😊 다중선형회귀를 예측해보고 싶습니다.
일단 간단한 데이터를 만들었습니다. 아래의 데이터로 최종예측까지 해보려고합니다.
import pandas as pd
df = pd.DataFrame({
'매출액': [300, 320, 250, 360, 315, 328, 310, 335, 326, 280,
290, 300, 315, 328, 310, 335, 300, 400, 500, 600],
'광고비': [70, 75, 30, 80, 72, 77, 70, 82, 70, 80,
68, 90, 72, 77, 70, 82, 40, 20, 75, 80],
'플랫폼': [15, 16, 14, 20, 19, 17, 16, 19, 15, 20,
14, 5, 16, 17, 16, 14, 30, 40, 10, 50],
'투자':[100, 0, 200, 0, 10, 0, 5, 0, 20, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
})
df.head(3)
😊 모델학습을 하고 summary를 뽑아보면 rmse, r-squared, 등을 한 번에 볼 수 있습니다.
# 모델 학습 summary 출력 (종속변수: 매출액, 독립변수: 광고비, 플랫폼)
from statsmodel.formula.api import ols
model = ols('매출액~ 광고비+플랫폼', data=df).fit()
print(model.summary())
😊 예측하기
# 광고비 50, 플랫폼 20일 때 매출액 예측
data = pd.DataFrame({
'광고비':[50],
'플랫폼':[20]
})
pred = model.predict(data)
pred
😊 외에도 잔차 예측하기도 할 수 있습니다.
잔차는 제곱을 해야한다는걸 까먹지 말아야해요!
# 잔차 제곱합
(model.resid ** 2).sum()잔차는 resid 를 쓴다는것도 체크해두기!!
# MSE
(model.resid ** 2).mean()😊 mse는 mean을 구하는것인것도 체크해두기!!
😊 회귀계수에 신뢰구간을 설정해서 확인할 수 있습니다.
conf_int(alpha=)를 사용하면 됩니다.
# 광고비, 플랫폼 회귀계수의 95% 신뢰구간
model.conf_int(alpha=0.5)
😊매출액에 대한 95% 신뢰구간과 예측구간까지 구할 수 있습니다.
# 광고비 50, 플랫폼 20일 때 매출액에 대한 95% 신뢰구간과 예측구간
pre2 = pd.DataFrame({
'광고비':[50],
'플랫폼':[20]
})
pred = model.get_prediction(pre2)
pred2 = model.conf_int(alpha=0.05)
print(pred2)
pred.summary_frame(alpha=0.05)
# 신뢰구간 268.612221 352.52844
# 예측구간 179.700104 441.440556😊 범주형 변수
범주형 변수를 적어보려고 합니다.
import pandas as pd
df = pd.DataFrame({
'매출액': [300, 320, 250, 360, 315, 328, 310, 335, 326, 280,
290, 300, 315, 328, 310, 335, 300, 400, 500, 600],
'광고비': [70, 75, 30, 80, 72, 77, 70, 82, 70, 80,
68, 90, 72, 77, 70, 82, 40, 20, 75, 80],
'플랫폼': [15, 16, 14, 20, 19, 17, 16, 19, 15, 20,
14, 5, 16, 17, 16, 14, 30, 40, 10, 50],
'투자':[100, 0, 200, 0, 10, 0, 5, 0, 20, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
'유형':['B','B','C','A','B','B','B','B','B','B'
,'C','B','B','B','B','B','B','A','A','A']
})
df.head(3)유형이라는 부분이 A,B,C로 수치가 아닌 범주형으로 구성되어있는걸 확인할 수 있습니다.
여기서 종속변수는 '매출액'이라는 부분 체크하고 갈거구요.
똑같이 MODEL을 만들어줍니다.
from statsmodels.formula.api import ols
model = ols('매출액 ~ 광고비 + 유형', data=df).fit()
print(model.summary())**사실 ols를 하면 알아서 원핫인코딩을 진행해줍니다!!
그래서 원핫인코딩을 하지 않아도 됩니다. (아래 결과를 보면 됨)
*********단 OLS는 범주형으로 따로 바꿔줘야한다고 알고있다.
OLS ols는 다름!
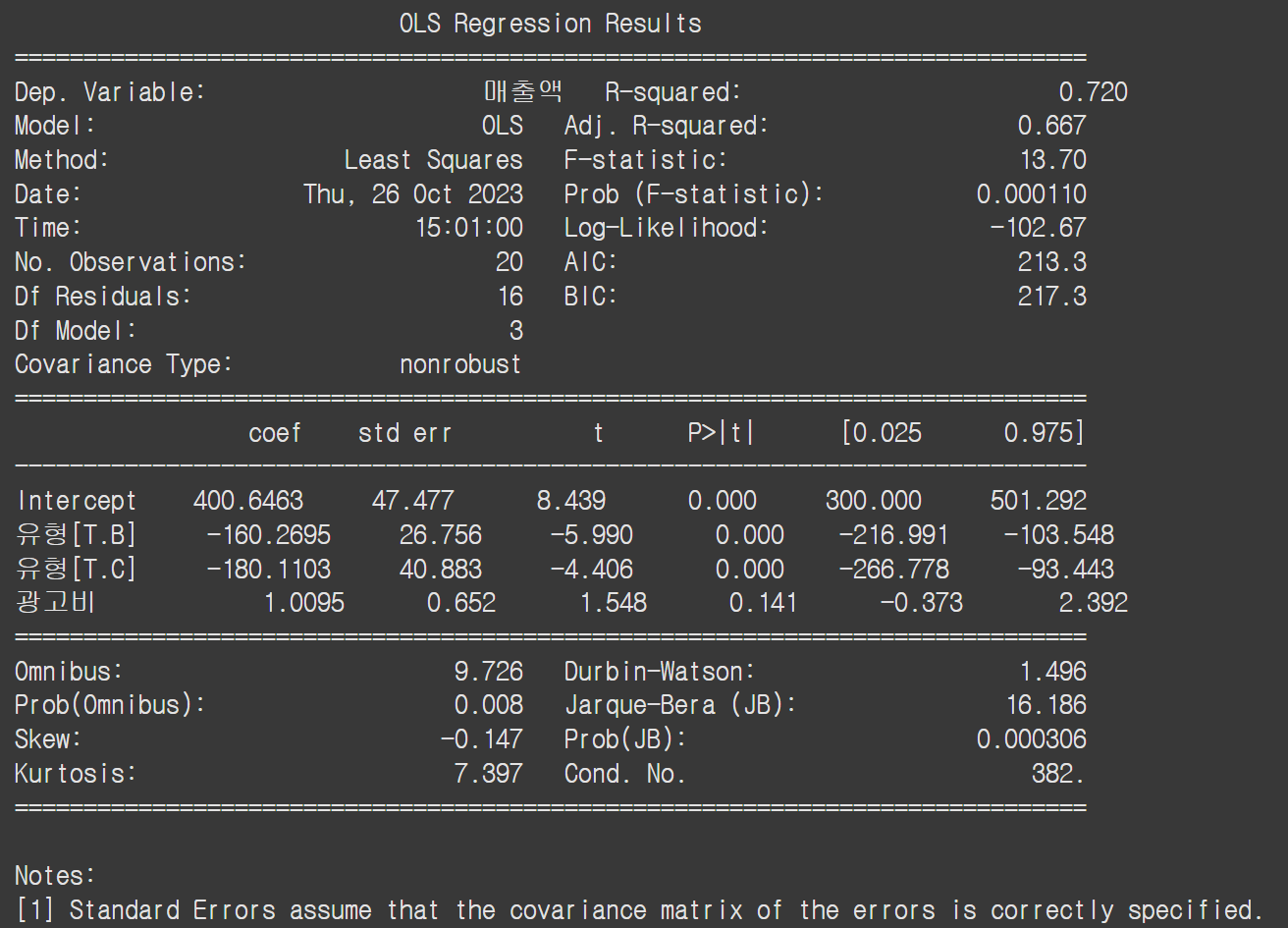
A가 없는 이유는 다중공선성이라는 이유때문에 따로 DROP을 해줬다는것만 가볍게 알고 넘어가도 됩니다.
'자격증 > [빅분기] 빅데이터분석기사' 카테고리의 다른 글
| [작업형3] 일원분산분석 실습 + 심화실습 (0) | 2024.11.17 |
|---|---|
| [작업형3] 분산분석 개념 (0) | 2024.11.16 |
| [작업형3] 회귀분석-단순 선형 회귀 분석 (3) (0) | 2024.11.13 |
| [작업형3] 회귀분석- 상관관계 (2) (0) | 2024.11.12 |
| [작업형3] 회귀분석(1) (0) | 2024.11.11 |



