0824
#교차검증(vaildation)
## 교차검증(Cross Validation)
1. 교차검증
학습 데이터셋을 학습, 검증, 평가 데이터셋으로 분리하는 것으로 검증세트를 학습세트의 부분세트로 교차해가며(학습세트 중 일부를 검증세트로 사용)
학습 데이터셋(train): 학습을 위한 데이터
검증 데이터셋(validation) : 학습 데이터셋의 일부를 추출한것으로 학습된 모델의 성능을 일차적으로 평가
평가 데이터셋(test): 모든 학습과 검증 과정이 완료된 후 최종적으로 성능 평가
교차검증 장점: 모든 데이터셋을 훈련(학습)에 활용할 수 있다. 평가에 사용되는 데이터 편중을 막을 수 있다.
교차검증 단점: 반복해야하는 횟수가 많아지기 때문에 모델 훈련/평가 시간이 오래걸린다.
즉, 교차검증 횟수가 늘어날 수록 전체적인 평가 성능이 떨어진다.
1) k-폴드 교차검증(K-Fold Cross Validation)
K개의 폴드에 K번의 학습과 검증 평가를 반복적으로 수행하는 교차 검증
ex)k=5
폴드1 폴드2 폴드3 폴드4 폴드5
검증 학습 학습 학습 학습
학습 검증 학습 학습 학습
학습 학습 검증 학습 학습
학습 학습 학습 학습 학습
학습 학습 학습 학습 검증
원리)
1) 훈련세트를 k개의 폴드로 나눈다(폴드:훈련세트의 서브세트)
2) 첫번째 폴드를 검증세트로 사용하고 나머지 폴드(k-1)를 훈련세트로 사용
3) 모델을 훈련한 후 검증세트로 평가를 시행
4) 차례대로 다음폴드를 검증세트로 사용하며 반복
과정)
1단계) 데이터 준비: 학습 데이터와 테스트 데이터 나뉘어 짐
2단계) 데이터 분할: 데이터를 k개의 폴드로 나눔
3단계) 모델 학습과 평가
k개의 폴드 중 하나를 선택하여 테스트 세트로 사용하고,
나머지 k-1개의 폴드를 학습 세트로 사용
4단계) k번반복: 1~3단계를 K번 반복, 각각의 폴드가 한번씩 테스트세트로 사용되도록 모델을 평가
5단계) 성능 평가: K번의 평가를 통해서 얻은 성능 지표를 평균을 내어 최종적인 모델의 성능을 평가
K-폴드 교차 검증의 문제점)
단순히 무작위로 데이터를 분할하기 때문에 각 폴드에서의 클래스 비율이 전체 데이터셋의 클래스 비율과 다르게 나타나는 문제를 발생시킬 가능성이 있습니다.
2) Startified K-Fold
기존의 K-Fold교차 검증의 문제점을 해결하기 위해 사용
분류문제에서 클래스 별로 균형을 유지하면서 데이터를 분할하는 기법
각 폴드에서 클래스 비율이 원래 데이터셋과 유사하도록 보장하여
모델의 성능 평가를 더 정확하게 수행할 수 있음
과정)
1단계) 클래스 분포 확인: 데이터셋의 클래스 분포를 확인
분류문제에서는 클래스 레블을 가지고 있으며 각 클래스의 샘플의 수를 계산함
2단계) 폴드 생성: 데이터셋을 K개의 폴드로 나눔.
각 폴드에서는 원래 데이터셋의 클래스 비율과 유사한 비율로 클래스 샘플이 포함되도록 분할
3단계) 모델학습과 평가
k개의 폴드 중 하나를 선택하여 테스트 세트로 사용하고 나머지 k-1개의 폴드를 학습세트로 사용
4단계) K번 반복: 1~3단계 과정을 K번 반복
3) Cross_val_score()함수
- 교차검증을 편하게 할 수 있도록 해주는 함수
- 사이킷런라이브러리에서 제공하는 함수로 교차검증을 수행하여 모델의 성능을 평가하는데 사용됨
- 지정된 모델과 데이터셋, 교차검증을 수행하는 방법을 매개변수로 받아서 교차검증 결과 정확도를 반환
- 매개변수
estimator: 분류 알고리즘 Classifier 또는 회귀 알고리즘 Regressor
features : 특정 데이터세트
label: 레이블 데이터세트
scoring:예측 성능 평가지표
분류 => 정확도(accuracy), 정밀도(precision), 재현율(recall), F1-score
회귀 => 평균제곱오차(MSE), 결정계수(R2 Scroe)
cv: 폴드 수
#타이타닉 생존자 예제 실행하기
# titanicdf.py
def p(str):
print(str, "\n")
# 라이브러리 임포트
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import warnings # 경고메세지를 다루기 위한 라이브러리
warnings.filterwarnings(action='ignore') # 경고메세지 무시
# train.csv
titatic_df = pd.read_csv("../assets/train.csv")
# 상위 5개행 출력
#p(titatic_df.head())
# 데이터프레임 정보 확인
#titatic_df.info()
# train.csv 컬럼 설명
'''
PassengerId : 탑승자 데이터 일련번호
Survived : 생존여부 (0:사망, 1:생존)
Pclass : 선실등급 (1:일등석, 2:이등석, 3:삼등석)
Name : 탑승자 이름
Sex : 탑승자 성별
Age : 탑승자 나이
SibSp : 같이 탑승한 형제,자매 또는 배우자의 인원 수
Parch : 같이 탑승한 부모님 또는 자녀의 인원 수
Ticket : 티켓 번호
Fare : 요금
Cabin : 선실 번호
Embarked : 중간 정착한 항구 (C:Cherbourg, Q:Queenstown, S:Sothampton)
'''
## 데이터 전처리
# 컬럼별 null값이 몇 개 있는지 확인
#p(titatic_df.isnull().sum())
# 나이를 평균값으로 채움
titatic_df['Age'].fillna(titatic_df['Age'].mean(), inplace=True)
#p(titatic_df.isnull().sum())
# 선실과 정착지는 N으로 채움
titatic_df['Cabin'].fillna('N', inplace=True)
titatic_df['Embarked'].fillna('N', inplace=True)
#p(titatic_df.isnull().sum())
# 데이터프레임의 출력결과를 모두 표시하는 설정
pd.set_option('display.max_rows', 900)
#p(titatic_df)
# 중복값 확인 (동일한 값을 가진 행이 있는지)
#p(titatic_df[titatic_df.duplicated()])
# 성별 승객수 확인
#p(titatic_df['Sex'].value_counts())
# 선실별 승객수 확인
#p(titatic_df['Cabin'].value_counts())
# 정착지별 승객수 확인
#p(titatic_df['Embarked'].value_counts())
# 선실정보의 첫번째 알파벳만 추출 후 개수 확인
titatic_df['Cabin'] = titatic_df['Cabin'].str[:1]
#p(titatic_df['Cabin'].value_counts())
# 성별에 따른 생존자 수 확인
#p(titatic_df['Survived'].value_counts())
#p(titatic_df['Sex'].value_counts())
#p(titatic_df.groupby('Sex')['Survived'].sum())
# 성별과 생존자수를 기준으로 그래프 그리기
ss = titatic_df.groupby(['Sex', 'Survived']).size().unstack()
ss.plot(kind='bar')
# plt.show()
# seaborn 그래프
# estimator=len : 각 그룹의 크기를 계산해서 사용
sns.barplot(x='Sex', y='Survived', data=titatic_df, hue='Sex', estimator=len)
# plt.show()
# 나이에 따른 카테고리 생성
def category(age):
re = ''
if age <= -1:
re = 'Unknown'
elif age <= 5:
re = 'baby'
elif age <= 12:
re = 'child'
elif age <= 19:
re = 'teenager'
elif age <= 25:
re = 'student'
elif age <= 35:
re = 'young adult'
elif age <= 80:
re = 'adult'
else:
re = 'elderly'
return re
# 나이 카테고리 그래프 그리기
# 그래프 크기
plt.figure(figsize=(10, 6))
# x축 값을 순차적으로 표시
group_name = ['Unknown', 'baby', 'child', 'teenager', 'student',
'young adult', 'adult', 'elderly']
# 나이에 따른 카테고리화
titatic_df['Age_Cate'] = titatic_df['Age'].apply(category)
#p(titatic_df.head())
sns.barplot(
x = 'Age_Cate',
y = 'Survived',
hue = 'Sex',
data = titatic_df,
order = group_name
)
# plt.show()
#가족 또는 동승자 수와 생존여부에 따른 막대그래프
titatic_df['Family']=titatic_df['SibSp'] + titatic_df['Parch'] + 1
sns.barplot(
data=titatic_df,
x='Family',
y='Survived',
estimator=len
)
# plt.show()
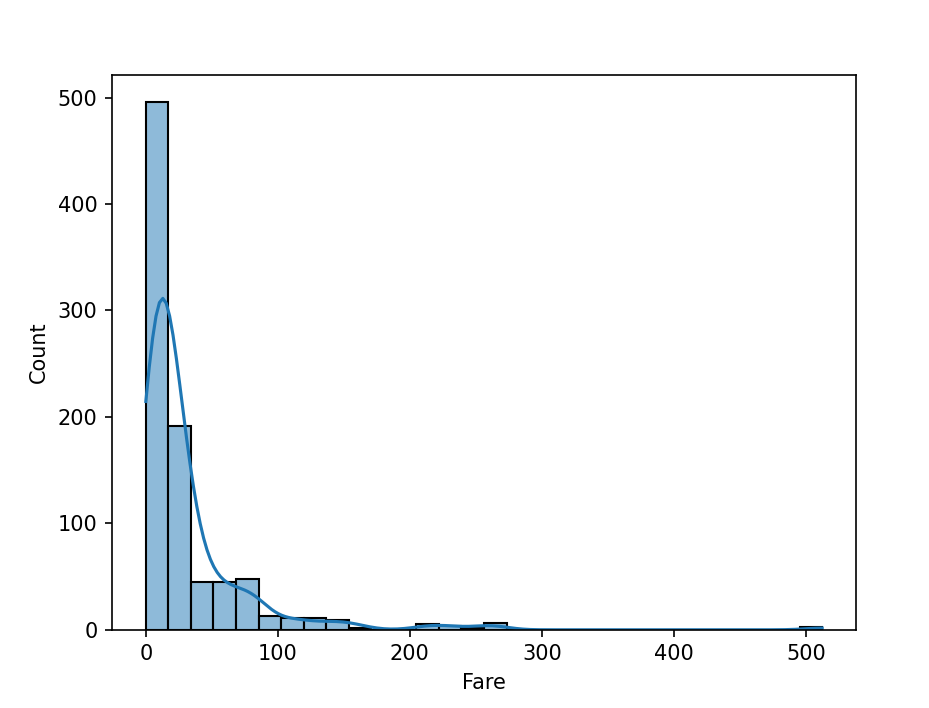
# 탑승요금 분포 그래프
sns.histplot(
data=titatic_df,
x= 'Fare',
bins = 30,#구간반복
kde = True # Kernel Density Estimation 부드러운 곡선으로 표사ㅣ
)
# plt.show()
#나이에 따른 생존율 비교(히스토그램, 박스플롯)
sns.histplot(data=titatic_df, x='Age', hue='Survived', bins=30, kde=True)
# plt.show()
sns.boxplot(data=titatic_df, x='Survived' ,y='Age')
# plt.show()




## crossvalidation.py
## 교차검증을 활용한 모델학습 및 성능평가
def p(str):
print(str, '\n')
# 라이브러리 임포트
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings(action='ignore')
# 데이터프레임 생성
df = pd.read_csv('../assets/train.csv')
#p(df.head())
# 패쳐 / 레이블 분리
features = df.drop('Survived', axis=1) # 패쳐
labels = df['Survived'] # 레이블
#p(features)
#p(labels)
## features 데이터 전처리
# 결측치 제거, 불필요한 속성 제거 (PassengerId, Name, Ticket)
# null 개수 확인
p(features.isnull().sum())
# 결측치 제거 (null값 대체)
features['Age'].fillna(features['Age'].mean(), inplace=True)
features['Cabin'].fillna('N', inplace=True)
features['Embarked'].fillna('N', inplace=True)
# 불필요한 속성제거 (PassengerId, Name, Ticket)
features = features.drop(['PassengerId', 'Name', 'Ticket'], axis=1)
#p(features)
# 레이블 인코딩 진행
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
features['Sex'] = le.fit_transform(features['Sex'])
features['Embarked'] = le.fit_transform(features['Embarked'])
features['Cabin'] = le.fit_transform(features['Cabin'])
#p(features)
# 훈련세트와 테스트세트 분할
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
features, # 패쳐
labels, # 레이블
test_size=0.2, # 분할비율 (20%가 테스트세트, 80%가 훈련세트)
random_state=53 # 랜덤 시드값
)
# shape 확인
# p(X_train.shape) # (712, 8)
# p(X_test.shape) # (179, 8)
# p(y_train.shape) # (712,)
# p(y_test.shape) # (179,)
## 의사결정트리
# 라이브러리 로딩
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
# 의사결정트리 분류기
dt = DecisionTreeClassifier(random_state=11)
#p(dt)
# 모델 학습
dt.fit(X_train, y_train)
# 예측치
pred = dt.predict(X_test)
#p(pred)
# 정확도
p(f"정확도 : {accuracy_score(y_test, pred)}")
## 교차검증
# 라이브러리 로딩
from sklearn.model_selection import cross_val_score
# dt:데이터프레임, features:패처, labels:레이블, cv:폴드 수
scores = cross_val_score(dt, features, labels, cv=10)
# 교차검증마다의 정확도 구하기
# iter_cout:반복 회수, accuracy:정확도
# enumerate(scores):교차검증결과를 열거
for iter_count, accuracy in enumerate(scores):
p(f"{iter_count+1}번째 교차검증 정확도:{accuracy}")
# 평균정확도
p(np.mean(scores))
## 데이터셋 인코딩
def p(str):
print(str, '\n')
# 라이브러리 임포트
import numpy as np
import pandas as pd
import warnings
warnings.filterwarnings(action='ignore')
# 데이터프레임 로딩
df = pd.read_csv('../assets/train.csv')
## 레이블인코딩
from sklearn.preprocessing import LabelEncoder
# 레이블인코더 생성
label_encoder = LabelEncoder()
# 성별을 레이블 인코딩
df['Sex_LabelEncoder'] = label_encoder.fit_transform(df['Sex'])
#p(label_encoder.classes_)
#p(df.head())
# 레이블인코딩용 함수
def encode_features(df, features):
for i in features:
le = LabelEncoder()
le = le.fit(df[i])
df[i] = le.transform(df[i])
return df # feature들이 레이블인코딩된 데이터프레임 반환
p(encode_features(df, ['Sex', 'Cabin', 'Embarked']))
'데이터 분석 및 시각화' 카테고리의 다른 글
| [ML]클러스터링_집값 상관관계 분석해보기 (0) | 2024.09.11 |
|---|---|
| [데이터분석] ML_머신러닝 모델+의사결정나무 (2) | 2024.08.30 |
| [데이터분석] ML_linearregression(선형회귀) (0) | 2024.08.23 |
| [데이터분석] ML(머신러닝)_basic, 데이터 분리 (0) | 2024.08.21 |
| [데이터분석] t-test,상관분석 (0) | 2024.08.20 |



