Contents
# 텍스트 마이닝
# 지도 시각화
# 인터랙티브 그래프
# 마크다운 분석보고서
# 텍스트마이닝(Text Mining) 문자데이터에서 정보를 추출하는 분석 기법
# 형태소 분석(Morphology Analysis) 문자데이터에서 명사, 동사, 형용사 등 의미 있는 품사를 추출하는 분석 기법
# konlpy 라이브러리를 이용하여 한글텍스트 형태소 분석을 수행 (Java 필요, JPype1 라이브러리 필요)
# speech_moon.txt를 assets에 복사 (문재인 대통령 연설문)
# 워드클라우드 (Word Cloud) :단어 빈도를 구름모양 이미지로 표현한 그래프
* wordcloud 라이브러리 필요
* 구름이미지 cloud.png, 한글처리 DoHyeon-Regular.ttf를 assets에 복사)
# 기사 댓글 텍스트 마이닝
* 명사 추출시 Kkma 형태소 분석기 사용
* news_comment_BTS.csv (뉴스댓글데이터) assets에 복사
파일명 : dataanalysis/textmining1.py
# textmining1.py
def p(str):
print(str, '\n')
## 문재인 대통령 연설문
#텍스트 로딩
moon = open('../assets/speech_moon.txt', encoding='utf-8').read()
# p(moon)
#한글이 아닌 모든 문자 제거
#정규표현식
import re
# ^가-힣 == 가 ~ 힣 == 한글 전체를 포함 ==[] ==아닌것은, repl로 바꾸겠다는 의미
moon = re.sub("[^가-힣]", " ", moon)
# p(moon)
# 명사 추출
import konlpy
hannanum = konlpy.tag.Hannanum()
nouns = hannanum.nouns(moon)
# p(nouns)
# 추출한 명사를 데이터프레임으로 만들기
import pandas as pd
df_word = pd.DataFrame({'word': nouns})
# p(df_word)
# 각 명사들의 글자수 추가
df_word['count']= df_word['word'].str.len()
# p(df_word)
#글자수가 2개 이상인 것만 추출
df_word = df_word.query("count>=2")
# p(df_word)
# 글자수로 정렬
df_word = df_word.sort_values("count")
# p(df_word)
# 단어별 빈도 구하기
#word가 같은 것들을 그룹핑
df_word = df_word.groupby("word", as_index=False)
#word가 같은 것들의 개수를 카운트해서 n에 저장)
df_word = df_word.agg(n=("word", "count"))
# 개수가 많은 순으로 정렬
df_word = df_word.sort_values("n", ascending=False)
p(df_word)
#단어별 빈도 막대그래프용 데이터 20개 추출
top20 = df_word.head(20)
#막대그래프 그리기
import seaborn as sns
import matplotlib.pyplot as plt
#그래프 설정하기
plt.rcParams.update({
"font.family":"Malgun Gothic", #글자체
"figure.dpi": "120", #해상도
"figure.figsize":[6.5 , 6] #화면 크기
})
sns.barplot(data=top20, y="word", x="n")
plt.show()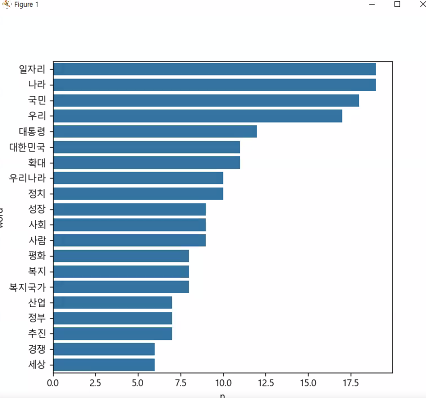

위처럼 bar graph로 그릴 수 있습니다. 단 세로로 그리는것이 좋은점이 글씨가 겹치지 않는다는 점입니다.
# 워드 클라우드 생성
#워드 클라우드 생성
import matplotlib.pyplot as plt
#워드클라우드에서 워드 클라우드만 가져올때는 from
from wordcloud import WordCloud
#한글폰트
font = "../assets/DoHyeon-Regular.ttf"
#데이터 프레임을 딕셔너리로 변경
# index는 word가 되고 값은 n이 되는 딕셔너리로 변경
dic_word = df_word.set_index("word").to_dict()['n']
#워드 클라우드 설정
wc = WordCloud(
random_state= 1234, #모양을 랜덤하게 만들기 위한 난수
font_path= font, # 폰트
width= 400, # 넓이
height= 400, #높이
background_color= "white" #배경색
)
#워드 클라우드 생성
img_wordcloud = wc.generate_from_frequencies(dic_word)
#워드클라우드 그리기
plt.figure(figsize=(10,10)) #가로 세로 크기
plt.axis('off') #테두리 선 없애기
plt.imshow(img_wordcloud) #워드클라우드 이미지 보여주기
plt.show()

#구름모양 워드클라우드 만들기
#구름모양 워드클라우드 만들기
#구름모양 이미지 로드
from PIL import Image
#이미지 파일을 메모리에 로딩
icon = Image.open("../assets/cloud.png")
#마스크(mask) 생성
import numpy as np
#icon이미지 크기만한 하얀색 마스크 이미지 로드
img = Image.new("RGB", icon.size, (255,255,255))
img.paste(icon, icon) #마스크 붙이기
img = np.array(img) #numpy배열로 만들기
wc = WordCloud(
random_state = 1234,
font_path= font,
width= 400,
height= 400,
background_color= "white",
mask = img, #마스크
colormap= 'inferno' #컬러맵 타입
)
#워드 클라우드 생성
img_wordcloud = wc.generate_from_frequencies(dic_word)
#워드클라우드 그리기
plt.figure(figsize=(10,10)) #가로 세로 크기
plt.axis('off') #테두리 선 없애기
plt.imshow(img_wordcloud) #워드클라우드 이미지 보여주기
plt.show()

| 순서 | 함수,메소드 | 설명 |
| 1 | df.head() | 상위 5개 기본(10)은 10개 추출합니다. |
| 2 | df_word.query() | ()조건만 추출 |
| 3 | df_word.sort_values("count") | count의 값으로 정렬하겠다는 의미 |
| 4 | df_word = df_word.groupby("word", as_index=False) | word가 같은 것들을 그룹핑 |
| 5 | df_word = df_word.agg(n=("word", "count")) | word가 같은 것들의 개수를 카운트해서 n 에 저장 |
| 6 | df_word = df_word.sort_values("n", ascending=False) | 개수가 많은 순으로 정렬 |
| 7 | wc.generate_from_frequencies(dic_word) | dic_word클라우드 생성 |
| 8 | dic_word = df_word.set_index("word").to_dict()['n'] | index는 word, 값은 n이 되는 딕셔너리로 변경 |
파이참 자바오류 발생 시 해결방법
(자바가 안깔려있고, 경로가 지정이되어있지 않기때문에)
그러면 자바를 설치해야합니다.
자바설치하는 방법
1.사이트 들어가기
https://jdk.java.net/java-se-ri/17-MR1
Java Platform, Standard Edition 17 Reference Implementations
Java Platform, Standard Edition 17 Reference Implementations The official Reference Implementation for Java SE 17 (JSR 392) is based solely upon open-source code available from the JDK 17 Project in the OpenJDK Community. This Reference Implementation a
jdk.java.net
자바가 2가지 버전이있습니다.(1.오라클, 2.open 소스)
-지금 진행하는건 2번
2. windows 11 x 64 java Development Kit설치

3. 다운받은 zip파일을 폴더에 압축 해제

그럼 설치가 되어있는걸 확인할 수 있고 이걸 복사해서 저는 D드라이브에 폴더하나를 만들고 이동을 해 주었습니다.
압축을 풀어주고 폴더에

확인하고 복사 하고 다시 상위폴더에 넣어주었습니다.

그리고 bin파일은 지우고 17.0.0.1은 jdk17로 이름을 변경해주었습니다.
jdk17폴더를 들어가서 확인해보면
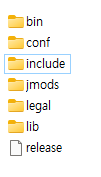
이런 구조로 되어있습니다. 꼭! 확인해야합니다~
4. 내PC 아이콘 우클릭 > 속성 > 시스템 속성 > 고급 > 환경변수 > 시스템변수 > 새로만들기 > 변수이름 , 변수값 지정
변수이름 :JAVA_HOME , 변수 값(경로)을 넣어줍니다
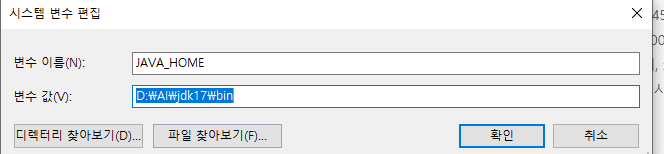

*시스템 변수에 설정을 하면 모든 사용자가 영향을 받습니다.
5. 파이참 재가동
내 컴퓨터에 java설치됐는지 확인하는 방법
cmd (명령 프롬포트)
java -verson
입력 후 확인하기
'데이터 분석 및 시각화' 카테고리의 다른 글
| [데이터분석] 인터렉티브, 마크다운 실습 (0) | 2024.08.13 |
|---|---|
| [데이터분석] 텍스트마이닝 실습 (0) | 2024.08.12 |
| [데이터분석] 데이터 정제(전처리), 그래프 종류 확인 및 실습해보기 (0) | 2024.08.05 |
| [데이터분석] 판다스 활용하기, json파일 가져와서 데이터 나눠보기 (0) | 2024.08.03 |
| [ML] 랜덤 포레스트를 이용한 호텔 데이터 다루기 (1) | 2024.07.14 |



