1.크롤링과 스크레이핑
- 크롤링(crawling):인터넷의 데이터를 활용하기 위해 정보들을 분석하고 활용할 수 있도록 하는 수집하는 행위
- 스크레이핑(Scraping): 크롤링후 데이터를 추출하고 가공하는 행위
실전연습 // 정적인 URL
2.Basic English Speaking
https://basicenglishspeaking.com/daily-english-conversation-topics/
위 사이트에 있는 75개의 단어들을 변수로 담는 크롤링 을 할 것입니다.
가장먼저 import(개입)를 하고 requests를 합니다.
파이썬을 설치만 하면 리퀘스트라는 모듈이 설치가 되어있습니다.
** 리퀘스트 : 서버에 접속을 해서 어떤 특정한 요청을 하게끔 만들어주는 기능을 합니다.
원하는 서버에 접속해서 응답받아서 데이터를 가져올 수 있습니다.
** BeautifulSoup : HTML 및 XML 문서를 파씽하기 위한 파이썬 라이브러리입니다.
즉 위 코드를 이용하여 웹페이지에서 데이터를 추출하고 분석할 수 있습니다.
# HTML 연결
site = 'https://basicenglishspeaking.com/daily-english-conversation-topics/'
변수 site를 만들어서 링크를 넣어줍니다.
변수 request에 requests객체를 쓰는데, get(url을 통해서 접속하겠다는 뜻)를 메소드를 사용할겁니다.
이렇게 되면 접속을 하고 확인을 합니다 .
확인은 print(request)로 하고 Response[200]이 나오면 정상적인 접속이 되었다는 말입니다.
request는 객체니까 print(request.text)인 텍스트로 변환하면 HTML 소스가 그대로 보여지게 됩니다.
HTML이 들어있다는것을 기억하고 확인하면 됩니다.
서버로부터 전달받은 정보를 soup 객체를 만들어줍니다.
이 객체는 내 마음대로 정보를 추출할 수 있는 기능을 가지게 해줍니다.
find라는 매서드를 사용해서 내가 추출하고 자하는 범위를 잡습니다.
태그가 div이면서 class가 thrv-columns인걸 찾겠다 라는 의미입니다.
divs의 a(앵커태그)를 find_all 매서드를 이용해서 다 가져옵니다.
여기서 값은 여러개니까 list의 형태로 반환됩니다.
list니까 for문을 돌 수 있고 돌면서 link안에있는 text라는 속성(a버리고 그 안에있는 글자만 가져오는것)을 이용해서
출력하면 글자(단어)만 추출됩니다.
subject라는 빈 리스트를 만들고
links에있는걸 하나씩 꺼내서 빈 list(subject)에 link의text를 담아주겠다.
라는 의미입니다.
출력하면 리스트로 들어가게됩니다.
75개가 추출됩니다.

위와같이 출력이 되는걸 확인할 수 있습니다.
실전연습2
3. 다음 뉴스기사
제목의 기사번호를 넘겨주면 기사의 제목을 return해주는 함수를 만들려고 합니다.
뉴스기사들을 보면 패턴을 확인할 수 있습니다.
daum_news_title(news_id)
-> news_id를 넘기게되면
url = f'https://v.daum.net/v/{news_id}'
url = news_id받은걸 그대로 넘겨주겠습니다.
request = requests.get(url)
url을 request변수에다가 requests.get(url)을 넘겨주겠습니다.
soup = BeautifulSoup(request.text)
접속을 한 후에 BeautifulSoup객체에 얻어온 html(request.text에있는것)을넣어주게 됩니다.
그럼 soup객체를 만들어올 수 있습니다.
title = soup.find('h3', {'class':'tit_view'})
html에서 기사 제목에 해당하는 html을 가져와야하니 기사의 html을 봐보겠습니다.

특정할 수 있는 선택자가 무엇인가 보니
h3태그의 class가 tit_view더라구요 그래서 코드에는 태그는 h3태그 클래스는 tit_view를 찾아내 라고 명령하고
title을 얻습니다.
그 후 타이틀이 있다면 title의 text의 공백이 있다면 그것도 날려달라고 strip() 작성합니다.
만약 없다면 return으로 '제목없음'을 넣어달라고 작성했습니다.
결과는 잘 나옵니다.
4.벅스 뮤직차트 크롤링
위와같이 똑같이 접속을 위해서 request를 넣어줍니다.
print(request)를 하면 200으로 접속은 잘 됩니다.
BeautifulSoup을 파씽할 수 있는 soup객체를 만듭니다. soup객체를 만들었으니
노래와 가수를 가져와야하고 html을 확인해야합니다.

title검사를 해보니 p태그이면서 그 중에서 class가 title인걸 가져올 수 있도록
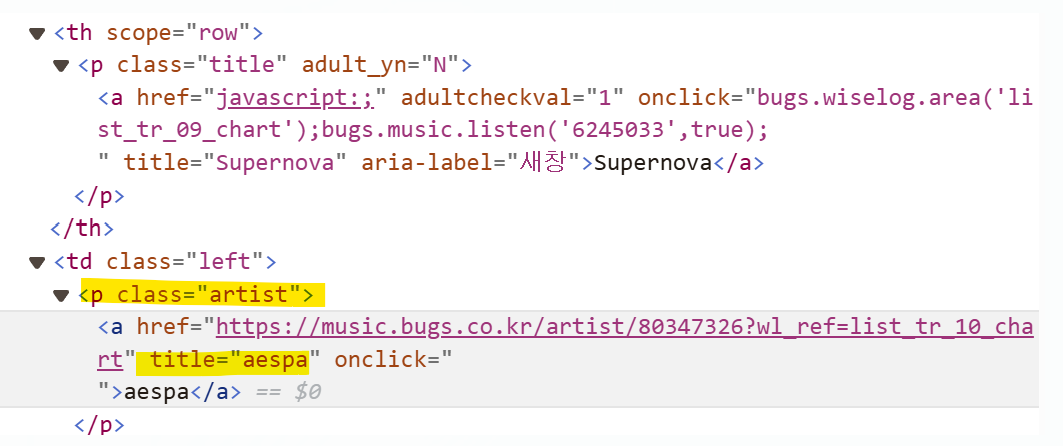
입니다.
앵커태그로 되어있지만 앵커태그가 너무 많으니까 그 위에있는 p태그 활용을 하려고 합니다.
그럼 p 태그이면서 class가 artist인 것들로 불러오려고 아래 코드를 작성했습니다.
개수가 똑같다고 하더라도 artist와 title을 따로 각각 돌리는건 비효율적이라고 enumerate zip함수를 사용할수 있습니다.
이렇게 하면 titles과 artists를 묶어서 한번에 돌릴 수있고 그 변환값을 튜플로 (t, a)로 출력됩니다.
여기서 피쳐링한 가수가 있어서 가수 2개의 정보값으로 팝업이 뜹니다.
그래서 \n을 찾아서 title = t.text.strip() //(공백을 없애는것)을 따로 변수로 넣습니다.
그 다음 artist = a.text.strip().split('\n')[0]하면 \n으로 쪼갭니다.
enter가 있으면 둘로 쪼개지겠죠 앞이 0번 뒤에있는게 1번이니까 [0]번만 취하겠다고 적어줍니다.
그러면 빈칸없이 모든 값들이 잘 추출되는것을 확인할 수 있습니다.

5. robots.txt
robots.txt : 웹 사이트에 크롤러같은 로봇들의 접근을 제어하기 위한 규약
이렇게 크롤러같은 로봇들의 접근을 제어하기 위한 규약을 해놓으면
400번대로 링크연결이 실패하다고 나옵니다.
이럴때는 https://www.melon.com/robots.txt를 치면

어디까지 크롤링할 수있는지 허용범위가 나오게 됩니다.
6. 네이버 증권 종목 스크레이핑
이 부분은 과제로 수행해보려고 했던 부분이지만 생각보다 쉽지 않았었다.
일단 문제는 html에서 선택자를 찾는것이였다
한 눈에 보이지 않았기에 어떤 선택자를 이용하여 범위를 잡아야할지 감이 안 잡혔다.
위에서 진행했던 문제를 다시 해결해보면서 데이터 수집할 수 있게끔 하고싶다.
눈에들어오는 url을 보면 앞에까지는 똑같고 code=의 뒷 부분부터 주식의정보가 달라진다는것을 확인할 수 있습니다.
한 개의 종목을 가지고 정상접근이 되는지 확인하기 위해 접근확인을 합니다.
site에는 종목 사이트를 넣고
request라는 변수로 url로 가져올 수 있는 get매소드를 사용합니다.
BeautifulSoup을 파씽할 수 있는 soup객체를 만듭니다.
text로 추출할 수 있는 request.txt도 함께 적어줍니다.
request.text는 HTML 문자열을 포함하고 있고 해당 요청에 대한 응답의 텍스트내용을 의미하게됩니다.
div_totalinfo라는 변수에 soup이라는 객체안에서 div영역 내에서 calss가 new_totalinfo인 값을 찾아줘 라는 의미입니다.
HTML에서의 div구역을 확인하고 지정해줍니다.
name이라는 변수에 h2태그에있는 text를 찾아줘 라는의미입니다.

find_all이아닌 find를 하게되면 맨 위에있는 태그 하나만 가져오기때문에 h2로 종목 이름을 가져오기했습니다.
#주가 가져오기
같은 코드로 반복되는걸 볼 수 있습니다.
가격은 span으로 하기에는 너무 자료가 많고
전체적으로 묶고있는 div로 가져오기로 했습니다.

p클래스의 no_today인걸로 값을 찾아서 확인해보니 블라인드에서 안보이는 값이있는데 그 값을 추출했습니다.

이렇게 뽑으면 종목코드까지 잘 나오는걸 확인할 수 있습니다.


테이블전체를 가져오는걸로 해서 1번째 tr의 3번째 td로 들어간것을 활용하기로 했습니다.
td를 가져와서 tds를 찍으면 td를 리스트를 가져오면 3번째 td(거래량)을 뽑으려고합니다.(블라인드처리되어있음)
tds에서 2번째에 들어있는 것을 찾으려고 하고 span태그 class가 blind인것을 텍스트로 뽑은것이 거래량이 됩니다.
이 모든것을 다 뽑았으니 딕셔너리 형태로 key:value형태로 만들어보겠습니다.
함수로 만드는건 코드를 전달받을거고 코드는 맨 뒤에있는 숫자고 f스트링으로 변경했습니다.
위에있는 함수를 그대로 가져왔습니다.
여기서 범할 수 있는 오류는 숫자앞에 "" 를 써줘야한다는점입니다.
위 코드는 삼성전자에 대한 값입니다.
여기서 끝나는것이 아니라,
코드를 모아서 딕셔너리형태로 새로운 data 리스트에 넣는 방법까지 이어서 실행했습니다.
그러면 for문을 돌면서 5개의 딕셔너리를 만들게 됩니다.
7.판다스를 이용하여 마무리하기
판다스는 편하게 파이썬에있는 엑셀이라고 생각하면 편합니다.
판다스는 파이썬중에서도 데이터를 다루는데 가장 널리 사용되고있는 라이브러리예요.
x,y축으로 데이터프레임으로 저장해줍니다.
먼저 데이터를 실행해줍니다.
import pandas as pd

#데이터프레임 엑셀로 변경하기

까지하면 엑셀로 변경된것까지 확인이 가능합니다.
'AI > 머신러닝' 카테고리의 다른 글
| 데이터베이스와 MongoDB (0) | 2024.06.06 |
|---|---|
| 변수 타입 어노테이션 (1) | 2024.06.03 |
| 크롤링 :: 1개의 이미지, 대량 이미지수집 (1) | 2024.05.31 |
| 크롤링 :: 인스타그램, 리팩토리 함수제작 및 실행 (0) | 2024.05.30 |
| 크롤링::네이버웹툰 댓글 크롤링 (1) | 2024.05.28 |



