1. 손글씨 데이터셋
from sklearn.datasets import load_digits사이킷런 안에 데이터셋 안에 load_digits가 있습니다.
데이터셋안에 많은것들이있고 그 중에 아이리스도 있습니다.
load_dighits은 사람이 손으로 쓴 글씨를 이미지로 저장해놓은 데이터셋입니다.
#객체 확인
digits = load_digits()
digits.keys()
#dict_keys(['data', 'target', 'frame', 'feature_names', 'target_names', 'images', 'DESCR'])key들은 딕셔너리구조로 되어있습니다.
data = digits['data']
data.shape
#(1797, 64)컬럼은 64개가 있다는것을 확인할 수 있습니다.
target = digits['target']
target.shape
#(1797,)이 두개를 학습시켜서 새로운 이미지가 나오면 어떤건지 맞출 수 있도록 하려고 합니다.
정답데이터를 확인해보겠습니다.
target
#array([0, 1, 2, ..., 8, 9, 8])0부터 8까지가 들어가있다는것을 알 수 있습니다.
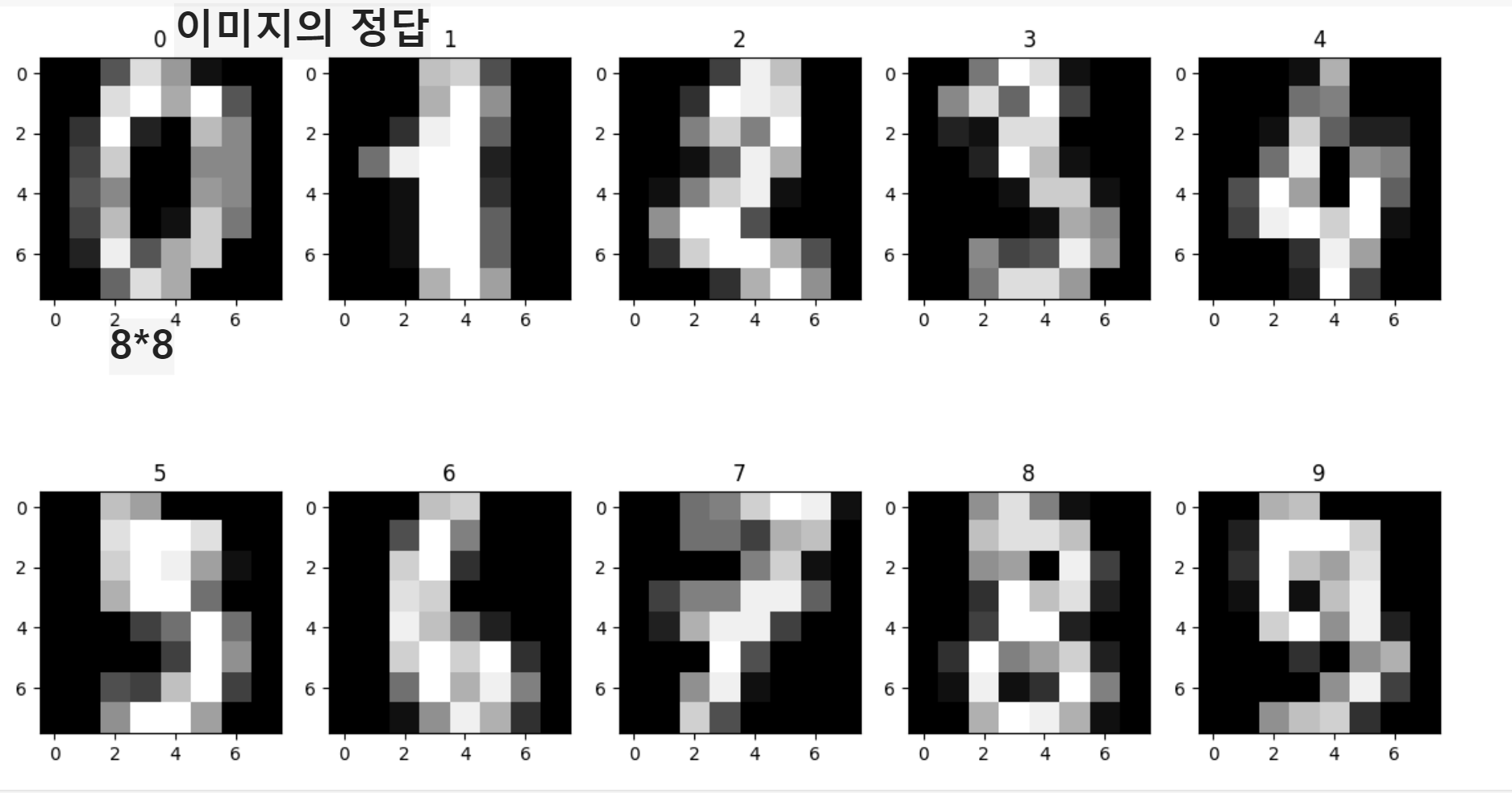
_, axes = plt.subplots(2, 5, figsize=(14, 8))
for i , ax in enumerate(axes.flatten()):
ax.imshow(data[i].reshape((8, 8)), cmap='gray')
ax.set_title(target[i])subplot을 만들겠다는것 크기는 14,8 입니다.
_의 앞에 값이 필요가 없으면 _를 넣으면 변수가 만들어지지 않습니다.
flatten은 2행 5열이아닌 1열로 만들어줍니다. 그 후 0부터 9까지 값을 각각 i로 넣어주게됩니다.
reshape하게되면 8*8로 하게되면 다시모양을 잡아줍니다.
데이터 전처리를 하기위한 챕터!
2.스케일링
- 데이터의 크기가 다르면 비교하기가 어려우니 데이터를 특정한 스케일로 통일하는 것
- 다차원의 값들을 비교 분석하기 쉽게 만들어주며, 자료의 오버플로우나 언더플로우를 방지하여 최적화 과정에서의 안정성 및 수렴 속도를 향상시켜줍니다.
- 데이터를 모델링하기 전에 거치는 것이 좋습니다.
2-1.스케일링의 종류
- StandardScaler : 평균과 표준편차를 사용
- MinMaxScaler : 최소, 최대값이 각각 0과 1이 되도록 스케일링
- RobustScaler : 중앙값과 IQR사용(아웃라이어의 영향을 최소화시켜주는 효과가 있음)
시각적으로 봐보기
상황 : 네이버영화 평점, 넥플 영화평점이라고 가정해봅시다.
네이버는 0점이 최저 10점이 최고점수
넥플은 0점이 최저 5점이 최고점수입니다.
네이버에서 5점받았다고 넥플에서 제일 재밌어질까요..? 그럴가능성은 살짝쿵 적겠죠
반대로 넥플에서 5점받았다고 네이버에서 5점밖에안될까요? 그것도 아니겠죠!?
이런식으로 서로 규모(구간)이 다른 애매한 점을 스케일링을 통해서 맞춰주려고 합니다.
import pandas as pd
movie = {'naver': [1, 4, 10, 7, 3], 'netflix':[1, 5, 3, 2, 5]}
movie = pd.DataFrame(movie)
movie

from sklearn.preprocessing import StandardScaler, MinMaxScaler, RobustScaler
min_max_scaler = MinMaxScaler()
min_max_scaler = min_max_scaler.fit_transform(movie)
min_max_scaler
#array([[0. , 0. ],
# [0.33333333, 1. ],
# [1. , 0.5 ],
# [0.66666667, 0.25 ],
# [0.22222222, 1. ]])이렇게보면 값이 좀 직관적이지 않으니 판다스를 사용해보겠습니다.
#movie = {'naver': [1, 4, 10, 7, 3], 'netflix':[1, 5, 3, 2, 5]}
pd.DataFrame(min_max_scaler,columns=['naver', 'netflix'])
2-2. 정규화(Normalization)
- 값의 범위(Scale)을 0~1 사이의 값으로 바꿔주는 것
- 학습 전에 Scaling을 하는 것
- 머신러닝, 딥러닝에서 Scale이 큰 Feature의 영향이 비대해지는 것을 방지
- scikit-learn에서 MinMaxScaler사용
data[0]
min_max_scaler = MinMaxScaler()
scaled_data = min_max_scaler.fit_transform(data)
scaled_data[0]
2-3. 표준화(Standardization)
- 값의 범위(Scale)를 평균 0, 분산 1이 되도록 바꿔주는 것
- 학습 전에 Scaling하는 것
- 머신러닝, 딥러닝에서 Scale이 큰 Feature의 영향이 비대해지는 것을 방지
- scikit-learn에서 StandardScaler사용
import numpy as np
sample = np.array([[1,2], [3,4], [5,6], [7,8]])
standard_scaler = StandardScaler()
scaled_sample = standard_scaler.fit_transform(sample)
print('원본데이터: ', sample)
print('스케일링 데이터: ', scaled_sample)
# 원본데이터: [[1 2]
# [3 4]
# [5 6]
# [7 8]]
# 스케일링 데이터: [[-1.34164079 -1.34164079]
# [-0.4472136 -0.4472136 ]
# [ 0.4472136 0.4472136 ]
# [ 1.34164079 1.34164079]]from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(scaled_data, target, test_size=0.2, random_state=2024)
X_train.shape,y_train.shape
#((1437, 64), (1437,))
X_test.shape,y_test.shape
#((360, 64), (360,))3. Support Vector Machine(SVM)
- 두 클래스로부터 최대한 멀리 떨어져있는 결정 경계를 찾는 분류기 입니다.
- 특정 조건을 만족하는 동시에 클래스를 분류하는 것을 목표로 함

from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
model = SVC()
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
accuracy_score(y_test, y_pred)
#0.9888888888888889
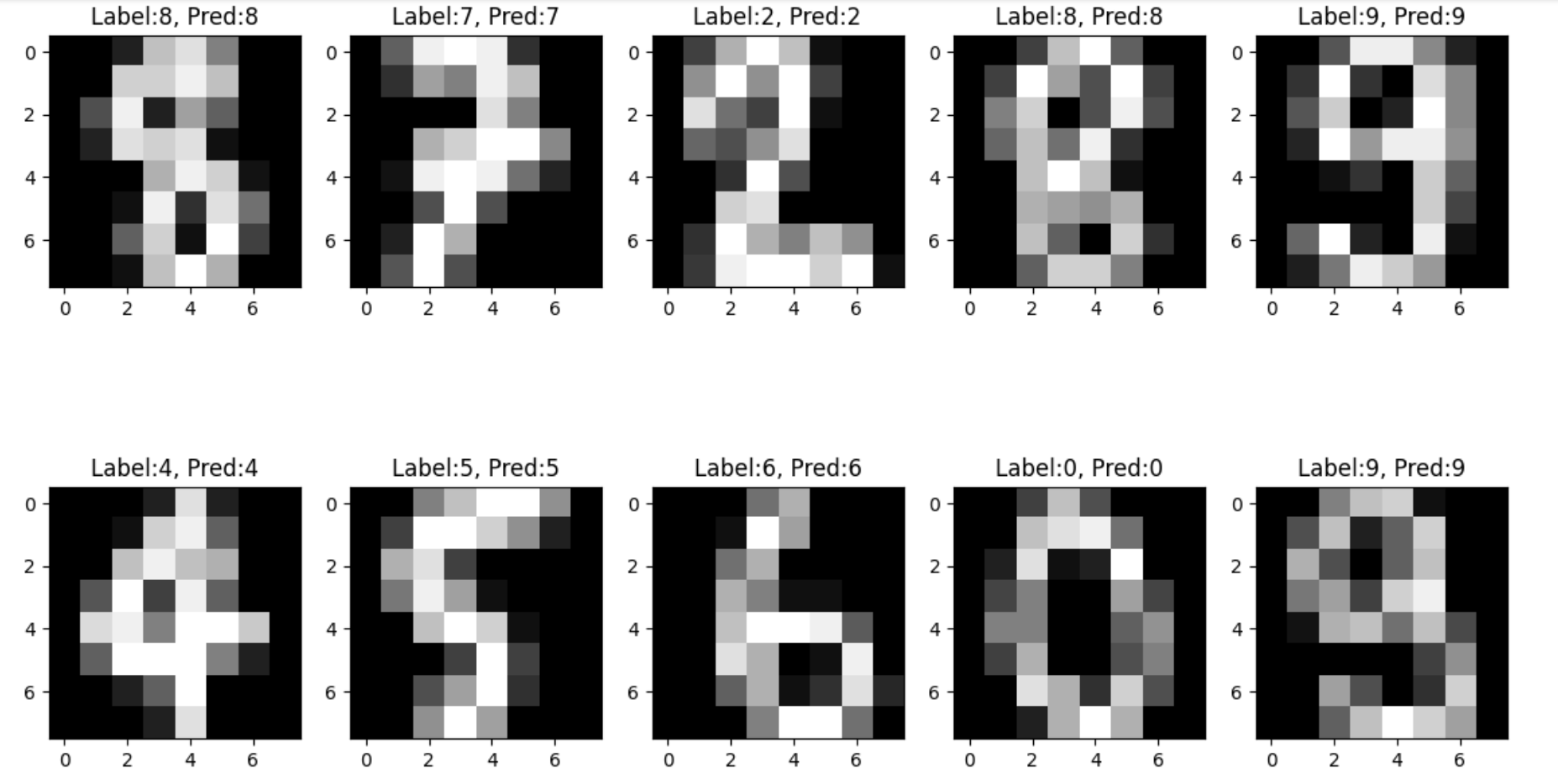
print(y_test[10], y_pred[10])
#7 7
plt.imshow(X_test[10].reshape(8, 8), cmap='gray')
테스트해보니 y_test, t_pred 둘다 10번째의 값이 7로 동일하다는것을 알 수 있습니다.
그래서 ishow로 확인해보니 7이 나오는것을 확인할 수 있습니다.
_, axes = plt.subplots(2, 5, figsize=(14, 8))
for i , ax in enumerate(axes.flatten()):
ax.imshow(X_test[i].reshape((8, 8)), cmap='gray')
ax.set_title(f'Label:{y_test[i]}, Pred:{y_pred[i]}')
'데이터 분석 및 시각화' 카테고리의 다른 글
| [데이터분석] 판다스 활용하기, json파일 가져와서 데이터 나눠보기 (0) | 2024.08.03 |
|---|---|
| [ML] 랜덤 포레스트를 이용한 호텔 데이터 다루기 (1) | 2024.07.14 |
| [ML] 의사 결정 나무(decision tree)_bike 데이터 활용(2) (0) | 2024.07.06 |
| [ML] 의사 결정 나무(decision tree)_bike 데이터 활용 (2) | 2024.07.05 |
| [ML] 사이킷런(Scikit-learn) (0) | 2024.06.30 |



