1. 객체탐지(Object Detection)
- 컴퓨터 비전과 이미지 처리와 관련된 컴퓨터 기술로서, 디지털 이미지와 비디오로 특정한 계열의 시멘틱 객체 인스턴스를 감지하는 일
- 예시) 보행자 검출, 동물, 사물 검출 등이 포함되는 일
- 박스로 탐지하는 역할입니다 큰 박스로 객체를 탐색하는것!!!
2. 컴퓨터 비전의 Task 비교
- Image classfication: 이미지(영상)에 있는 객체 범주 목록 생성
- 더러운방VS깔끔한 방, 산타VS일반인
- Single-Object Localization: 이미지에 있는 객체 범주의 한 인스턴스의 위치와 배율을 나타내는 Bounding Box를 생성하는 일
- 하나의 오브젝트가 어디에 존재하는지? 위치를 찾아주고 검출해주는것
- Object Detection: 각 객체 범주의 모든 인스턴스의 위치와 배율을 나타내는 경계 상자와 함께 이미지에 있는 객체 목록을 생성
-
물론 더 누끼딴것처럼 하는걸수도있지만... 그것은 또 굉장히 연산량이 크고 느리다.
TASK에 맞게 사용하면 됩니다.
예를들어 자율주행 자동차가 사람 객체만 감지되면 멈출 수 있는데 굳이 그 사람을 100% 완벽하게 누끼를 딸 필요는 없다.
3. One-Stage 모델
- Resion Proposal(객체가 있을법한 곳에 바운딩을 치는 것 그 후 지워나가면서 찾는 것)과 Dectection(실제 객체가 사람,동물,자동차 등을 알려주는것)이 한 번에 수행 / 각각 수행하는 것도있긴함
- YOLO(You Only Look Once): 2015년 제안된 객체 검출 모델로 이미지 전체를 단일 그리드로 나누고, 각 그리드 셀마다 여러 개의 바운딩 박스와 클래스를 예측하는 방식
>> 원스테이지 모델 중에서도 욜로가 가장 유명한 모델

4. YOLO (ONE- Stage 모델 중 가장유명한 모델)
옵션을 뭘 주는지에 따라 각각 이미지분류, 객체탐지, 인스턴스,세그멘테이션작업 가능
- 이미지 분류, 객체 탐지, 인스턴스 분할 작업에 사용할 수 있는 모델
- 초기버전(1~4)에서는 Redmond가 작성한 커스텀 딥러닝 프레임워크인 Darknet에서 유지보수가 됐었음
- Ultralytics에서 YOLOv3를 가져다가 레포를(공개) Pytorch로 작성하여 출시를 함(YOLOv5)
- 유연한 Python구조 덕분에 YOLOv5는 SOTA 레포가 되었음
- Ultralytics는 2023년 1월에 YOLOv8을 출시(안정적이기때문에 많이 사용함)
- 아키텍처
리디렉션 알림
www.google.com
SOTA 레포: 가장 뛰어난 성능을 보이는 것 SOTA는 시간이 지나고 더 좋은 모델이 나오면 바뀔수도 있음.
24년는 v10까지 나옴.. 9,10은 울트라틱스에서만든것은 아님!
욜로의 기능이 정말 많아서 사용방법만 알면 프로젝트에서도 많은 도움을 받을 수 있음!!!!!!
5. PascalVOC 2007 데이터셋
- 분류와 객체 검출을 위해 만들어진 데이터셋 (연습하라고 만든것)
- 총 20개의 클래스를 가지고 있음
- Person: person
- Animal: bird, cat, cow, dog, horse, sheep
- Vehicle: aeroplane, bicycle, boat, bus, car, motorbike, train
- Indoor: bottle, chair, dining table, potted plant, sofa, tv/monitor
6. YOLO 실습
- PascalVOC 2007 데이터셋
- train: 2501장, val: 2510장
- test: 4952장
- 학습 데이터가 너무 적어서 train과 val을 합쳐서 학습시킨 후, 테스트 데이터를 검증 데이터셋으로 사용, 테스트는 직접 만들어서 사용
- 테스트는 직접 별도로 가져와서 테스트를 해 볼 예정입니다. 그 과정에서 어노테이션도 만들어보고 반 자동시키는 툴을 이용하며 반자동화해보려고 합니다.
#해당 URL에서 파일을 다운로드하라는 명령
#VOCtrainval = 트레인+벨리드 합쳐있는 파일
!wget http://pjreddie.com/media/files/VOCtrainval_06-Nov-2007.tar
#테스트 데이터를 뽑기
#VOCtest_06 테스트데이터
!wget http://pjreddie.com/media/files/VOCtest_06-Nov-2007.tar각각web get을 이용해서 trainval, test의 데이터들을 다운로드 해줍니다.

파일이 다운로드 된것을 확인했습니다.
디렉토리 구조
pascal_datasets
pascal_datasets/trainval
pascal_datasets/test
pascal_datasets/VOC
pascal_datasets/VOC/images
pascal_datasets/VOC/labels
pascal_datasets/VOC/images/train2007
pascal_datasets/VOC/images/val2007
pascal_datasets/VOC/images/test2007
pascal_datasets/VOC/labels/train2007
pascal_datasets/VOC/labels/val2007
pascal_datasets/VOC/labels/test2007처럼 각 디렉터리 구조를 이렇게 만들것입니다.

트리로 그려보면 위 그림처럼 그릴 수 있겠습니다.
물물론 그냥 파일을 수기로 만들수도 있지만 리눅스환경에서처러 파일 디렉토리를 직접 코드로 만들어보겠습니다.
#코드로 폴더 만들기
#Path함수를 통해서위치를 계산할 수 있는 객체를 만들어낼 수 있음
from pathlib import Path
Path함수를 통해서 위치를 계산할 수 있는 객체를 만들어 낼 수 있습니다.
#가장 상위 루트 설정
root = Path('./pascal_datasets')가장 상위 루트를 pascal_datasets로 잡아줍니다.
여기서 주의해야할것은 경로를 생성할뿐이지 실제 디렉토리를 생성하지는 않는다는점입니다.
디렉토리를 생성하려면 mkdir() 메서드를 사용해야합니다.
Path('./pascal_datasets/trainval').mkdir(parents=True, exist_ok=True)
Path('./pascal_datasets/test').mkdir(parents=True, exist_ok=True)간단하게 말하면 trainval의 폴더를 만들어주는 역할을 합니다.
조금 디테일하게 이야기를 하자면 mkdir은 디렉터리를 만들어주는 역할을 하고 path경로에 입력을 해주고 나면
에러를 만납니다. pascal_datasets가없기때문이죠.
그래서 parents=True 를 넣어서 pascal_datasets(부모파일)이 없어도 에러없이 만들어 줄 수 있도록 만들어줍니다.
또한 exist_ok = True는 파일이 이미 있어도 그냥 에러없이 넘기라고 하는겁니다.
즉! 만약에 없으면 만들고 있으면 말아라 라는 명령 입니다. (중복으로 디렉토리 생성하지않음)
그 아래 똑같이 test도 만들어 줍니다.
그런데 여기서 root는 경로를 단순히 지정해주는것이고 밑에 mkdir을 통해서 어차피 만들어지는데 왜 경로를 지정하냐?
라고 생각할 수 있는데 경로의 재사용성을 높이기 위해서라고 합니다.
나중에 경로가 복잡해질수록 실수도 줄이고 코드 유지보수도 좀 더 편해진다고 합니다.

지금까지 이렇게 pascal_datasets안에 test와 trainval폴더를 만들어주었습니다.
이제 모든 데이터셋안에 voc폴더를 만들어주고 각 각 아래 트리를 만들어주어야합니다.
for path1 in ('images', 'labels'):
for path2 in ('train2007', 'val2007', 'test2007'):
new_path = root / 'VOC' / path1 / path2
new_path.mkdir(parents=True, exist_ok = True)
파일을 for문을 통해 자동화로 만들었습니다.
각각 path1,2를 돌면서 images, labels에 train2007,val2007, test2007을 넣어주고
경로를 지정해줍니다. 그 다음에 디렉토리를 만들어줍니다.
# 압축 풀기
!tar -xvf VOCtrainval_06-Nov-2007.tar -C ./pascal_datasets/trainval/
!tar -xvf VOCtest_06-Nov-2007.tar -C ./pascal_datasets/test/VOCtrainval_06-Nov-2007.tar 압축을 풀어서
./pascal_datasets/trainval/ 폴더로 넣어달라는 의미입니다.
터미널 명령어고 압축을 잘 풀어서 넣어주는것을 확인할 수 있습니다.

그 후 pascal_datasets -> trainval -> VOCdevkit -> voc3007 -> annotation 을 보게되면 어노테이션
즉 주석이 있는걸 볼 수 있습니다. 이것은 모두 이미지에 따른 어노테이션입니다.
보통은 json형태로 되어있는데 이것은 XML로 되어있습니다. 그 중하나를 메모장으로 열어보면
HTML구조처럼 되어있습니다.
위 정보들을 가지고 프로그램이나 ai에서 읽어와서 안에있는 데이터들을 쏙쏙 빼갈 수 있는 형태를 xml이라고합니다.

여기있는 데이터를 가져오려면 xml전체적으로 읽어서 원하는 부분을 쏙 빼면 됩니다.
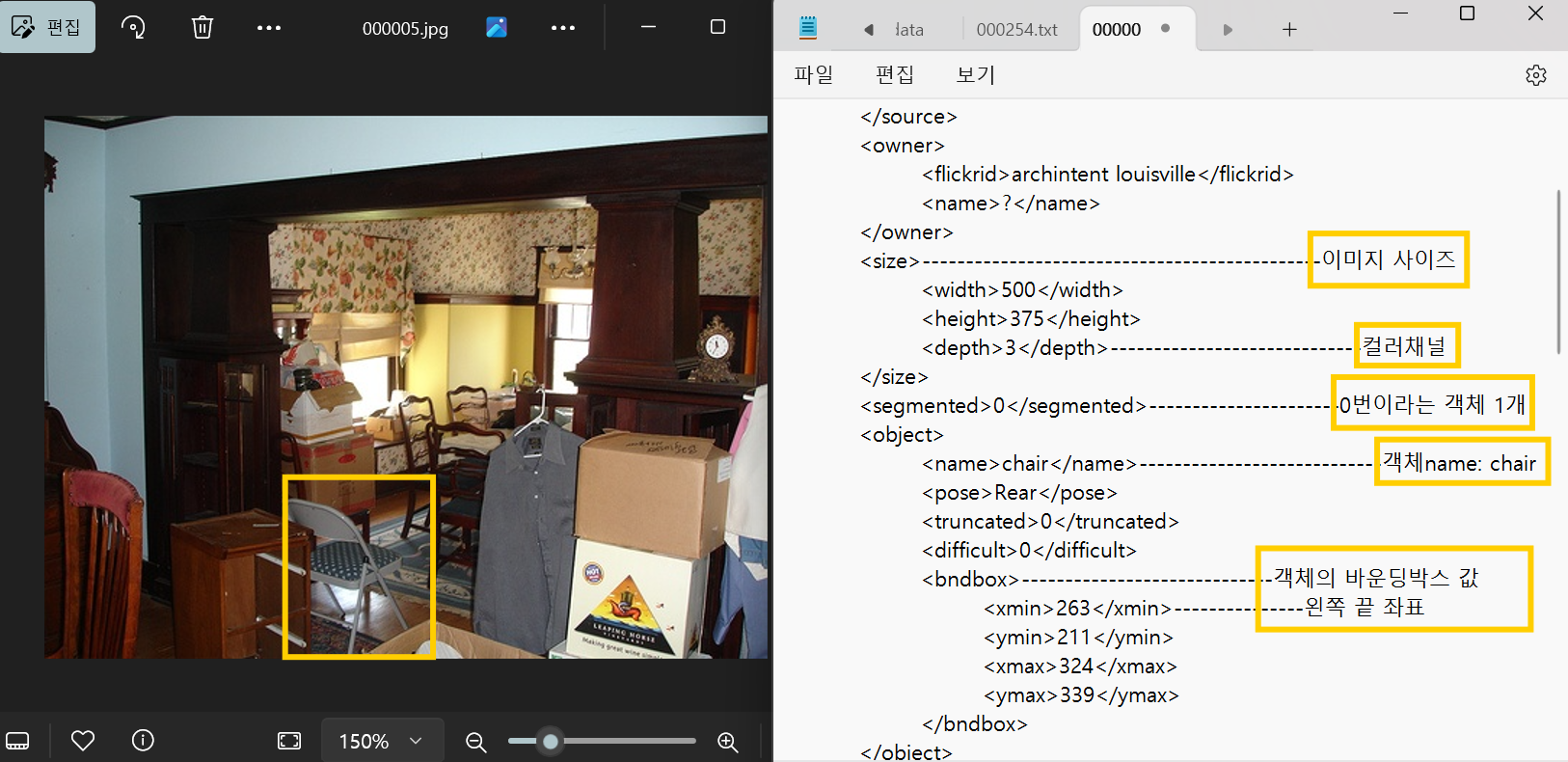
조금더 디테일하게 보자면 이렇게 됩니다. 저 한객체에 대한 바운딩박스를 확인할 수 있습니다.
여기서 맨날 나오면 쪼는(?)게 있는데 바로 x,y의 거리구하기 입니다.
(노랑색 네모는 임의로 바운딩한것)

이렇게 바운딩 박스를 확인할 수 있습니다.
즉 Width값 = 324-263, height값 =339-211
XML에서 (Xmin, Ymin, XMax, YMax)을 YOLO모델에서 사용하기 위해서는 포멧 변경이 필요합니다.
위 형식은 two-stage모델에서 사용되는 형식이고 YOLO는 저 형식으로 했을때 에러가 납니다.
YOLO형식은 : 클래스번호, X의 Center좌표, Y의 Center좌표, 너비, 높이
이걸 가지고 어노테이션작업을 을 해줘야 yolo에서 디텍션 작업(감지)이 가능합니다.
누군가 만들어놓은 알고리즘이 있기때문에 깃허브에서 가져와서 사용하도록 하겠습니다.
| XML->YOLO 형식변환 | !git clone https://github.com/ssaru/convert2Yolo.git |
깃허브에서 콜론을 하면 폴더를 만들고 그 데이터를 폴더 안으로 쭉 가져오게됩니다.


이걸 실행하려면 내가 폴더 안쪽으로 실행하려면 내가 실행한 폴더로 들어가야됩니다.
%cd convert2Yolo/그럼 컨텐츠에서 저 폴더로 들어갔다는 이야기입니다.
폴더 중 requirements.txt 를 열어보면

이렇게 나오는데 각 임포트/버전을 사용해놓은겁니다.(의존성 이라고 함)
설치하는것도 되게 편합니다.
%pip install -qr requirements.txt이렇게 쓰면 알아서 다 설치해줍니다. (각 버전에 맞춰서 설치해줍니다)

설치를 하고나면 이렇게 example.py를 실행시켜주어야 합니다.
눌러서 설치하는게 아니라 밑에 보면 !python3 example.py --datasets VOC~~로 시작하는거 코드있으니, 그거 보면됨
(이유는 제작자가 그렇게 하라고했기때문에 깃허브에 나와있음)
그래서 설치를 하면 충돌나는게 있을수도있습니다. 그렇지만 충돌 error는 넘어가도 됩니다.(정상작동함)

우선 example.py를 실행하기 전에 그 파일의 역할이 한번에 떠오르지 않아서 다시 정리하겠습니다.
어노테이션파일을 YOLO형식으로 변환하는 역할을 하는것!!
- example.py는 xml파일을 yolo형식의 txt파일로 변환해줌
- 각 이미지에 대한 객체의 경계 상좌 좌표를 yolo 형식으로 변환함
- 변환된 라벨 파일을 지정된 경로에 저장함
이고 현재 상황에서는
지금 annotation이 xml파일로 있으니 yolo가 지원하는 txt파일, 구조로 변환을 해야합니다.
그렇게 해주는 알고리즘을 깃에서 가져온겁니다.
7. names파일(클래스 이름)
- 머신러닝, 딥러닝 모델이 데이터셋 내의 클래스를 인식하고 구분할 수 있도록 클래스 이름을 정의한 파일 형식입니다.
- YOLO와 같은 유명한 객체 탐지 알고지즘을 구현하는데 제공
- open은 txt로 메모장으로 열면 됩니다.

이것들은 데이터셋에 있는 클래스를 쭉 나열해서 저장해놓았습니다.
yolo모델을 이용해서 구별을 해준다고 했을때 사용할 수 있는 클래스 이름입니다.
이 파일을 conver2Yolo폴더에 넣어줍니다.
위 names파일을이용해서 example.py를 실행해줄겁니다.
리눅스의 파이썬 기본버전입니다. 현재 %cd 현재 경로에 있어서 가능합니다.
!python3 example.py --datasets VOC --img_path /content/pascal_datasets/trainval/VOCdevkit/VOC2007/JPEGImages --label /content/pascal_datasets/trainval/VOCdevkit/VOC2007/Annotations --convert_output_path /content/pascal_datasets/VOC/labels/train2007 --img_type ".jpg" --manifest_path /content --cls_list_file ./voc.names| 모듈실행방법 | !python3 example.py |
| yolo 에서 실행한 것 |
!python3 example.py --datasets VOC --img_path /content/pascal_datasets/trainval/VOCdevkit/VOC2007/JPEGImages --label /content/pascal_datasets/trainval/VOCdevkit/VOC2007/Annotations --convert_output_path /content/pascal_datasets/VOC/labels/train2007 --img_type ".jpg" --manifest_path /content --cls_list_file ./voc.names |
조금 자세히 설명하면
!python3 example.py : 모듈 실행
--datasets VOC : 어떤 데이터셋?
--img_path :이떤거? 경로는?
--label : 라벨경로
--convert_output_path : 컨버팅 된거 어디다 저장할거임?
--img_type (이미지타입): 이미지타입은? "jpg" 라고 적어줍니다.
--manifest_path: 이미지와 라벨의 목록을 포함한 데이터 파일의 경로
즉 파일들이 어떻게 구성되어있는지 기록한 파일이나 루트 디렉토리입니다.(컨텐트 안에있다)
--cls_list_file : 클래스가 뭐가있는지 알려주는것 (현재경로의 voc.names가 가지고있다는 뜻)
이라고 보면 됩니다.
전체 경로가 content니까 쭈욱 경로복사를 해오면 됩니다.

pascal_datasets 안에 voc안에 labels안에 train2007안에 보면 txt파일이 있습니다.
원래는 xml파일이었는데 yolo에서 사용할 수 있는 txt파일로 변환된것입니다.
또한 test도 함께 만들어줍니다.
!python3 example.py --datasets VOC --img_path /content/pascal_datasets/test/VOCdevkit/VOC2007/JPEGImages --label /content/pascal_datasets/test/VOCdevkit/VOC2007/Annotations --convert_output_path /content/pascal_datasets/VOC/labels/test2007 --img_type ".jpg" --manifest_path /content --cls_list_file ./voc.names
작업이 하나 덜 된게 있습니다. valid2007에는 아무것도 없습니다.
train/val이 같이들어있는데 train은 있는건 냅두고 val가 합쳐져있는건 val2007로 넘기겠습니다.
8. PascalVOC 제공 파일로 train, val 라벨 분할
/content/pascal_datasets/trainval/VOCdevkit/VOC2007/ImageSets/Main/val.txt (txt파일 경로)파일을 읽어서
/content/pascal_datasets/VOC/labels/train2007 파일 중 txt문서에 있는 파일이름을
/content/p ascal_datasets/VOC/labels/val2007 옮기기


여기 디렉토리 루트를 보면 val.txt가 있습니다.
val.txt는 valid로 쓰라는 것입니다. train/val을 함께 해놨기때문에 분리 후 나눠주는겁니다.
여기서 좀 이해가 안갔던건 어차피 다 txt파일로 변환을 했기때문에 다 txt 문서인데 왜 val로 다 옮기는지가 궁금했습니다.
그런데 모든 txt파일을 옮기는것이아니라 val..txt에 있는 파일 이름과 일치하는 텍스트 파일만 골라서 옮기는것입니다!!!
#pascal data파일 train, val라벨 분할하기
import shutil
import os
path= '/content/pascal_datasets/trainval/VOCdevkit/VOC2007/ImageSets/Main/val.txt'
with open(path) as f:
image_ids = f.read().strip().split()
for id in image_ids:
ori_path = '/content/pascal_datasets/VOC/labels/train2007/'
my_path = '/content/pascal_datasets/VOC/labels/val2007'
shutil.move(f'{ori_path}/{id}.txt', f'{my_path}/{id}.txt')이 부분의 코드는
path= '/content/pascal_datasets/trainval/VOCdevkit/VOC2007/ImageSets/Main/val.txt'path를 지정해서 있는 파일경로지정
with open(path) as f:
image_ids = f.read().strip().split()1. with open(path) as f:
이 줄은 path 경로에 있는 파일을 열어서 사용할 준비를 하는 구문입니다.
- path: 파일 경로를 담고 있는 변수예요. 이 경로에 있는 파일을 엽니다. 여기서 파일은 **val.txt**일 거예요.
- with: 파일을 열고 사용한 후, 자동으로 파일을 닫아주는 역할을 합니다. 수동으로 닫을 필요가 없어서 실수를 줄일 수 있어요.
- as f: 파일 객체를 **f**라는 이름으로 사용할 수 있게 해 줍니다.
for id in image_ids:
ori_path = '/content/pascal_datasets/VOC/labels/train2007/'
my_path = '/content/pascal_datasets/VOC/labels/val2007'
shutil.move(f'{ori_path}/{id}.txt', f'{my_path}/{id}.txt')2. image_ids = f.read().strip().split()
이 줄은 **f**로 열린 파일(아마 val.txt)의 내용을 읽어와서 처리하는 부분입니다.
- f.read(): 파일의 전체 내용을 읽습니다. 즉, val.txt 안에 있는 모든 텍스트를 가져오는 작업입니다.
- .strip(): 앞뒤에 있는 공백 문자(스페이스, 줄바꿈 등)를 제거합니다. 이렇게 하면 텍스트 앞뒤의 불필요한 공백이나 빈 줄을 제거할 수 있습니다.
- .split(): 텍스트를 공백(스페이스나 줄바꿈) 기준으로 쪼개서 리스트로 만듭니다. 여기서는 val.txt 안에 있는 각 이미지 ID들을 리스트로 만들게 됩니다.
3. for id in image_ids:
이 줄은 image_ids 리스트 안에 있는 각 파일 이름(ID)을 하나씩 가져와서 반복 작업을 하겠다는 의미입니다.
- id: image_ids 리스트에서 하나의 파일 이름을 가져와서 id 변수에 저장합니다.
- 이 for문은 image_ids 리스트에 있는 모든 파일 이름에 대해 반복적으로 작업을 수행할 준비를 하는 부분입니다.
즉, val.txt에 있는 각 이미지 ID에 대해 반복 작업을 하겠다는 의미입니다.
4. ori_path = '/content/pascal_datasets/VOC/labels/train2007'
이 줄은 **원본 경로(출발지 경로)**를 설정하는 부분입니다.
- **ori_path**는 파일이 현재 저장되어 있는 디렉토리 경로입니다. 이 경로는 train2007 폴더를 가리키며, 이곳에 있는 라벨 파일들을 **val2007**으로 옮길 예정입니다.
5. my_path = '/content/pascal_datasets/VOC/labels/val2007'
이 줄은 파일을 옮길 대상 경로를 설정하는 부분입니다.
- **my_path**는 파일을 옮기고자 하는 목적지 경로입니다. 여기서는 val2007 폴더로 옮기려고 합니다.
즉, **my_path**는 파일이 옮겨질 폴더를 의미합니다.
6. shutil.move(f'{ori_path}/{id}.txt', f'{my_path}/{id}.txt')
이 줄은 shutil.move() 함수를 사용해서 파일을 이동하는 부분입니다.
- f'{ori_path}/{id}.txt': 원본 경로에 있는 id.txt 파일을 나타냅니다.
- id는 val.txt에 있는 이미지 ID이고, 이 ID에 해당하는 라벨 파일(예: 000001.txt)을 train2007 폴더에서 찾습니다.
- f'{my_path}/{id}.txt': 옮길 대상 경로인 val2007 폴더에 해당 파일을 저장할 경로를 나타냅니다.
9. VOC/labels에 맞게 images 분할하기
/content/pascal_datasets/trainval/VOCdevkit/VOC2007/JPEGImages 와
/content/pascal_datasets/test/VOCdevkit/VOC2007/JPEGImages에서 이미지를 가져와 디렉토리에 맞게 저장하기
>> 이미지들을 가져와서 비어있는 아래 사진의 폴더에 각각 맞춰서 넣어주는것입니다.

path = '/content/pascal_datasets'
for folder, subset in ('trainval', 'train2007'), ('trainval', 'val2007'), ('test', 'test2007'):
ex_imgs_path = f'{path}/{folder}/VOCdevkit/VOC2007/JPEGImages'
label_path = f'{path}/VOC/labels/{subset}'
img_path = f'{path}/VOC/images/{subset}'
print(subset, ": ", len(os.listdir(label_path)))
for lbs_list in os.listdir(label_path):
shutil.move(os.path.join(ex_imgs_path, lbs_list.split('.')[0]+'.jpg'),
os.path.join(img_path, lbs_list.split('.')[0]+'.jpg'))train2007 : 2501 val2007 : 2510 test2007 : 4952
10. 커스텀 데이터 준비하기
1. cvat이라는 사이트를 이용합니다.
CVAT
Powerfull and efficient open source data annotation platform for computer vision datasets
www.cvat.ai
2. cavt -> 프로젝트 생성

3.라벨정보입력 (라벨,색상지정)
프로젝트를 만들고 어노테이션 할 이름들을 각각 넣어줍니다.
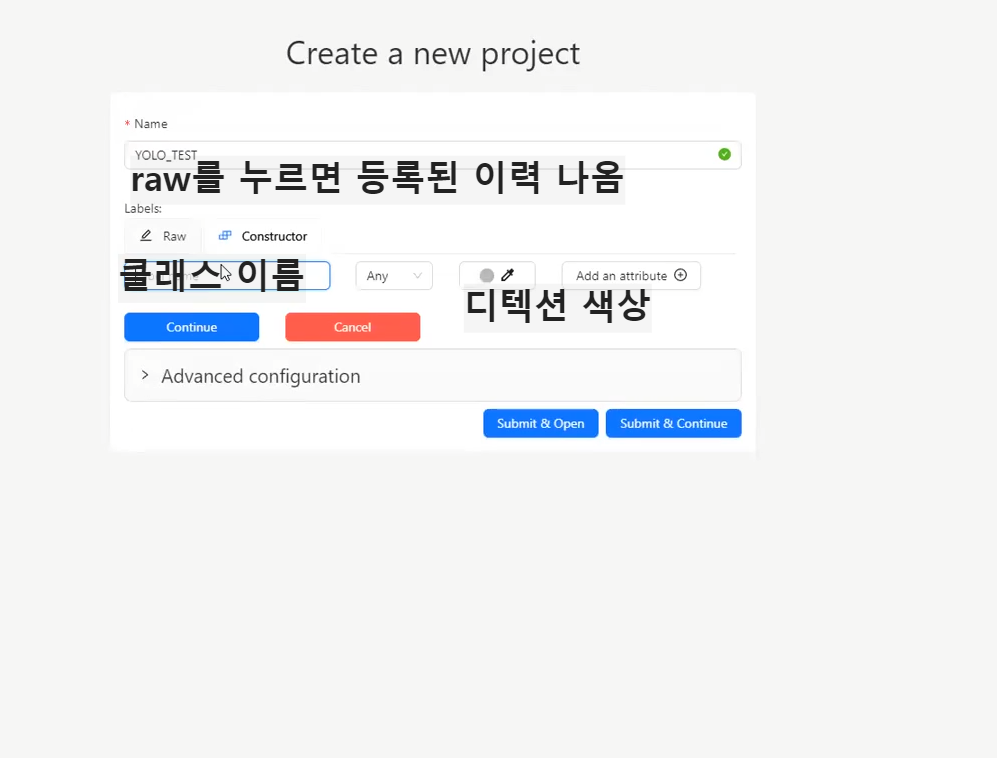
디텍션(발견,감지)하는 색은 그냥 순서대로 나열했습니다
4. 새로운 task생성.

어노테이션이 잘 된것을 확인할 수 있습니다.
5. 이미지 업로드


반자동 어노테이션을 해서 test데이터를 만드는 중이니 select files에 직접 테스트 할 파일들을 올려줍니다.
다 올린 후 summit open을 눌러줍니다.
디텍션 -> 바운딩박스
세그메테이션테스크 -> 누끼따기
지금은 v5로 오브젝트 디텍션 문제를 할거고 간단하게 바운딩 박스를 치려고 합니다.
6. 이미지 데이터 경계상자 라벨링

이런것처럼 바운딩 박스를 쳐주면 됩니다.
왜 하느냐?
반자동 어노테이션을 하는 작업이기때무에 진행하고있고, 이렇게 저장해놓으면 자동으로 이 값들이 좌표들이 저장되어서
사용할 수 있습니다.
7.라벨링 결과물 저장

8. menu-> Export job dataset -
9. yolo 1.1을 선택 후 yolo 포멧으로 export

그 다음 상단에 requests를 보면 내가 저장한 어노테이션이 나오고 우측 점 3개 -> 다운로드
를 통해서 .zip으로 다운받을 수 있습니다.
다운로드 후 압축을 풀어보면

이렇게 각 파일별로 되어있고
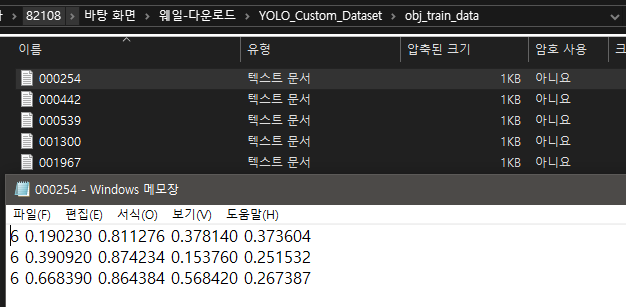
이렇게 반자동으로 좌표값을 만들어놓은것을 볼 수 있습니다.
여기까지 이제 test할 자료들을 만들었다고 볼 수 있습니다.
11. YOLO모델 불러오기
현재 내가 있는 위치를 content로 맞춰주고 깃허브에 yolo 모델이 있어서 클론해오기로 합니다.
## YOLO모델 불러오기
%cd /content/!git clone https://github.com/ultralytics/yolov5실행하면 yolo5 폴더가 생성됩니다.
다시 욜로5 폴더로 가겠습니다.
%cd yolov5필요한 모듈 설치(콜론)
!pip install -qr requirements.txt필요한 모듈 설치
import torch
12. WanDB를 이용한 학습 및 평가 과정 로깅
WanDB
Weights & Biases: The AI Developer Platform
Weights & Biases is the leading AI developer platform to train and fine-tune models, manage models from experimentation to production, and track and evaluate GenAI applications powered by LLMs.
wandb.ai
머신러닝/딥러닝 개발자들을 위한 종합적인 보조 도구!
딥러닝 모델 학습할 때 학습 과정에 대해 로깅(기록들을 담는 행위)을 진행!
손실값의 감소하는 형태를 쉽게 파악할 수 있음!
팀 단위로 실험 결과를 추적할 수 있도록 해주기 때문에 웹에서 편리하게 분석이 가능!
학습할때 돌리면 외부에 저장하는 사이트가 완DB입니다.
!pip install wandbimport wandbwandb.login()13. 실험이 재현성 보장
랜덤으로 나올 수 있는 값을을 모두 고정시켜주는 과정입니다.
seed= 2024
deterministic = True
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
if deterministic
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark=Truedeterministic = True 는 간단하게 gpu에서 좀 더 연산할때 속도가 난다고 알고 있으면 됩니다.
만약 true로 되면 cudnn.derministc 에서동일한 입력에 대해 항상 동일한 결과를 보장합니다.
동일한 데이터가 들어오면 동일한 웨이트값이 수정되게 됩니다.
cudnn.benchmark모드를 활성하는거고 입력 크기가 변경되지 않을 경우 최적의 알고리즘을 선택하여 성능을 향상시킵니다.
gpu성능을 향상시키는데 단 조건이 있습니다. 크기가 변경되면 안됩니다.!
14. data.yaml 파일
custom_voc.yaml: Pascalvoc2007 데이터 명시 파일입니다.
custom_dataset.yaml: 직접 라벨링한 테스트 데이터 명시 파일입니다.
저장할때는 파일 경로: /content/yolo5/data/
강사님이 주신 custom_dataset.yaml과 custom_voc.yaml 파일을
yolov5 안에 data 폴더에 직접 넣어주었습니다.
| voc.yaml |  표기하는 방식은 딕셔너리 쓰듯이 쓰면 됩니다. path: 경로 키값: 경로 #은 주석처리라 지워도 됨 -으로 표시된건 train 데이터가 2개라는 이야기입니다. nc = class개수 (욜러5에 정해져있음) names: [클래스 이름] |
| dataset.yaml |  test는 custom_datasets/obj_train_data를 만들고 5개 만든 custom file을 올려놓고 나중에 테스트 잘 도는지 확인해보려고 합니다. |
15. YOLOv5 가중치 파일
가중치파일 = 기학습+레이어+파라미터개수가 틀린것을 의미
(예를들어서 레이어다른것처럼)
yolov6s.pt: 가장 작은 버전으로 경량화된 모델이며 작은 크기의 객체를 감지하거나 시스템 리소스가 제한된 환경에서 사용
(s:small/ 욜로모델중에 가장 작은 모델)
yolov5m.pt: 중간 크기의 모델로 기본적인 객체 탐지와 분류에 적합
(medium / 욜로모델중에 중간 크기 모델, 속도가 좀 늦어짐.)
yolov5l.pt: 큰 모델로 더 높은 정확도를 제공합니다. 크기가 큰 객체나 복잡한 시나리오에 유용할 수 있음
(l:Large /
yolov5x.pt: 가장 큰 모델로 가장 높은 정확도를 목표로 함
현재 경로 설정
%cd /content/yolov5현재 가 있는 위치를 설정해줍니다.
!python3 train.py --img 640 --batch 32 --epochs 10 --data custom_voc.yaml --weights yolov5s.pt --seed 2024| 해석 : train.py로 학습하겠다는것. img는 가로세로 640 고정, 배치사이즈 32, 에포크 10바퀴, data의 위치, 가중치는 뭐로할건지, seed는 얼마나 줄건지? |
위 코드는 욜로모델을 터미널에서 실행하는 방식입니다.
간단하게 돌려볼 수 있는것이 장점입니다.
그래서 총 욜로를 돌려볼 수 있는 방식은 지금까지 내가 아는것은 2개다.
1. 클래스만들어서 에포크줘서 돌리기
2. 터미널에서 간단하게 돌려보기

test데이터로 하겠다는건데 폴더가 없으니 폴더를 만들어줍니다.
/content/pascal_datasets/VOC 여기에 만들어줍니다 .



그리고 그 폴더 안에 obj_train_data 를 만들어줍니다.
그리고 각 custom_images (어노테이션 직접 한 사진 5장)을 obj_train_data에 넣어줍니다.
실제 테스트에는 들어간적이 없으니 잘 맞추는지 test로 진행해보려고합니다.
학습을 돌리고 나면 runs라는 파일이 생성이 됩니다.
그 안에 웨이트 폴더를 보면 best.pt, last.pt가 나옵니다.
best는 지금 train 을 돌리면서 가장 좋았던 가중치파일을 누적해서 담습니다.
last.pt는 맨 마지막것에 대한 가중치가 남습니다.
그래서 이 파일을 가지고가서 val.py에 넣겠습니다.
val
!python3 val.py --weights /content/yolov5/runs/train/exp/weights/best.pt --data custom_voc.yaml --img 640 --iou 0.5 --task test --halfiou는 어느정도 객체가 겹쳤을때 맞다고 할것인가?
보통 실무에서는 0.3정도로 해도 맞다고 합니다. 지금은 0.5로 줘보도록 하겠습니다.
half 는 메모리를 좀 절약할 수 있습니다.

지금 살짝 길을 잃을 수 있는 미래의 나를 위해 정리를 하자면
현재 지금은 욜로v5중에 s모델로 돌려보고있는거고 test이미지는 cvat을 사용해보려고 임시로 사용을 해봤던거고
정확하게 말하면 지금 사용하고 있는 것에서는 사용하지 않고있으니 test 파일로 사용할 수 있으니 test파일로
사용을 하고있는겁니다~
16. mAP(mean Average Precision)
위에서 나온결과를 바탕으로 확인해볼 수 있는 값들입니다.
Precision(정밀도) : 모델이 검출한 객체 중에서 실제로 객체인 비율
* True Postive(TP) : 올바르게 검출한 객체
* False Postivie(FP) : 잘못 검출한 객체
Recall(재현율) : 실제 객체 중에서 모델이 올바르게 검출한 비율
* False Negarivie(FN) : 검출하지 못한 객체
Average Precision(AP)
* Precision과 Recall의 관계를 나타내는 Recision-Recall 곡선의 아래 면적(Area Under Curve)을 계산하여 얻음
mean Average Precision(mAP)
다양한 객체 클래스에 대해 AP를 평균한 값
예) 클래스 1: AP=0.75, 클래스 2: AP=0.85, 클래스 3: AP=0.8 -> mAP = (0.75+0.85+0.8)/3 = 0.8
모델이 다양한 객체 클래스를 얼마나 잘 검출하고 있는지 종합적으로 평가할 수 있는 중요한 지표
객체 검출 모델의 성능을 비교할 때 많이 사용 -> mAP의 값이 높을수록 모델의 검출 성능이 좋다는것을 의미합니다.
검출MAX = 1
욜로는 detect가 있습니다.
detect라는 모듈이 있습니다. 이 역할은 물체가 어디 있는지 바운딩 박스를 쳐주거나 새그멘테이션을 해주는 기능입니다.
실행하면 실제로 내가 가지고 있는 영상에 각 표시를 해줍니다.
!python3 detect.py --weights /content/yolov5/runs/train/exp/weights/best.pt --img 640 --conf 0.25 --source /content/yolov5/pascal_datasets/VOC/images/test2007위에 iou는 객체인지 아닌지 판단해주는거라고 하면
conf는 객체냐 아니느냐를 판단하는 비율입니다. 이게 낮으면낮을수록 객체가 아닌것들도 잡아낼거고
높아지면 확실해지면 잡아내겠죠. 이 부분도 실험?을 통해서 여러번 돌리면서 확인을 해야합니다.
그럼 위 코드는 test 2007에 대한 디텍션이 되겠죠~
!python3 detect.py --weights /content/yolov5/runs/train/exp/weights/best.pt --img 640 --conf 0.25 --source /content/pascal_datasets/VOC/custom_datasets/obj_train_data우리가 넣었던 영상에서도 detect를 보려고 합니다.
어떤 경로냐면 pascal_datasets에 custom_datasets에 obj_train_data로 잡아줍니다.
그럼 아까 5개 사진을 넣었던 test사진들에 대해서도 디텍션 작업이 될겁니다.
각각 파일을 보면 importError는 나오지만 넘파이 버전문제같습니다. 그래도 결과는 잘 저장이 됩니다.
여기에 보면 완db로 해서


각 결과값을 그래프(png)로 시각화해준것을 확인할 수 있습니다.
여기서 GPU아까워서 결과 돌리고 살짝 보고 정리하려고 CPU로 바꿨더니 런타임 끊기고 다 사라졌.어.요.

아 정말 열심히 시간들여서 돌렸는데 많이 아쉽지만.. 더 공부할것도 많고 ,
앞으로 더 돌리고 결과 볼 날이 더 많을것이기때문에 런타임 타입을 바꾸면 모든 파일이 초기화된다는것을
배웠다고 생각하겠슴다.
쨌든!



이어서 마무리를 해보자면 TEST파일을 가지고 디텍션작업을 해준 이미지를 보니
기존에 있던 내용들을 트레이닝 시켜서 객체가 어떤것인지 학습을 시켜주었고 디텍트를 해봐! 했떠니
알아서 잘 쳐주는것을 확인할 수 있습니다.
마지막 사진은 말이라고 생각을 했고 나머지 객체는 다 잘 맞췄습니다.
'AI 컴퓨터 비전프로젝트' 카테고리의 다른 글
| [DL] 균등화, 평탄화 등 이미지 변환 활용(이미지, 영상 품질관련)(2) (1) | 2024.09.27 |
|---|---|
| [DL] 균등화, 평탄화 등 이미지 변환 활용(이미지, 영상 품질관련)(1) (0) | 2024.09.27 |
| [ML/DL] 파이토치로 구현한 논리회귀 (5) | 2024.07.23 |
| [ML] kMeans_비지도학습, 마케팅데이터셋 활용 (1) | 2024.07.16 |
| [ML]로지스틱 회귀_승진 될지 안 될지 분류해보기 (2) | 2024.07.07 |



