)))
x = self.dropout(F.relu(self.fc2(x)))
x = self.fc3(x)
return x모델을 직접 구현해보았습니다. 각각 covn1부터 maxpool이 있는지 없는지 확인을 해주고 모델껍데기를 만들어주게됩니다.
model = AlexNet(num_classes=2)
model = model.to(device)AlexNet은 클래스 개수가 2개(안경을 쓴 사람, 안 쓴사람)으로나누고
모델은 gpu로 돌아갈 수 있게 합니다.
loss_func = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.0001)손실함수는 crossEntropyLoss를 하게됩니다.
옵티마이저같은경우에는 Ir은 0.0001로 주어도 무방합니다.
def calculate_accuracy(loader, model):
model.eval()
correct = 0
total = 0
with torch.no_grad():
for data in loader:
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
return 100 * correct / total정확도를 확인할 수있는 함수입니다.
train_losses = []
val_losses = []
val_accuracies = []각각 손실값을을 알 수 있는 데이터 리스트입니다.
아래부터는 학습을 시키는 에포크입니다.
num_epochs = 30
for epoch in range(num_epochs):
model.train()
running_loss = 0.0
for i, data in enumerate(train_loader):
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = loss_func(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
train_loss = running_loss / len(train_loader)
train_losses.append(train_loss)
val_loss = 0.0
model.eval()
with torch.no_grad():
for inputs, labels in val_loader:
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
loss = loss_func(outputs, labels)
val_loss += loss.item()
val_loss /= len(val_loader)
val_losses.append(val_loss)
val_accuracy = calculate_accuracy(val_loader, model)
val_accuracies.append(val_accuracy)
print(f'Epoch {epoch + 1}, Train Loss: {train_loss: .6f}, Val Loss: {val_loss: .6f}, Val Accuracy: {val_accuracy: .2f}%')여기서 에포크가 돌면서 92.5%확률로 검증 확률을 표현해주었습니다.
# 그래프
plt.figure(figsize=(15, 5))
# 학습 손실 그래프
plt.subplot(1, 3, 1)
plt.plot(train_losses, label='Train Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training Loss Over Epochs')
plt.legend()
# 검증 정확도 그래프
plt.subplot(1, 3, 2)
plt.plot(val_losses, label='Validation Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Validation Loss Over Epochs')
plt.legend()
# 검증 정확도 그래프
plt.subplot(1, 3, 3)
plt.plot(val_accuracies, label='Validation Accuracy', color='orange')
plt.xlabel('Epoch')
plt.ylabel('Accuracy (%)')
plt.title('Validation Accuracy Over Epochs')
plt.legend()
plt.tight_layout()
plt.show()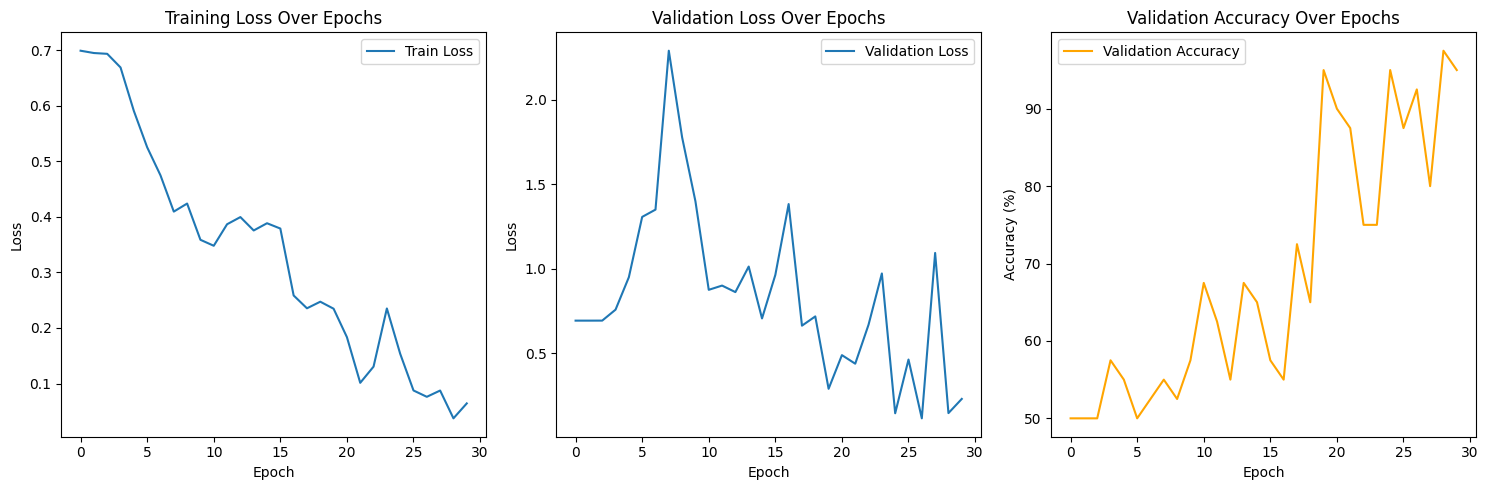
시각화 시켜보기
test데이터에서 glass 5명, no-glass 5명 뽑아서 제대로 예측하는지 확인하기
def load_and_transform_image(image_paths, transform):
image = Image.open(image_path).convert('RGB')
width, height = image.size
# 중앙에서 128*128 크기로 크롭하기 위한 시작점과 끝점 계산
left = (width - 128)/2
top = (height - 128)/2
right = (width + 128)/2
bottom = (height + 128)/2
# 중앙 영역 크롭
image_cropped = image.crop((left, top, right, bottom))
return transform(image_cropped)import numpy as np
class_folders = {
'glass': f'{data_root}/test/glasses',
'no glass': f'{data_root}/test/noglasses'
}
plt.figure(figsize=(20, 8))
counter = 1
for class_name, folder_path in class_folders.items():
image_paths = glob.glob(os.path.join(folder_path, "*"))
selected_paths = image_paths[:5]
for image_path in selected_paths:
image_cropped = load_and_transform_image(image_path, transform) # 단일 값 반환
image_unsqueeze = image_cropped.unsqueeze(0)
image_unsqueeze = image_unsqueeze.to(device)
outputs = model(image_unsqueeze)
_, predicted = torch.max(outputs, 1)
prediction = 'glass' if predicted.item() == 0 else 'no glass'
# Tensor를 NumPy 배열로 변환하고 차원 순서 변경
image_np = image_cropped.cpu().numpy() # GPU에서 CPU로 이동 후 NumPy로 변환
image_np = np.transpose(image_np, (1, 2, 0)) # (3, 224, 224) -> (224, 224, 3)
plt.subplot(2, 5, counter)
plt.imshow(image_np)
plt.title(f'True: {class_name}, Pred: {prediction}')
plt.axis('off')
counter += 1
plt.tight_layout()
plt.show()
어우 뭐 무섭지만 이렇게 되는 사진 예측결과값을 얻을 수 있었습니다.
'AI 컴퓨터 비전프로젝트 > [ML,DL]머신러닝,딥러닝' 카테고리의 다른 글
| [DL] VGG19를 활용한 균열 VS 정상 벽 분류해보기 (0) | 2024.09.20 |
|---|---|
| [DL] VGG19을 이용한 산타VS일반인 분류해보기 (2) | 2024.09.10 |
| [DL] AlexNet을 활용한 <깔끔한 방 VS 지저분한 방> 분류하기 (0) | 2024.08.26 |
| [DL] 컴퓨터 비전 데이터셋 활용링크 (1) | 2024.08.25 |
| [DL] open cv2 필터(블러링, 평균, 가우시안, 미디언, 바이레터럴) (1) | 2024.08.24 |



