회귀분석을 배우면 가장 먼저 배우는 선형회귀 입니다.
가장 쉽기도 하고 다음으로 배우는것들도 선형회귀가 연관이 되어있기때문이죠.
이번 시간에는 linear 리니어함수에 대해서 배워봤습니다.
선형회귀는 분리를 해주는 지도학습 알고리즘 입니다 (빅분기 필기)
#linearregression.py
def p(str):
print(str, '\n')
## 선형회귀
# 라이브러리 로딩
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
#한글(폰트) 설정
plt.rc('font', family='Malgun Gothic')
# melon.csv 파일을 활용해서 분류하기
#1) DF 생성
df =pd.read_csv('../assets/melon.csv')
p(df.info())
p(df.head())
p(df.describe())
p(df)
# 2) 가수별 빈도 계산(가수별로 곡이 몇개나 있는지)
singer_counts = df['가수명'].value_counts()
# print(singer_counts, type(singer_counts))
print(singer_counts)
# 3) 가수별 빈도 시각화(막대그래프)
plt.figure(figsize=(8,3))
plt.bar(singer_counts.index, singer_counts.values)
plt.xlabel('가수명')
plt.ylabel('노래개수')
plt.title('가수별 노래개수 분포')
plt.xticks(rotation=45, ha='right')#기울기, 정렬
# plt.show()

이번에는 다른 데이터 (channer.csv)를 가지고 확인해보려고 합니다.
#linearregression.py
def p(str):
print(str, '\n')
## 선형회귀
# 라이브러리 로딩
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
#한글(폰트) 설정
plt.rc('font', family='Malgun Gothic')
# melon.csv 파일을 활용해서 분류하기
#1) DF 생성
df =pd.read_csv('../assets/melon.csv')
p(df.info())
p(df.head())
p(df.describe())
p(df)
# 2) 가수별 빈도 계산(가수별로 곡이 몇개나 있는지)
singer_counts = df['가수명'].value_counts()
# print(singer_counts, type(singer_counts))
print(singer_counts)
# 3) 가수별 빈도 시각화(막대그래프)
plt.figure(figsize=(8,3))
plt.bar(singer_counts.index, singer_counts.values)
plt.xlabel('가수명')
plt.ylabel('노래개수')
plt.title('가수별 노래개수 분포')
plt.xticks(rotation=45, ha='right')#기울기, 정렬
# plt.show()
## channer.csv
# 1) 데이터프레임 생성
df1 = pd.read_csv('../assets/channel.csv')
df1.info()
# p(df1)
# 첫번째 컬럼명 '연도'로 변경
df1 = df1.rename(columns={'Unnamed: 0' : '연도'})
# p(df1)
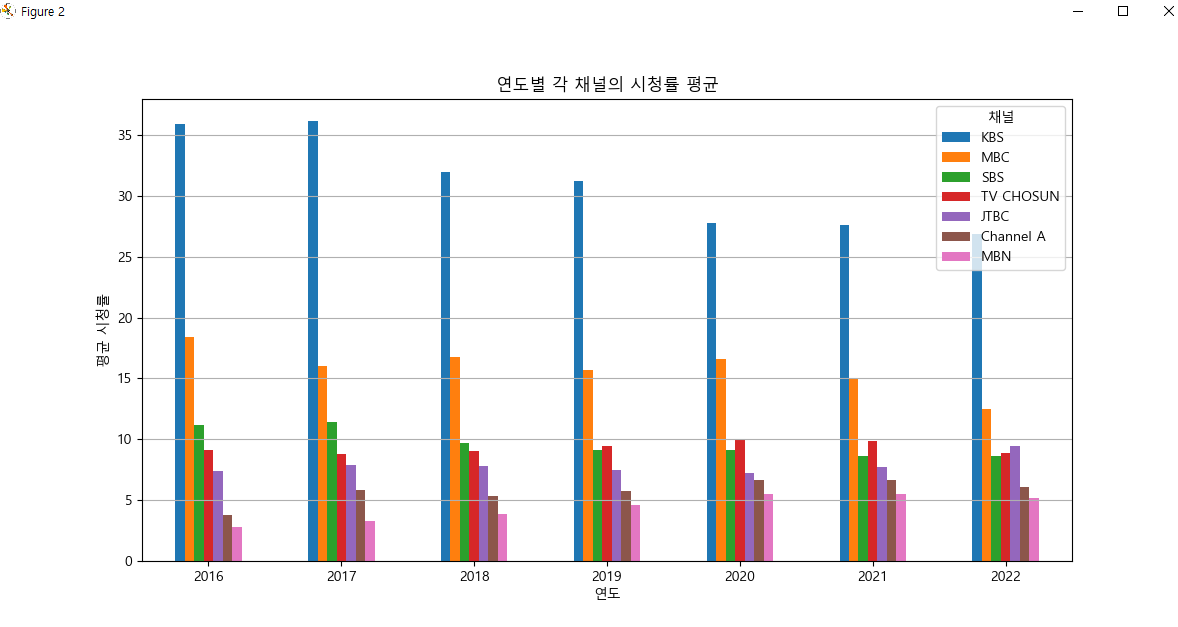
# 2) 연도별 각 채널의 시청률 변화 시각화(선그래프)
# plt.figure(figsize = (12, 6))
# for channel in df1.columns[1:]:
# plt.plot(df1["연도"], df1[channel], label = channel)
# plt.xlabel("연도")
# plt.ylabel("시청률")
# plt.title("연도별 각 채널의 시청률 변화")
# plt.legend(loc = "upper right")
# plt.grid(True)
# plt.show()
# # 3) 연도별 각 채널의 시청률 평균을 계산하고 막대그래프로 시각화
# avg = df1.groupby("연도").mean()
# avg.plot(kind = "bar", figsize = (12, 6))
# plt.xlabel("연도")
# plt.ylabel("평균 시청률")
# plt.title("연도별 각 채널의 시청률 평균")
# plt.legend(title = '채널')
# plt.xticks(rotation = 0)
# plt.grid(axis = "y")
# plt.show()
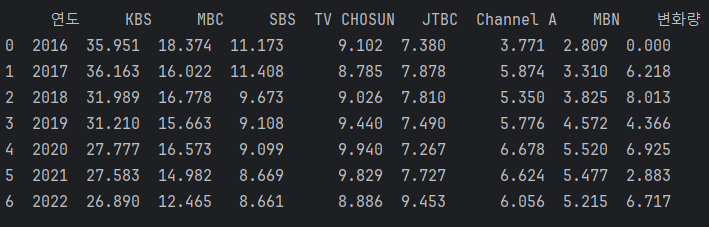
# 4) 연도별 각 채널의 시청률 변화를 확인하고 가장 큰 변화를 보인 채널 출력하기
#행마다의 변화량
df1['변화량'] = df1[df1.columns[1:]].diff().abs().sum(axis = 1)
p(df1[df1['변화량'] == df1['변화량'].max()])
#가장 큰 시청률 변화를 보인 채널(각 연도마다로 확인 출력)
# df1.set_index('연도').diff(axis=0).abs().idxmax(axis=1)
# #.set_index('연도') : 연도 열을 인덱스로 지정
# #.diff(axis = 0 ) : 각 행에서 이전 행과의 차이
# #.abs() : 절대값으로 반환
# #.idxmax(axis = 1) : 각 행에서 최대값의 인덱스를 찾음
# p(df1)2) 그래프

3) 그래프
4) 가장 큰 시청률 변화를 보인 채널(각 연도마다로 확인 출력)
선형회귀 (Linear Regression) / 지도학습
#linearregression.py
def p(str):
print(str, '\n')
## 선형회귀
# 라이브러리 로딩
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
#한글(폰트) 설정
plt.rc('font', family='Malgun Gothic')
# melon.csv 파일을 활용해서 분류하기
#1) DF 생성
df =pd.read_csv('../assets/melon.csv')
# p(df.info())
# p(df.head())
# p(df.describe())
# p(df)
# 2) 가수별 빈도 계산(가수별로 곡이 몇개나 있는지)
singer_counts = df['가수명'].value_counts()
# print(singer_counts, type(singer_counts))
# print(singer_counts)
# 3) 가수별 빈도 시각화(막대그래프)
# plt.figure(figsize=(8,3))
# plt.bar(singer_counts.index, singer_counts.values)
# plt.xlabel('가수명')
# plt.ylabel('노래개수')
# plt.title('가수별 노래개수 분포')
# plt.xticks(rotation=45, ha='right')#기울기, 정렬
# # plt.show()
## channer.csv
# 1) 데이터프레임 생성
df1 = pd.read_csv('../assets/channel.csv')
df1.info()
# p(df1)
# 첫번째 컬럼명 '연도'로 변경
df1 = df1.rename(columns={'Unnamed: 0' : '연도'})
# p(df1)
# 2) 연도별 각 채널의 시청률 변화 시각화(선그래프)
# plt.figure(figsize = (12, 6))
# for channel in df1.columns[1:]:
# plt.plot(df1["연도"], df1[channel], label = channel)
# plt.xlabel("연도")
# plt.ylabel("시청률")
# plt.title("연도별 각 채널의 시청률 변화")
# plt.legend(loc = "upper right")
# plt.grid(True)
# plt.show()
# # 3) 연도별 각 채널의 시청률 평균을 계산하고 막대그래프로 시각화
# avg = df1.groupby("연도").mean()
# avg.plot(kind = "bar", figsize = (12, 6))
# plt.xlabel("연도")
# plt.ylabel("평균 시청률")
# plt.title("연도별 각 채널의 시청률 평균")
# plt.legend(title = '채널')
# plt.xticks(rotation = 0)
# plt.grid(axis = "y")
# plt.show()
# 4) 연도별 각 채널의 시청률 변화를 확인하고 가장 큰 변화를 보인 채널 출력하기
#행마다의 변화량
df1['변화량'] = df1[df1.columns[1:]].diff().abs().sum(axis = 1)
p(df1[df1['변화량'] == df1['변화량'].max()])
#가장 큰 시청률 변화를 보인 채널(각 연도마다로 확인 출력)
# df1.set_index('연도').diff(axis=0).abs().idxmax(axis=1)
# set_index('연도') : 연도 열을 인덱스로 지정
# diff(axis = 0 ) : 각 행에서 이전 행과의 차이
# abs() : 절대값으로 반환
# idxmax(axis = 1) : 각 행에서 최대값의 인덱스를 찾음
df1.set_index('연도').diff(axis=0).abs().idxmax(axis=1)
p(df1)
#선형회귀(Linear Regression)
# 종속변수 y와 한 개 이상의 독립변수 x와의 선형 관계를
# 모델링하는 회귀분석 기법
#라이브러리 임포트
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as plt
#랜덤데이터 생성
#랜덤 시드값 정하기
np.random.seed(0)
#독립변순
#0 ~ 1 까지 랜덤한 값을 생성해서 X 생성
X = np.random.rand(100, 1)
#종속변수 f(y)=x+1+잡음(노이즈)
y = X + 1 + 0.1*np.random.randn(100, 1)
#선형 회귀모델 생성
model = LinearRegression()
# 모델 학습
model.fit(X, y)
#학습된 모델을 사용하여 예측
#새로운 예측값 생성
X_test = np.array([[5.0]])
p(X_test) #[[5.]]
# 예측값 생성
y_pred = model.predict(X_test)
p(y_pred) #[[3.00960211]]
# 여기까지는 x가 5.0이면 y값은 어느정도겠지? 하고 예측해본것
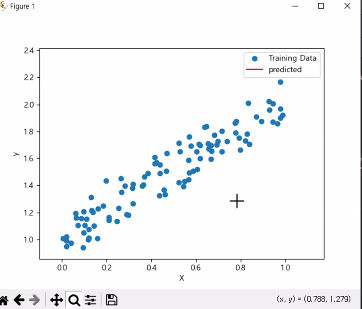
#학습데이터와 예측결과를 시각화
#legend 범례
plt.scatter(X, y, label = 'Training Data')
plt.plot(X_test, y_pred, color='red',label='predicted')
plt.xlabel('X')
plt.ylabel('y')
plt.legend()
plt.show()
코드작성시 당연한 말 이지만..
띄어쓰기, 엔터 콜론 등 절대적으로 잘 용도에 맞추어서 사용해야합니다.
이번에는 줄바꿀때 띄어쓰기가 안맞아서 계속 에러가 났습니다.
앞으로 한 줄 넘어갈때 좀 더 유심하게 확인해야겠다고 생각했습니다.
'데이터 분석 및 시각화' 카테고리의 다른 글
| [데이터분석] ML_머신러닝 모델+의사결정나무 (2) | 2024.08.30 |
|---|---|
| [데이터분석]ML_교차검증_타이타닉생존자 데이터셋 (0) | 2024.08.29 |
| [데이터분석] ML(머신러닝)_basic, 데이터 분리 (0) | 2024.08.21 |
| [데이터분석] t-test,상관분석 (0) | 2024.08.20 |
| [데이터분석] 넘파이&판다스 (0) | 2024.08.19 |



