1. 포켓몬 분류
이번에는 포켓몬데이터를 가지고 분류를할건데
트레인 데이터는 149종, Vaildation은 898종이 들어있습니다.
둘의 데이터가 달라서 898종을 149종으로 줄일거입니다.
import os
os.environ['KAGGLE_USERNAME'] = '닉네임'
os.environ['KAGGLE_KEY'] = 'key'!kaggle datasets download -d thedagger/pokemon-generation-one-d는 몇번하니까 디렉토리에 같은 이름폴더가 있어서.. 삭제를 해주었습니다.
그리고 나서 다시 압축파일 풀기
!unzip -q /content/pokemon-generation-one.zip
# 테스트로 쓸 데이터셋 api
!kaggle datasets download -d hlrhegemony/pokemon-image-dataset
압축 풀기
!unzip -q /content/pokemon-image-dataset.zip데이터셋 정리하기
!mv dataset train #dataset의 데이터를 train 폴더(생성)로 이동그래서 보면 train폴더안에 데이터셋이 있는것을 확인할 수 있습니다.
그런데 또 내려보면 같은 폴더가 하나 더 있습니다.
고로! 중복은 삭제하도록 하겠습니다.
!rm -rf train/dataset이렇게 되면 train안에는 내가 학습시킬 데이터 셋이 들어가있는게 됩니다.
!mv images vaildationimages라는 폴더를 vaildation으로 이동합니다.
train_labels = os.listdir('train')
print(train_labels)
print(len(train_labels))train폴더에 listdir(파일) 뿐만아니라 뭐가있던지 train_labels로 넣어줍니다.
그리고 2번째 줄을 출력하게되면 폴더이름이나오고 len을하게되면 몇종인지 나오게됩니다.
149종이 잘 나오는것을 확인할 수 있습니다.
val_labels = os.listdir('vaildation')
print(val_labels)
print(len(val_labels))위와 똑같이 진행하고 len은 898개가 나옵니다.
이름 겹치는 부분만 남기고 나머지는 vaildation 에서 삭제를 해도 가능합니다.
그래서 삭제해주려고 합니다.
import shutil모듈을 사용합니다.
파일을 삭제하거나 이동하거나 이런걸 되게 자유롭게 해줍니다. (파일관련 모듈)
for val_label in val_labels:
if val_label not in train_labels: #포함되어있지 않다면
shutil.rmtree(os.path.join('vaildation', val_label))## 코드해석
val_label, val_labels 를 돌면서 val_label이 train_labels에 포함되어있지 않다면~
rmtree(삭제)해라~ 라는 뜻입니다.
val_labels = os.listdir('vaildation')
print(len(val_labels))
#1472개가 더 지워졌는데 왜그럴까요(?)
2개가 공통점이 없었다는거죠 그럼 train 데이터 2개를 넣어주거나 지우거나를 해줘야겠죠
저는 같이 돌리려고하는데 갯수가 같아야되니까요!
저는 데이터 2개를 넣는것으로 해보았습니다.
#train 데이터는 있고, val 데이터에는 없는 포켓몬 종류??
for train_label in train_labels:
if train_label not in val_labels:
print(train_label)
#Farfetchd
#MrMime#데이터가 없는 녀석들의 폴더를 생성
for train_label in train_labels:
if train_label not in val_labels:
print(train_label)
os.makedirs(os.path.join('validation', train_label), exist_ok=True)
이렇게 파일이 잘 생긴것을 확인할 수 있습니다.
그리고 빈 디렉터리에 사진 2장 정도를 train에서 받아서 넣어주었습니다.
코랩을 이탈했다 다시들어오면 파일을 다시 넣어줘야합니다.
val_labels = os.listdir('validation')
len(val_labels)이후에 validation 의 값이 train 의 데이터 값과 같아야하므로
len함수를 통해 찍어보니 149개가 나옵니다. 동일하게 맞췄습니다.
이후에 필요한 모듈들을 임포트 하고 가져와줍니다.
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
from torchvision import datasets, models, transforms
from torch.utils.data import DataLoaderdevice = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
deviceGPU를 사용해야한다면 사용하는데.. 저는 코랩 GPU를 다 써버려서 그냥 일반으로 진행했습니다.
(추후 에포크 돌릴때 무쟈게 시간이 사용됨)
##transforms.Compose()
data_transforms = {
'train': transforms.Compose([
transforms.Resize((224, 224)),
transforms.RandomAffine(0, shear=10, scale=(0.8, 1.2)),
transforms.RandomHorizontalFlip(),
transforms.ToTensor()
]),
'validation': transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor()
])
}똑같이 각각 'train' 데이터의 사이즈 변경, 사진 Affine, HorizontalFlip를 하주고 Tensor형으로 바꾸어줍니다.
'validation'은 사이즈와 텐서형으로만 변경해줍니다.
##데이터셋
image_datasets = {
'train': datasets.ImageFolder('train', data_transforms['train']),
'validation': datasets.ImageFolder('validation', data_transforms['validation'])
}train 이미지폴더 데이터셋과, validation 이미티 폴더데이터셋을 저장헤줍니다
###데이터로더
dataloaders = {
'train': DataLoader(
image_datasets['train'],
batch_size=32,
shuffle=True
),
'validation': DataLoader(
image_datasets['validation'],
batch_size=32,
shuffle=False
)
}len(image_datasets['train']), len(image_datasets['validation'])
###시각화
#시각화
imgs, labels = next(iter(dataloaders['train']))
fig, axes = plt.subplots(4, 8, figsize=(16, 8))
for ax, img, label in zip(axes.flatten(), imgs, labels):
ax.imshow(img.permute(1, 2, 0))
ax.set_title(label.item()),
ax.axis('off')
image_datasets['train'].classes[14]14번 인덱스를 찍으면 Charmander을 확인할 수 있습니다
classes를 쓰게되면 모든 datasets가 나오게 됩니다.
2. EfficientNet
- EfficientNet
- 구글의 연구팀이 개발한 이미지 분류, 객체 검출 등 컴퓨터 비전 작업에서 높은 성능을 보여주는 신경망 모델
- 신경망의 깊이, 너비, 해상도를 동시에 확장하는 방법을 통해 효율성과 성능을 극대화한 것이 특징
- EfficientNetB4를 사용할건데 이건 EfficientNet시리즈의 중간 크기 모델
컴퓨터 비전에서 사용되는 모델 중 하나입니다.
최근 업데이트하는데에 수정을 하거나 모델을 변경할 수 있습니다.
from torchvision.models import efficientnet_b4, EfficientNet_B4_Weights
from torchvision.models._api import WeightsEnum
from torch.hub import load_state_dict_from_url1줄이 지금 현재 불안정하기때문에 2,3줄을 쓰고
1줄이 완전하다면 밑에 함수는안써도됩니다.
#보안코드때문에 쓰이는 함수
def get_state_dict(self, *args, **kwargs):
kwargs.pop("check_hash")
return load_state_dict_from_url(self.url, *args, **kwargs)
WeightsEnum.get_state_dict = get_state_dict
정상적이든 비정상적이든 상관없이 써야하는 모델생성코드입니다.
#모델 만들기
model = efficientnet_b4(weights=EfficientNet_B4_Weights.IMAGENET1K_V1).to(device)model
맨 마지막 줄.
(avgpool): AdaptiveAvgPool2d(output_size=1)
(classifier): Sequential(
(0): Linear(in_features=1792, out_features=512, bias=True)
(1): ReLU()
(2): Linear(in_features=512, out_features=149, bias=True)
)
)굉장히 길지만 저희는 맨 마지막 부분만 확인하면 됩니다.
B4모델에는
이름
Conv2d를시켜주고
노멀라이즈 활용하고
실루(렐루와 비슷)를 실행하고,
레이어를 많이 쌓아서 만든 모델입니다.
#프리즌 하기 (모델 파라미터 수정하지 않으려고 함)
for param in model.parameters():
param.requires_grad = False
model.classifier = nn.Sequential(
nn.Linear(1792, 512),
nn.ReLU(),
nn.Linear(512, 149)
).to(device)
1.위에 1792를 받고, 512개로 줄이고
2.렐루사용
3.(512, 149)
-분류에 대한 함수를 사용할 필요가 없습니다 분류를 할라면 확률로 내보내주는 Softmax를 사용해야하는데
소프트 맥스는 다중함수에서는 nn에다 직접 적지 않습니다.
이유는 오차함수에 sofrmax가 들어있기때문에 따로 기재할 필요가 없습니다.
model
#결과
(avgpool): AdaptiveAvgPool2d(output_size=1)
(classifier): Sequential(
(0): Linear(in_features=1792, out_features=512, bias=True)
(1): ReLU()
(2): Linear(in_features=512, out_features=149, bias=True)
)
)###옵티마이저
optimizer = optim.Adam(model.classifier.parameters(), lr=0.001)
#학습시키기(에포크)
for epoch in range(epochs):
for phase in ['train', 'validation']:
if phase == 'train':
model.train()
else:
model.eval()
sum_losses = 0
sum_accs = 0
for x_batch, y_batch in dataloaders[phase]:
x_batch = x_batch.to(device)
y_batch = y_batch.to(device)
y_pred = model(x_batch)
loss = nn.CrossEntropyLoss()(y_pred, y_batch)
if phase == 'train':
optimizer.zero_grad()
loss.backward()
optimizer.step()
sum_losses = sum_losses + loss
y_prob = nn.Softmax(1)(y_pred)
y_pred_index = torch.argmax(y_prob, axis=1)
acc = (y_batch == y_pred_index).float().sum() / len(y_batch) * 100
sum_accs = sum_accs + acc
avg_loss = sum_losses / len(dataloaders[phase])
avg_acc = sum_accs / len(dataloaders[phase])
print(f'{phase:10s}: Epoch {epoch+1:4d}/{epochs} Loss: {avg_loss:.4f} Accuracy: {avg_acc:.2f}%')그런데 여기까지 하면 CPU로 시간이 너무 오래걸리기때문에 이미 학습된 model.pth를 받아서 돌렸습니다.
#학습된 모델 파일을 저장(pth=확장자)
torch.save(model.state_dict(), 'model.pth') #model.h5
**혹시 학습이 잘 되었다면 pth 확장자로 저장할 수 있는데 위에 작성된 코드입니다**
*h5 는 원래는 텐서플로우 확장명입니다.
이제 다시 불러오고싶을때는 아래 코드를가져오면됩니다.
model = models.efficientnet_b4().to(device)그러면 model껍데기를 가져온거겠죠?
이미 model을 생성할때 가중치를 함께 적어놨기떄문에 가중치는 따로 가져올 필요는 없습니다
model.classifier = nn.Sequential(
nn.Linear(1792, 512),
nn.ReLU(),
nn.Linear(512, 149)
).to(device)model가중치가 변경된것이 확인됩니다.
model.load_state_dict(torch.load('model.pth'))
# model.load_state_dict(torch.load('model.pth'), strict=False)
# model.load_state_dict(torch.load('model.pth'), map_location=torch.device('cpu'))위 코드를 시키면 모델에는 가중치가 저장이 됩니다.
검증모드 변경
model.eval()from PIL import Imageimg1 = Image.open('validation/Ditto/1.jpg')
img2 = Image.open('validation/Golem/4.jpg')
fig, axes = plt.subplots(1, 2, figsize=(12, 6))
axes[0].imshow(img1)
axes[0].axis('off')
axes[1].imshow(img2)
axes[1].axis('off')
plt.show()

여기서 plt.show를 해서 이미가 잘 들어간것을 확인할 수 있스빈다.
img1_input = data_transforms['validation'](img1)
img2_input = data_transforms['validation'](img2)
print(img1_input.shape)
print(img2_input.shape) torch.Size([3, 224, 224])
torch.Size([3, 224, 224])
로 결과가 나오게 됩니다.
test_batch = torch.stack([img1_input, img2_input])
test_batch = test_batch.to(device)
test_batch.shape
torch.Size([2, 3, 224, 224])y_pred = model(test_batch)
y_pred
여기까지는 img1, 2의 각각의 결과입니다.
소프트맥스는 확률로 변환해주는거니까
확률로 변환해보도록 하겠습니다
y_prob = nn.Softmax(1)(y_pred)
y_prob
probs, idx = torch.topk(y_prob, k=3)
print(probs)
print(idx)확률에서 3개만 뽑아보도록 하겠습니다.
tensor([[0.0074, 0.0073, 0.0072], #1번이미지 확률
[0.0074, 0.0073, 0.0072]], grad_fn=<TopkBackward0>) #2번 이미지 확률
tensor([[ 89, 39, 101], # 1번이미지와 비슷한 3개 뽑은거
[126, 62, 41]]) #2번 이미지와 비슷한 3개를 뽑은것
fig, axes = plt.subplots(1, 2, figsize=(15, 6))
axes[0].set_title('{:.2f}% {}, {:.2f}% {}, {:.2f}% {}'.format(
probs[0, 0] * 100,
image_datasets['validation'].classes[idx[0, 0]],
probs[0, 1] * 100,
image_datasets['validation'].classes[idx[0, 1]],
probs[0, 2] * 100,
image_datasets['validation'].classes[idx[0, 2]],
))
axes[0].imshow(img1)
axes[0].axis('off')
axes[1].set_title('{:.2f}% {}, {:.2f}% {}, {:.2f}% {}'.format(
probs[1, 0] * 100,
image_datasets['validation'].classes[idx[1, 0]],
probs[1, 1] * 100,
image_datasets['validation'].classes[idx[1, 1]],
probs[1, 2] * 100,
image_datasets['validation'].classes[idx[1, 2]],
))
axes[1].imshow(img2)
axes[1].axis('off')

이건 파라미터가 무시된 형태로 되어서 그런지 값을 제대로 찾지 못하는결과가 나옵니다.
gpu를 다써버려서 cpu를 사용했지만 전달받은 model.pth는 gpu로 실행이 되어서 그런것같습니다..
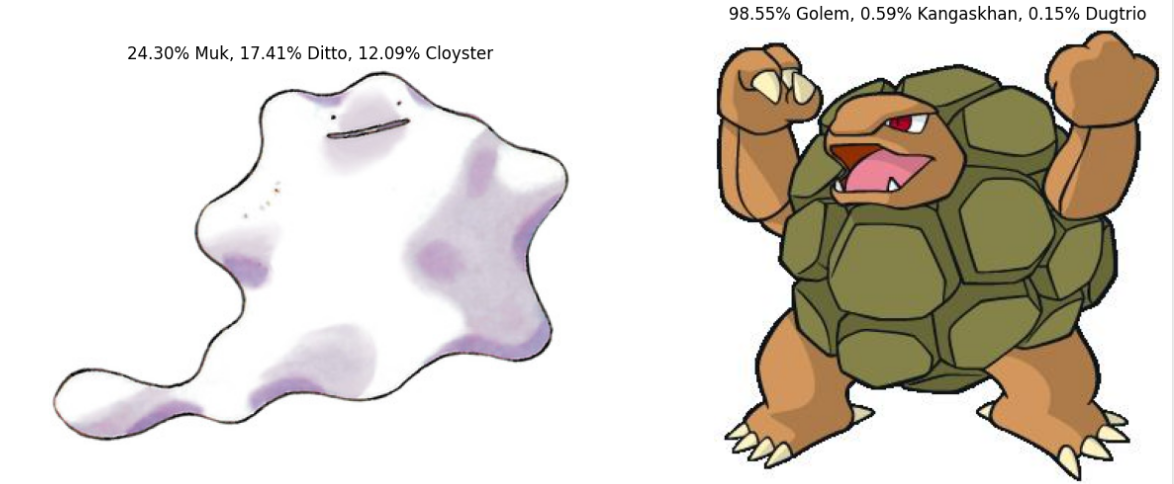
gpu로 처음부터 돌리니까 잘되는것을 확인할 수 있습니다.
#####이미지 1개를 넣고 가져다가 나와 닮은 포켓몬 찾기
mypic = Image.open('이미지 경로')
plt.imshow(mypic)
plt.axis('off')mypic_input = data_transforms['validation'](mypic)
print(mypic_input.shape)
mypic_input = mypic_input.unsqueeze(0).to(device)
print(mypic_input.shape)
y_pred = model(mypic_input)
y_pred
y_prob = nn.Softmax(1)(y_pred)
y_prob
probs, idx = torch.topk(y_prob, k=3)
print(probs)
print(idx)
plt.title('{:.2f}% {}, {:.2f}% {}, {:.2f}% {}'.format(
probs[0, 0] * 100,
image_datasets['validation'].classes[idx[0, 0]],
probs[0, 1] * 100,
image_datasets['validation'].classes[idx[0, 1]],
probs[0, 2] * 100,
image_datasets['validation'].classes[idx[0, 2]],
))
plt.imshow(mypic)
plt.axis('off')
이 친구 닮았다고 나오네요..^^

'AI 컴퓨터 비전프로젝트 > [ML,DL]머신러닝,딥러닝' 카테고리의 다른 글
| [DL] 영상이어붙이기, 키이벤트, 사진 효과(add,blending...) (0) | 2024.08.09 |
|---|---|
| [DL] 딥러닝 기초_파일 형식, open cv (1) | 2024.08.07 |
| [ML/DL] 전이학습, 케글 데이터셋 활용해서 에일리언vs프레데터 예측하기 (1) | 2024.07.30 |
| [DL] CNN 모델만들기,MNLIST 분류 (0) | 2024.07.28 |
| [DL] CNN 기초, 체험사이트 (0) | 2024.07.27 |



