1.hotel 데이터셋
-이번에는 호텔정보를 가지고 취소를 할 것 같은 고객인지 분류해보는 프로젝트를 진행해보려고 합니다.
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
hotel_df = pd.read_csv('/content/drive/MyDrive/컴퓨터 비전 시즌2/3. 데이터 분석/data/hotel.csv')
hotel_df.head()
hotel_df.info()

여기서 is_canceled는 종속변수로 둘거고
필요하지 않은 데이터들은 나누면서 데이터 전처리를 해보도록 하겠습니다.
여기서 디타입을 보면 오브젝트가 보이는데 이제는 오브젝트를 보면 데이터 전처리 해야할것들이 있다고
생각이 어느정도는 듭니다.
즉 필요하지않은데이터들을 나누고 오브젝트디타입은 원핫인코딩으로 데이터전처리를
끝내면 되겠죠?
인포는 보았으니 간단한 분석도 해보겠습니다.
hotel_df.describe()를해보면 컬럼이 27개로 좀 많아서 다 보이진 않겠지만

위 사진처럼 나옵니다.
각각 어떤 관계가 있는지 데이터들이 얼마나 신뢰성이 있는지 sns로 확인을 해보겠습니다.
일단 lead_time 남은기간 값을 보겠습니다.
sns.displot(hotel_df['lead_time'])
근데 700일전에 누가 예약을 할까 해서 이상치인가 해서 보도록 하겠습니다.
sns.boxplot(hotel_df['lead_time'])
sns.barplot(x=hotel_df['distribution_channel'], y=hotel_df['is_canceled'])
어디를 통해서 예약했는지를 확인본 것입니다.
심지가 긴것은 데이터가 좀 적다는것은 이제는 압니다!
hotel_df['distribution_channel'].value_counts()distribution_channel
TA/TO 97870
Direct 14645
Corporate 6677
GDS 193
Undefined 5
Name: count, dtype: int64여기서 보면 언디파인드가 확연하게 적다는게 느껴지죠.
sns.barplot(x=hotel_df['hotel'], y=hotel_df['is_canceled'])
가족끼리 가는 리조트호텔은 취소없이 가는편이고
출장으로 가는 시티호텔은 취소가 조금 더 있는 편이라는것을 알 수 있습니다
sns.barplot(x=hotel_df['arrival_date_year'], y=hotel_df['is_canceled'])

plt.figure(figsize=(15, 5))
sns.barplot(x=hotel_df['arrival_date_month'], y=hotel_df['is_canceled'])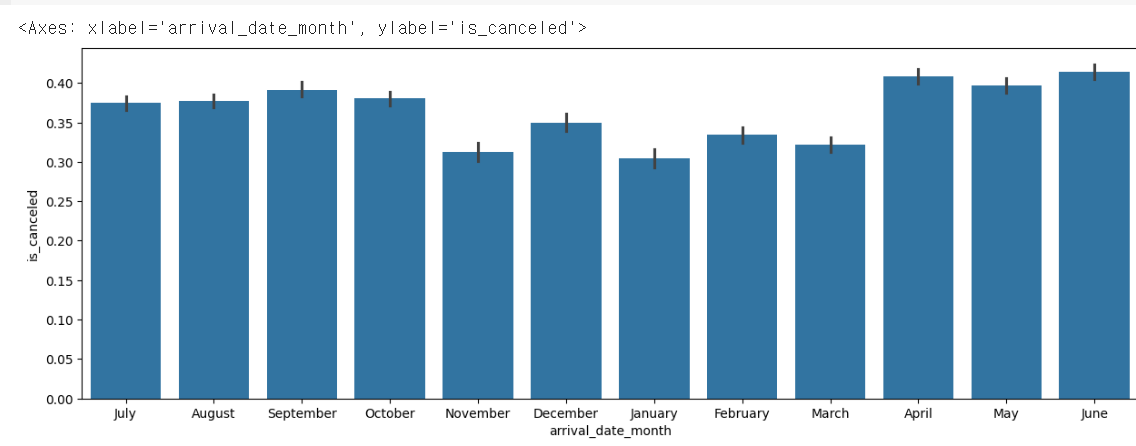
월도 제각각이고 한 눈에 보이지않아서 calendar모듈을 사용해서 보도록 하겠습니다.
사용방법은 print(calender.month_name[숫자])
숫자안에 넣어주면 월 이름이 나옵니다.
import calendar
print(calendar.month_name[1])
print(calendar.month_name[2])
print(calendar.month_name[3])
#January
#February
#Marchmonth = []
for i in range(1,13):
month.append(calendar.month_name[i])
month
['January',
'February',
'March',
'April',
'May',
'June',
'July',
'August',
'September',
'October',
'November',
'December']이렇게 반복문으로 돌리면 들어가게 됩니다.
plt.figure(figsize=(15,5))
sns.barplot(x=hotel_df['arrival_date_month'],y=hotel_df['is_canceled'], order=month)
위 순서대로 데이터 정렬해주었습니다.
데이터들을 살짝 보니 겨울, 여름에는 취소율이 조금 높는것 같으니 독립변수로 가져갈 수 있을 것 같습니다.
sns.barplot(x=hotel_df['is_repeated_guest'],y=hotel_df['is_canceled'])
sns.barplot(x=hotel_df['deposit_type'],y=hotel_df['is_canceled'])
hotel_df['deposit_type'].value_counts()deposit_type
No Deposit 104641
Non Refund 14587
Refundable 162
Name: count, dtype: int64여태 일부로 하나하나 상관관계를 확인했지만 데이터가 더 많아지면 하나하나 확인할 수 없으니
corr함수를 사용하면 쉽게 확인할 수 있습니다.
hotel_df.corr(numeric_only=True)
sns.heatmap(hotel_df.corr(numeric_only=True), cmap='coolwarm', vmax=1, vmin=-1, annot=True)vmax = 최대값 vmin= 최소값
annot = 숫자를 체크해달라고 하는 의미

0일때는 관련이 없다는 뜻입니다.
1일때는 관련이 많다 라는뜻이니 독립변수를 넣을 수 있겠쬬
hotel_df.isna().mean()
결측치를 보고있습니다.
hotel_df = hotel_df.dropna()적은수이기때문에 날려버리도록 하겠습니다.
hotel_df.head()
아까 의심스러웠던 자료를 보려고 합니다
hotel_df[hotel_df['adults'] == 0]
어른들이 없는것이 몇개냐면 393개입니다.
어른이 없더라도 아이들만있더라도 인정하려고합니다.
캠프 이런걸수도있으니까요!
그래서 people이라는 파생변수를 만들어보도록 하겠습니다.
hotel_df['people'] = hotel_df['adults'] + hotel_df['children'] + hotel_df['babies']
hotel_df.head()다 더했더니 (표가 너무 길어서 생략) 파생변수가 만들어졌고
그러면 people파생변수가 0인 사람들을 보니
hotel_df[hotel_df['people'] == 0]170명이나 됩니다.
이 사람들을 제외해야겠죠?
hotel_df = hotel_df[hotel_df['people'] != 0]
hotel_df0이 아닌사람만 넣었더고 170명이 날라갔습니다.
hotel_df['total_nights'] = hotel_df['stays_in_weekend_nights'] + hotel_df['stays_in_week_nights']
hotel_df.head()파생변수를 또 만들었습니다.
만든 이유는 몇박 며칠을 묵는지 확인해보도록 하기 위함입니다.


토탈나이츠가 잘 만들어졌습니다.
여기서 월을 보면 달 이름으로 나와있는데 이것을 봄여름가을 겨울로 묶어주려고 하고
season이라는 파생변수를 만들려고 합니다.
#봄 여름 가을 겨울로 데이터그룹짓기
#season 파생변수
#arrival_date_month에 따라 아래와 같이 값을 저장
#12, 1, 2 : winter
#3, 4, 5 : spring
#6, 7 ,8 : summer
#9, 10 ,11 : Fallseason_dic = {'spring':[3,4,5], 'summer':[6,7,8], 'fall':[9,10,11], 'winter':[12,1,2]}
new_season_dic = {}
for i in season_dic:
for j in season_dic[i]:
new_season_dic[calendar.month_name[j]] = i
new_season_dic
결과가 잘 나온다는것을 확인할 수 있습니다.
hotel_df['season'] = hotel_df['arrival_date_month'].map(new_season_dic)
hotel_df.head()
hotel_df.info()
이 중에서 18번19번을 보면 내가 실제 룸타임, 배정된 룸타입이있습니다.
보통 다를때 취소률과 관련이 있을것같아서 확인해보겠습니다.
hotel_df['expected_room_type'] = (hotel_df['reserved_room_type'] == hotel_df['assigned_room_type']).astype(int)
hotel_df.head()두개가 일치하는지 안하는지에 대한 값을 확인해보려고합니다.

hotel_df['cancel_rate'] = hotel_df['previous_cancellations'] / hotel_df['previous_bookings_not_canceled']
hotel_df.head()
취소율이 NaN이 왜 나오는지 보니
0으로 나눠버리면 값이 되지않습니다.
hotel_df[hotel_df['cancel_rate'].isna()]NaN값을 보니 10만이나 있습니다.
아예 안왔다고 한 사람들은 파생변수로 신규생성합니다.
hotel_df['cancel_rate'] = hotel_df['cancel_rate'].fillna(-1)이제 -1로 바뀐값을 볼 수 있습니다.

hotel_df.info()
이 값들을 보면 오브젝트가 있고 이 부분을 바꾸어줘야합니다. 원핫인코딩으로 하면 좋은데
너무 많아서 다른방법으로 진행해보겠습니다,
hotel_df['hotel'].dtype다른건 다 int64, float64로 잘 나오는데
hotel만
dtype('O')
로 디타입이 정의됩니다.
obj_list = []
for i in hotel_df.columns:
if hotel_df[i].dtype == 'O':
obj_list.append(i)오브젝트만 거르는 과정입니다 리스트에 담는거죠
obj_list
for i in obj_list:
print(i, hotel_df[i].nunique())

오브젝트에 있는 카테고리의 갯수를 확인할 수 있습니다.
hotel_df.drop(['country', 'arrival_date_month'], axis=1, inplace=True)
obj_list.remove('country')
obj_list.remove('arrival_date_month')리스트와 df에서도 지워주기로 합니다.
두개 다 지워야 데이터를 사용할 수 있습니다.
그 다음에 이제 원핫인코딩을 하겠습니다.
hotel_df = pd.get_dummies(hotel_df, columns=obj_list)
hotel_df.head()
원핫인코딩이 잘 된것을 확인할 수 있습니다.
학습을 시켜주도록 하겠습니다.
X_train, X_test, y_train, y_test = train_test_split(hotel_df.drop('is_canceled', axis=1), hotel_df['is_canceled'], test_size=0.3, random_state=2024)test_size는 데이터가 많아서 0.3정도로 주었습니다.
X_train.shape, y_train.shape
#((83109, 64), (83109,))
X_test.shape, y_test.shape
#((35619, 64), (35619,))학습데이터와 테스트 데이터를 두개 나누는것까지 완료 했습니다.
2. 앙상블(ensemble)모델
- 여러개의 머신러닝 모델을 이용해 최적의 답을 찾아내는 기법을 사용하는 모델
- 보팅(Voting)
- 서로 다른 알고리즘 model을 조합해서 사용
- 모델에 대해 투표로 결과를 도출
- 배깅(Bagging)
- 같은 알고리즘 내에서 다른 sample 조합을 사용
- 샘플 중복 생성을 통해 결과를 도축
- 부스팅(Boosting)
- 약한 학습기들을 순차적으로 학습시켜 강력한 학습기를 만듦
- 이전 오차를 보완해가면서 가중치를 부여
- 성능이 우수하지만 잘못된 레이블이나 아웃라이어에 대해 필요이상으로 민감
- AdaBoost, Gradient Boosting, XGBoost, LightBGM
- 스태킹(Stacking)
- 다양한 개별 모델들을 조합하여 새로운 모델을 생성
- 다양한 모델들을 학습시켜 예측 결과를 얻은 다음, 다양한 모델들의 예측 결과를 입력으로 새로운 메타 모델을 학습
3. 랜덤 포레스트(Random Forest)
- 머신러닝에서 많이 사용되는 앙상블 기법 중 하나이며, 결정 나무를 기반으로 함
- 학습을 통해 구성해 놓은 결정나무로부터 분류 결과를 취합해서 결론을 얻는 방식
- 랜덤포레스트의 트리는 원본 데이터에서 무작위로 선택된 샘플을 기반으로 학습하게 됨.
- 각 트리가 서로 다른 데이터셋으로 학습되어 다양한 트리가 생성되며 모델의 다양성이 증가함
- 각각의 트리가 예측한 결과를 기반으로 다수결 또는 평균을 이용하여 최종 예측을 수행함
- 분류와 회귀 문제에 모두 사용할 수 있으며, 특히 데이터가 많고 복잡한 경우에 매우 효과적인 모델입니다.
- 성능은 꽤 우수한 편이나, 오버피팅이 되는 경우가 많습니다.(단점)
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(random_state=2024)
rf.fit(X_train, y_train)pred1 = rf.predict(X_test)
pred1
#array([1, 0, 0, ..., 1, 1, 1])
preba1 = rf.predict_proba(X_test)
preba1
#array([[0.06 , 0.94 ],
# [0.54833333, 0.45166667],
# [0.98 , 0.02 ],
# ...,
# [0.49 , 0.51 ],
# [0.06 , 0.94 ],
# [0. , 1. ]])
# 첫번째 테스트 데이터에 대한 예측 결과
preba1[0]
#array([0.06, 0.94])
# 모든 테스트 데이터에 대한 호텔 예약을 취소할 확률만 출력
preba1[:, 1]
#array([0.94 , 0.45166667, 0.02 , ..., 0.51 , 0.94 ,
# 1. ])4. 머신러닝/딥러닝에서 모델의 성능을 평가하는데 시용하는 측정값
- Accuracy: 올바른 예측의 비율
- Precision : 모델에서 수행한 총 긍정 예측 수에 대한 참 긍정 예측의 비율
- Recall : 실제 긍정 사례의 총 수에 대한 참 긍정 예측의 비율
- F1 Score : 정밀도와 재현율의 조화평균이며, 정밀도와 재현율 간의 균형을 맞추기 위한 단일 메트릭으로 사용
- AUC-ROC Curve: 참양성률(TPR)과 가양성률(FPR)간의 균형을 측정


- AUC = 1
- 두 개의 곡선이 전혀 겹치지 않는 경우 모델은 가장 이상적인 분류 성능을 보임
- 양성 클래스와 음성 클래스를 완벽하게 구별할 수 있음
- AUC = 0.75
- 설정한 threshold에 따라 오류값들을 최소화 또는 최대화할 수 있음
- 해당 분류 모델이 양성 클래스와 음성 클래스를 구별할 수 있는 확률이 75%임을 의미
- AUC = 0.5
- 분류 모델의 성능이 최악인 상황
- 해당 분류 모델은 양성 클래스와 음성 클래스를 구분할 수 있는 능력이 없음
이것을 계산할 수 있는 모듈을 사용할 수 있습니다.
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report, roc_auc_scoreaccuracy_score(y_test, pred1)
#0.8643420646284287
confusion_matrix(y_test, pred1)
#array([[20709, 1659],
# [ 3173, 10078]])confusion_matrix을 사용하는 이유는 학습이 잘못됐을지 확인하기위해서 사용하게됩니다.
한쪽으로 쏠린 데이터가 아닌것을 확인할 수 있습니다.
예) 암진단 확률이 5%라서 아니라고 해도 95% 맞춘다는 예시를 생각하기.
print(classification_report(y_test, pred1))
roc_auc_score(y_test, proba1[:, 1])
#0.9315576511541386거의 1에 가까우니 어느정도 잘 맞추고 있다는것을 확인할 수 있습니다.
번외
하이퍼 파라미터 max_depth=30 적용해서 수정해보기
rf2 = RandomForestClassifier(max_depth=30, random_state=2024)
rf2.fit(X_train, y_train)
proba2 = rf2.predict_proba(X_test)
roc_auc_score(y_test, proba2[:,1])
#0.9319781899069026
#하이퍼 파라미터 수정 후
0.9319781899069026 - 0.9315576511541386
#0.0004205387527640436
# 하이퍼 파라미터 수정(max_depth=30, min_samples_split=5, n_estimators=120을 적용)
rf3 = RandomForestClassifier(max_depth=30, min_samples_split=5, n_estimators=120, random_state=2024)
rf3.fit(X_train, y_train)
proba3 = rf3.predict_proba(X_test)
roc_auc_score(y_test, proba3[:,1])
#0.931059217235636
#하이퍼 파라미터 추가 수정 후
0.931059217235636 -0.9319781899069026
#-0.0009189726712666157하이퍼 파라미터 추가 수정후에는 성능이 더 안 좋아지는 경우도 볼 수 있습니다.
즉 하이퍼 파라미터는 조합을 해봐야 알 수 있습니다.
5. 하이퍼 파라미터 최적의 값 찾기
- GridSearchCV: 원하는 모든 하이퍼 파라미터를 적용하여 최적의 값을 찾음
- RandomizedSearchCV: 원하는 모든 하이퍼 파라미터를 지정하고 n_iter 값을 설정하여 해당 수 만큼 random하게 조합하여 최적의 값을 찾음
from sklearn.model_selection import GridSearchCV, RandomizedSearchCV
params = { 'max_depth' : [30,40],
'min_samples_split' : [2, 3],
'n_estimators' : [100, 120]
}
학습시키기
rf4 = RandomForestClassifier(random_state=2024)
grid_df = GridSearchCV(rf4, params)
grid_df.fit(X_train, y_train)* cv = 교차검증이라서 cv를 넣어도 됩니다. 단 검증시간은 더욱 길어지겠죠
grid_df.cv_results_
맨 마지막 rank_Test_score을 보면 각각 결과에 대한 rank를 확인시켜줍니다
즉 1이라고 쓰여있는 위치에 있는 값이 가장 베스트 파라미터인거죠.
최적의 파라미터 찾기
rand_df.best_params_
#{'n_estimators': 120, 'min_samples_split': 2, 'max_depth': 30}
랜덤으로 돌려보기(학습)
rf5 = RandomForestClassifier(random_state=2024)
rand_df = RandomizedSearchCV(rf5, params, n_iter=3, random_state=2024)
rand_df.fit(X_train, y_train)랜덤으로 모든조합으로 3개를 뽑아달라는 의미입니다.
결과보기
rand_df.cv_results_
최적의 파라미터 찾기
rand_df.best_params_
#{'n_estimators': 120, 'min_samples_split': 2, 'max_depth': 30}위에서 나온 랭크테스트스코어랑 같은 값을 확인할 수 있습니다.
위에 나온 값들을 그래프로 만들어보기
import matplotlib.pyplot as plt
from sklearn.metrics._plot.roc_curve import roc_curveproba5 = rand_df.predict_proba(X_test)
fpr, tpr, thr = roc_curve(y_test, proba5[:, 1])
print(fpr, tpr, thr)
그래프를찍는 점들에 대한 값
| [0.00000000e+00 4.47067239e-05 4.47067239e-05 ... 9.43445994e-01 9.44071888e-01 1.00000000e+00] [0. 0.36374613 0.36427439 ... 0.99901894 0.99901894 1. ] [2.00000000e+00 1.00000000e+00 9.99806202e-01 ... 5.14403292e-05 2.62881178e-05 0.00000000e+00] |
plt.plot(fpr, tpr, label='ROC Curve')
plt.plot([0,1],[0,1])
plt.show()

6. 피처 중요도(Feature Importances)
- 결정 나무에서 노드를 분기할 때 해당 피처가 클래스를 나누는데 얼마나 영향을 미쳤는지 표기하는 척도
- 0에 가까우면 클래스를 구분하는데 해당 피처의 영향이 거의 없다는 것이며, 1에 가까우면 해당 피처가 클래스를 나누는데 영향을 무척이나 많이 주었다는 이야기가 됩니다.
# proba5 = rand_df.predict_proba(X_test)
roc_auc_score(y_test, proba5[:,1])
#0.9321130101499074
# {'n_estimators': 120, 'min_samples_split': 2, 'max_depth': 30}
rf6 = RandomForestClassifier(random_state=2024, max_depth=30,
min_samples_split=2, n_estimators=120)
rf6.fit(X_train, y_train)
proba6 = rf6.predict_proba(X_test)
roc_auc_score(y_test, proba6[:,1])
#0.9321130101499074random, max_depth, min_sample_split, n_estimators을 넣은 값은 최적의 값이라서 넣은것입니다.
그 뒤로 rf6를 학습시키고 roc_auc_score의 값을 내보면
0.92~~~가 나오게 됩니다.
proba6
rf6.feature_importances_
피처중요도를 뽑아보면 이렇게 나옵니다.맨 앞에껏을 따로 보면 e가 숫자로 나오게됩니다.
랜덤포레스트를 하면서 호텔 관련한 피처중요도입니다. 각각 하나가 첫번쨰 컬럼의 중요도로 볼 수 있습니다.
그래서 중요도를 한 번에 확인할 수 있습니다.
그런데 이렇게보면 어떤게중요한지 한 눈에 볼 수 없습니다.
그래서 판다스를 이용해서 시각화해보도록 하려고 합니다.
feature_imp = pd.DataFrame({
'features': X_train.columns,
'importances': rf6.feature_importances_
})feature_imp
top10 = feature_imp.sort_values('importances', ascending=False).head(10)
top10ascending=false로 해주어야 내림차순으로 됩니다.

오래기다리면 기다릴수록 취소학 확률이 적다라는것을 확인할 수 있습니다.
plt.figure(figsize=(5,10))
sns.barplot(x='importances', y='features', data=top10, palette='Blues_r')
paltette는 당연히 옵션이고 굉장히 많기떄문에 더 예쁘게 시각화시킬 수 있습니다.
Set1,2 등 다양하게 있지만 저는 Blues_r로 했습니다.
'데이터 분석 및 시각화' 카테고리의 다른 글
| [데이터분석] 데이터 정제(전처리), 그래프 종류 확인 및 실습해보기 (0) | 2024.08.05 |
|---|---|
| [데이터분석] 판다스 활용하기, json파일 가져와서 데이터 나눠보기 (0) | 2024.08.03 |
| [ML] 서포트 벡터 머신(SVM),스케일링을 통한 손글씨 데이터셋만들어보기 (1) | 2024.07.08 |
| [ML] 의사 결정 나무(decision tree)_bike 데이터 활용(2) (0) | 2024.07.06 |
| [ML] 의사 결정 나무(decision tree)_bike 데이터 활용 (1) | 2024.07.05 |



