지난 33번에 이어~
스케일드 닷-프로덕트 어텐션을 구현해보겠습니다.
5) 스케일드 닷-프로덕트 어텐션 구현하기

위의 식을 이용해서 구현해본 함수는 아래에있습니다.
def scaled_dot_product_attention(query, key, value, mask):
# query 크기 : (batch_size, num_heads, query의 문장 길이, d_model/num_heads)
# key 크기 : (batch_size, num_heads, key의 문장 길이, d_model/num_heads)
# value 크기 : (batch_size, num_heads, value의 문장 길이, d_model/num_heads)
# padding_mask : (batch_size, 1, 1, key의 문장 길이)
# Q와 K의 곱. 어텐션 스코어 행렬.
matmul_qk = tf.matmul(query, key, transpose_b=True)
#스케일링
#dk의 제곱근값으로 나눠준다.
depth = tf.cast(tf.shape(key)[-1], tf.float32)
logit = matmul_qk / tf.math.sqrt(depth)
# 패딩마스크. (이 내용은 나중에 설명합니다)
# 어텐션 스코어 행렬의 마스킹 할 위치에 매우 작은 음수값을 넣는다.
# 매우 작은 값이므로 소프트맥스 함수를 지나면 행렬의 해당 위치의 값은 0이 된다.
if mask is not None:
logits += (mask * -1e9)
# 소프트맥스 함수는 마지막 차원인 key의 문장 길이 방향으로 수행된다.
# attention weight : (batch_size, num_heads, query의 문장 길이, key의 문장 길이)
attention_weight = tf.nn.softmax(logits, axis=1)
output = tf.matmul(attention_weight, value)
# output : (batch_size, num_heads, query의 문장 길이, d_model/num_heads)
return output, attention_weight
함수를 구현하고 동작을 확인해봐야하는데
# 동작확인
# 임의의 Query, Key, Value인 Q, K, V 행렬 생성
np.set_printoptions(suppress=True) # 작은 부동소수점 숫자의 지수 표기(scientific notation)를 일반 소수점 표기
temp_k = tf.constant([[10,0,0],
[0,10,0],
[0,0,10],
[0,0,10]], dtype=tf.float32) # (4, 3)
temp_v = tf.constant([[ 1,0],
[ 10,0],
[ 100,5],
[1000,6]], dtype=tf.float32) # (4, 2)
temp_q = tf.constant([[0, 10, 0]], dtype=tf.float32) # (1, 3)
q는 k와 동일한 값을 가지고 있다는것을 주목해주세용
q는 4개의 k값에 대해서 2번째와 강하게 일치하고있습니다.
temp_out, temp_attn = scaled_dot_product_attention(temp_q, temp_k, temp_v, None)
print(temp_attn) #어텐션 분포값
print(temp_out) #어텐션 값
# tf.Tensor([[0. 1. 0. 0.]], shape=(1, 4), dtype=float32)
# tf.Tensor([[10. 0.]], shape=(1, 2), dtype=float32)[0,1,0,0]이라고 해서 2번째 값인 10. 0 으로 출력되고있는것을 확인할 수 있습니다.
값을 다른걸로 바꿔서 해보면
temp_q = tf.constant([[0,0,10]],dtype=tf.float32)으로 변경해보았습니다. 이렇게 temp_k의 3번째4번째 값과 비슷하게 나올것입니다.
temp_out, temp_attn = scaled_dot_product_attention(temp_q, temp_k, temp_v, None)
print(temp_attn) #어텐션 분포값
print(temp_out) #어텐션 값
# tf.Tensor([[0. 0. 0.5 0.5]], shape=(1, 4), dtype=float32)
# tf.Tensor([[550. 5.5]], shape=(1, 2), dtype=float32)3번째와 4번째가 동일한 확률이 나옵니다. 결과적으로는 550과 5.5로 나누어줍니다.
0.5, 0.5는 소프트맥스라서 합치면 1이나오겠죵
value의 세번재 값 [100, 5 ]에 0.5를 곱한 값 | value의 네번째값 [1000,6]에 0.5를 곱한 값
위 두개를 합한 값 =>[100 * 0.5 + 1000*0.5] = 550,5.5 의 결과가 나오게 됩니다.
이어서 좀 더 3개의 qurey값을 함수의 입력으로 사용해보자면
# 3개의 qurey값을 함수 입력으로 사용해보기
temp_q = tf.constant([[0,0,10], [0,10,0], [10,10,0]],dtype=tf.float32)
# 3*2짜리가 나와야할것같습니다.
temp_out, temp_attn = scaled_dot_product_attention(temp_q, temp_k, temp_v, None)
print(temp_attn) #어텐션 분포값
print(temp_out) #어텐션 값
이렇게 됩니다.
이상!
스케일드 닷-프로덕트 어텐션을 논문에 기반해서 작성을 해보았습니다.
6) 멀티헤드어텐션(Multi-head-attention)
병렬어텐션이고 앞에서 배운 어텐션은 디모델의 차원을 가진 벡터를 넘헤드스로 나눈 차원을 가지는 QKV벡터로 바꾸고 어텐션을 수행합니다.
논문기준으로는 512의 차원의 각 단어 벡터를 8로 나누어 64차원의 QKV벡터로 바꾸어서 어텐ㅅ녀을 수행한 셈인데,
이제 num_heads의 의미와 왜 디모델의 차원을 가진 단어 벡터를 가지고 어텐션을 하지 않고 차원을 축소시킨 벡터로 어텐션을 수행하였는지 알아봅시다.
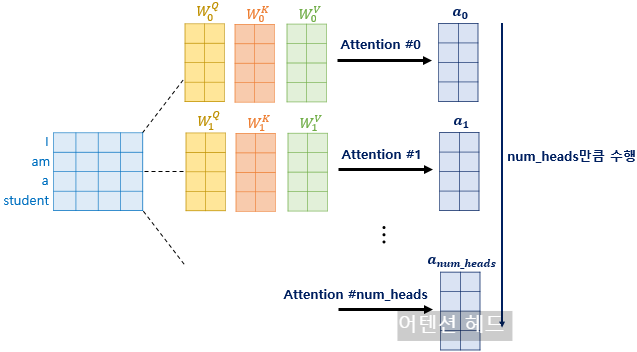
트랜스포머 연구진은 한 번의 어텐션을 하는 것보다 여러번의 어텐션을 병렬로 사용하는 것이 더 효과적이라고 판단하였습니다.
그래서 dmodel 의 차원을 num_heads 개로 나누어 dmodel/num_heads 의 차원을 가지는 Q, K, V에 대해서 num_heads 개의 병렬 어텐션을 수행합니다.
논문에서는 하이퍼파라미터인 num_heads 의 값을 8로 지정하였고, 8개의 병렬 어텐션이 이루어지게 됩니다.
다시 말해 위에서 설명한 어텐션이 8개로 병렬로 이루어지게 되는데,
이때 각각의 어텐션 값 행렬을 어텐션 헤드라고 부릅니다.
이때 가중치 행렬 WQ,WK,WV 의 값은 8개의 어텐션 헤드마다 전부 다릅니다.
사이킷런할때 트리를 여러개해서 학습했던것같은 (랜포 같은) 그런 느낌입니다.
병렬어텐션의 효과: 다른 시각으로 정보들을 수집할 수 있다.
예)
'The animal didn't cross the street, because it was too tired''그 동물은 길을 건너지 않았다. 왜냐하면 그것(it)은 너무 피곤하였기 때문이다.'
단어 그것(it)이 쿼리였다고 해봅시다.
즉, it에 대한 Q벡터로부터 다른 단어와의 연관도를 구하였을 때
첫번째 어텐션 헤드는 '그것(it)'과 '동물(animal)'의 연관도를 높게 본다면,
두번째 어텐션 헤드는 '그것(it)'과 '피곤하였기 때문이다(tired)'의 연관도를 높게 볼 수 있습니다.
각 어텐션 헤드는 전부 다른 시각에서 보고있기 때문입니다.

병렬 어텐션을 모두 수행하였다면 모든 어텐션 헤드를 연결(concatenate)합니다.
모두 연결된 어텐션 헤드 행렬의 크기는 (seq_len,dmodel) 가 됩니다
지금까지 그림에서는 학습 지면상의 한계로 '4차원'을 dmodel =512로 표현하고, '2차원'을 dv =64로 표현해왔기 때문에 위의 그림의 행렬의 크기에 혼동의 있을 수 있으나 8개의 어텐션 헤드의 연결(concatenate) 과정의 이해를 위해 이번 행렬만 예외로 위와 같이 dmodel 의 크기를 dv 의 8배인 16차원으로 표현하였습니다
아래의 그림에서는 다시 dmodel 을 4차원으로 표현합니다

어텐션 헤드를 모두 연결한 행렬은 또 다른 가중치 행렬 W0 을 곱하게 되는데,
이렇게 나온 결과 행렬이 멀티-헤드 어텐션의 최종 결과물입니다.
위의 그림은 어텐션 헤드를 모두 연결한 행렬이 가중치 행렬 W0 과 곱해지는 과정을 보여줍니다.
이때 결과물인 멀티-헤드 어텐션 행렬은 인코더의 입력이었던 문장 행렬의 (seq_len,dmodel) 의 크기와 동일합니다.
인코더의 '입력'크기는 '출력'에서도 유지된다!
다시 말해 인코더의 첫번째 서브층인 멀티-헤드 어텐션 단계를 끝마쳤을 때,
인코더의 입력으로 들어왔던 행렬의 크기가 아직 유지되고 있음을 기억해둡시다.
첫번째 서브층인 멀티-헤드 어텐션과 두번째 서브층인 포지션 와이즈 피드 포워드 신경망을 지나면서 인코더의 입력으로 들어올 때의 행렬의 크기는 계속 유지되어야 합니다.
트랜스포머는 동일한 구조의 인코더를 쌓은 구조입니다.
논문 기준으로는 인코더가 총 6개입니다.
인코더에서의 입력의 크기가 출력에서도 동일 크기로 계속 유지되어야만 다음 인코더에서도 다시 입력이 될 수 있습니다.
7) 멀티 헤드 어텐션 구현하기
멀티 헤드 어텐션에서는 크게 두 종류의 가중치 행렬이 나왔습니다.
-Q, K, V 행렬을 만들기 위한 가중치 행렬인 WQ, WK, WV 행렬과
-바로 어텐션 헤드들을 연결(concatenation) 후에 곱해주는 WO 행렬입니다.
가중치 행렬을 곱하는 것을 구현 상에서는 입력을 전결합층. 즉, 밀집층(Dense layer)을 지나게 하여 구현합니다. 케라스 코드 상으로 지금까지 사용해왔던 Dense()에 해당됩니다.
Dense(units)
class MultiHeadAttention(tf.keras.layers.Layer):
def __init__(self, d_model, num_heads, name="multi_head_attention"):
super(MultiHeadAttention, self).__init__(name=name)
self.num_heads = num_heads
self.d_model = d_model
assert d_model % self.num_heads == 0
# d_model을 num_heads로 나눈 값.
# 논문 기준 : 64
self.depth = d_model // self.num_heads
# WQ, WK, WV에 해당하는 밀집층 정의
self.query_dense = tf.keras.layers.Dense(units=d_model)
self.key_dense = tf.keras.layers.Dense(units=d_model)
self.value_dense = tf.keras.layers.Dense(units=d_model)
# WO에 해당하는 밀집층 정의
self.dense = tf.keras.layers.Dense(units=d_model)
# num_heads 개수만큼 q, k, v 를 split 함수
def split_heads(self, inputs, batch_size):
inputs = tf.reshape(
inputs, shape=(batch_size, -1, self.num_heads, self.depth))
return tf.transpose(inputs, perm=[0, 2, 1, 3])
def call(self, inputs):
query, key, value, mask =\
inputs['query'], inputs['key'], inputs['value'], inputs['mask']
batch_size = tf.shape(query)[0]
# 1. WQ, WK, WV에 해당하는 밀집층 지나기
# q : (batch_size, query의 문장 길이, d_model)
# k : (batch_size, key의 문장 길이, d_model)
# v : (batch_size, value의 문장 길이, d_model)
# 참고) 인코더(k, v)-디코더(q) 어텐션에서는 query 길이와 key, value의 길이는 다를 수 있다.
query = self.query_dense(query)
key = self.key_dense(key)
value = self.value_dense(value)
# 2. 헤드 나누기
# q : (batch_size, num_heads, query의 문장 길이, d_model/num_heads)
# k : (batch_size, num_heads, key의 문장 길이, d_model/num_heads)
# v : (batch_size, num_heads, value의 문장 길이, d_model/num_heads)
query = self.split_heads(query, batch_size)
key = self.split_heads(key, batch_size)
value = self.split_heads(value, batch_size)
# 3. 스케일드 닷 프로덕트 어텐션. 앞서 구현한 함수 사용.
# (batch_size, num_heads, query의 문장 길이, d_model/num_heads)
scaled_attention, _ = scaled_dot_product_attention(query, key, value, mask)
# (batch_size, query의 문장 길이, num_heads, d_model/num_heads)
scaled_attention = tf.transpose(scaled_attention, perm=[0, 2, 1, 3])
# 4. 헤드 연결(concatenate)하기
# (batch_size, query의 문장 길이, d_model)
concat_attention = tf.reshape(scaled_attention, (batch_size, -1, self.d_model))
# 5. WO에 해당하는 밀집층 지나기
# (batch_size, query의 문장 길이, d_model)
outputs = self.dense(concat_attention)
return outputs
사실 지금 하고있는 트랜스포머는 너무 어렵고 복잡하고 깊은 구조층이라서 한번에 절대못할거같고
기록을 해 둔다음 조금더 살을 붙이는 방법으로좀 더 깊게 학습을 할 예정입니다.
코드를 조금 더 보자면
트랜스포머모델의 핵심 구성요소인 멀티헤드 어텐션을 구현한것이고
1. 클래스 초기화
def __init__(self, d_model, num_heads, name="multi_head_attention"):d_model 모델의 전체 차원이고
num_heads는 어텐션의 헤드의 개수 (논문기준8)
어텐션 계산을 위해서 입력 쿼리,키,값을 num_heads 개수만큼 나누고 병렬로 처리합니다.
2. 헤드를 나누는 함수(split_heads)
def split_heads(self, inputs, batch_size):
inputs = tf.reshape(inputs, shape=(batch_size, -1, self.num_heads, self.depth))
return tf.transpose(inputs, perm=[0, 2, 1, 3])
inputs(Q,K,V)을 헤드 개수만큼 나눕니다.
차원을 변환해서 멀티헤드 계산을 쉽게 만들어요
3. call 매서드(전체 동작의 흐름)
query, key, value, mask = inputs['query'], inputs['key'], inputs['value'], inputs['mask']
batch_size = tf.shape(query)[0]
Q,K,V입력텐서들, mask : 어텐션 계산시 무시해야할 위치를 표시합니다.
query = self.query_dense(query)
key = self.key_dense(key)
value = self.value_dense(value)입력 데이터를 Dense 레이어를 통과시켜 Query, Key, Value를 생성.
차원: (batch_size, 문장 길이, d_model)
query = self.split_heads(query, batch_size)
key = self.split_heads(key, batch_size)
value = self.split_heads(value, batch_size)각 입력(Query, Key, Value)을 헤드별로 분리.
결과 차원: (batch_size, num_heads, 문장 길이, depth).
scaled_attention, _ = scaled_dot_product_attention(query, key, value, mask)스케일드 닷 프로덕트 어텐션을 계산합니다.
내적(dot product)을 통해 어텐션 점수를 계산.
점수를 소프트맥스(Softmax)로 정규화하여 가중치를 생성.
값(Value)에 가중치를 곱해 최종 어텐션 값을 얻음.
출력 차원: (batch_size, num_heads, 문장 길이, depth).
scaled_attention = tf.transpose(scaled_attention, perm=[0, 2, 1, 3])
concat_attention = tf.reshape(scaled_attention, (batch_size, -1, self.d_model))병렬 계산한 헤드 결과를 다시 합칩니다.
차원 변환:
tf.transpose: (batch_size, 문장 길이, num_heads, depth).
tf.reshape: (batch_size, 문장 길이, d_model).
↓ 최종변환
outputs = self.dense(concat_attention)합쳐진 어텐션 값을 Dense 레이어에 통과시켜 최종 결과 생성.
출력 차원: (batch_size, 문장 길이, d_model).
8) 패딩마스크(Padding Mask)
앞서 구현한 스케일드 닷 프로덕트 어텐션 함수 내부를 보면 mask라는 값을 인자로 받아서 mask값에 -1e9 라는 아주 작은 음수값을 곱한 후 어텐션 스코어 행렬에 더해주고있는데 왜 그럴까요?
def scaled_dot_product_attention(query, key, value, mask):
... 중략 ...
logits += (mask * -1e9) # 어텐션 스코어 행렬인 logits에 mask*-1e9 값을 더해주고 있다.
... 중략 ...이는 문장에 <PAD>토큰이 있을경우 어텐션에서 사실상 제외하기 위한 연산입니다.
예를들어서 <pad>가 포함된 입력 문장의 셀프 어텐션의 예제를 봅시다. 이에 대해서 어텐션을 수행하고
어텐션 스코어 행렬을 얻는 과정은 아래 사진과같습니다.

그런데 사실 pad의 경우에는 실질적인 의미를 가진 단어가 아닙니다.
그래서 트랜스포머에서는 key의 경우에 pad토큰이 존재한다면 이에 대해서는 유사도를 구하지 않도록
마스킹(어텐션에서 제외하기 위해 값을 가리는 의미)을 해주기로했습니다.
어텐션 스코어 행렬에서 행에 해당하는 문장은 qurey고 열에 해당하는 문장은 key입니다.
그리고 key에 pad가 있는 경우에는 헤당 열 전체를 마스킹합니다.

마스킹을 하는 방법은 어텐션 스코어 행렬의 마스킹 위치에 매우 작은 음수값을 넣어주는 것입니다.
여기서 매우 작은 음수값은 -무한대에 가까운 수를 의미합니다.
현재 어텐션 스코어 함수는 소프트맥스 함수를 지나지 않은 상태입니다. 앞서 배운 연산 순서라면 어텐션 스코어 함수는
소프트맥스 함수를 지나고 그 후 value행렬과 곱해지게 됩니다.
그런데 현재 마스킹 위치에 매우 작은 음수값이 들어가있으므로 어텐션 스코어 행렬이 소프트맥스 함수를 지난 후에는 해당 위치의 값은 0이되어 단어 간 유사도를 구하는 일에 <pad>토큰이 반영되지 않게 됩니다.

이 그림은 소프트맥스 함수를 지난 후를 가정하고있습니다. 소프트맥스 함수를 지나면 각 행의 어텐션 가중치의 총합은 이되는데 단어pad의 경우에는 0이 되어 어떤 유의미한 값을 가지고 있지 않습니다.
패딩마스크 구현해보기
# <pad> 는 0
# 정수 시퀀스에서 0인 경우 1로 변환, 그렇지 않은 경우 0으로 변환
def create_padding_mask(x):
mask = tf.cast(tf.math.equal(x, 0), tf.float32)
return mask[:, tf.newaxis, tf.newaxis, :]# 동작 확인
create_padding_mask(tf.constant([[1, 21, 777, 0, 0]]))
결과값
<tf.Tensor: shape=(1, 1, 1, 5), dtype=float32, numpy=array([[[[0., 0., 0., 1., 1.]]]], dtype=float32)>
정수 시퀀스가 0인경우는 1로 변환하고 그렇지 않은 경우는 0으로 변환하는데
패딩마스크를 생성해야하기때문입니다.
그래서 pad토큰이 0으로 표시된경우는 이를 1로 변환해서 어텐션 계산에서 무시되도록 하는거죠.
즉 입력x에서 pad토큰값이 0인 부분을 찾아서 mask를 생성하고
트랜스포머 모델에서 어텐션계산할때 패딩이 있는 위치는 무시합니다.
왜 무시하냐면 학습에 불필요하기때문에 무시하게됩니다.
'AI > 자연어처리' 카테고리의 다른 글
| Transformer (33-4 한국어 챗봇 구현하기) (1) | 2025.01.03 |
|---|---|
| Transformer (33-3) (1) | 2025.01.02 |
| Transformer (33) (0) | 2024.12.31 |
| [AI활용 자연어처리 챗봇프로젝트] 인코더 디코더 Seq2Seq (0) | 2024.12.30 |
| [AI활용 자연어처리 챗봇프로젝트] bi-LSTM, bi-LSTM 실습 (2) | 2024.12.23 |



