1. 데이터 로더(Data Loader)
- 데이터 양이 많을 때 배치 단위로 학습하는 방법을 제공
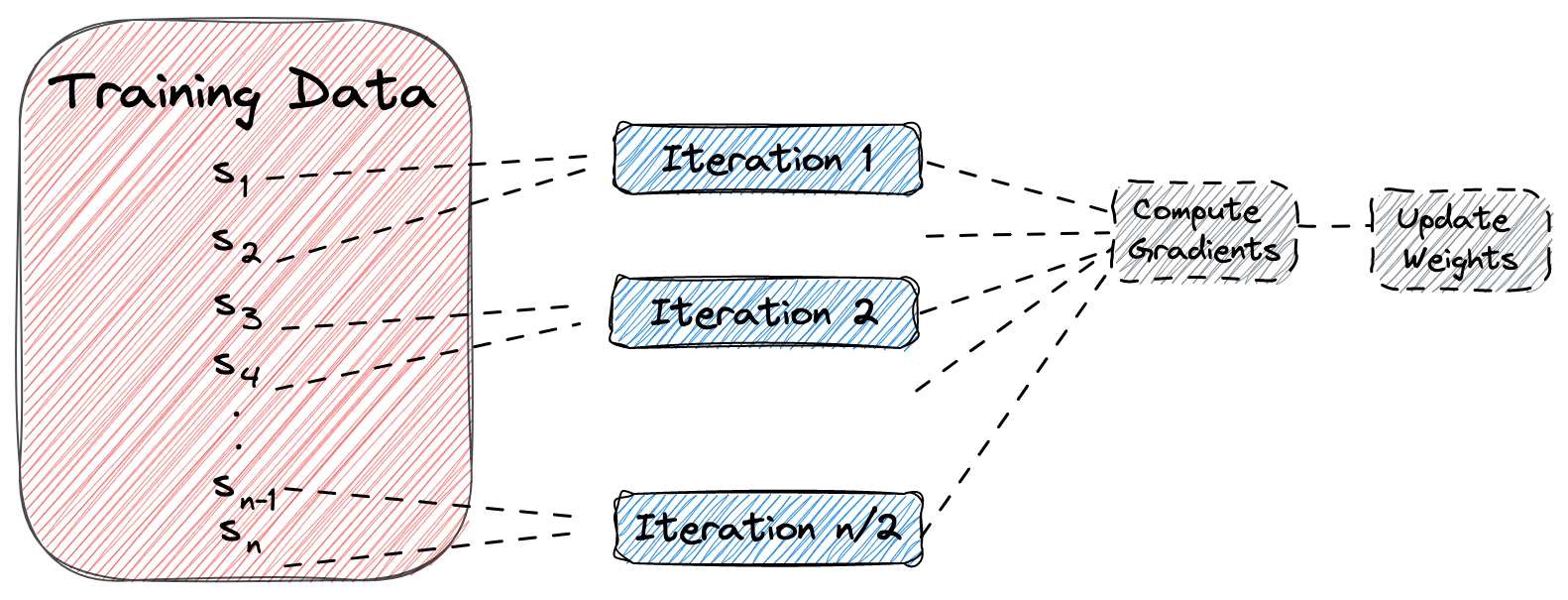
데이터를 쪼깬 후 그 작은 데이터를 학습시키고 다시 또 내보내는 역할을 합니다.
2. 손글씨 인식 모델 만들기
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
#디바이스를 쿠바로 사용할 수 있도록 하려고 합니다.
device = 'cuda' if torch.cuda.is_available() else 'cpu'
device
#데이터셋 가져오기
digits = load_digits()
X_data = digits['data']
y_data = digits['target']
print(X_data.shape)
print(y_data.shape)
#(1797, 64)
#(1797,)64개의 픽셀로 실행했다고 볼 수 있습니다.
x_data는 data를 y_data는 target을 가져옵니다.
#시각화 하기
# 그림을 그리기 위한 코드
# 2줄(row)과 5칸(column)으로 이루어진 그림판
# figsize=(14, 8) = 가로 14인치 세로 8인치
fig, axes = plt.subplots(nrows=2, ncols=5, figsize=(14, 8))
# 그림 그리기
# 그림판의 각 칸에 하나씩 그림을 그리기 위해 반복문 사용함.
# i == 몇번째 그림을 그리고 있는지 알려주는숫자
# ax == 현재 그릴 위치를 알려주는 칸
for i,ax in enumerate(axes.flatten()):
#x_data[i]== i번째 숫자 그림
#reshape(8*8) == 숫자그림을 8*8 크기의 모양으로 바꿔줌
# cmap=gray == 그림을 회색으로 그려달라고 하기
ax.imshow(X_data[i].reshape(8,8), cmap='gray')
#제목을 붙여주는 부분
#y_daya[i] ==3 이라면 그 칸의 제목은 3
ax.set_title(y_data[i])
#그림 주위에 있는 선들을 없애주는 부분 off를 하게되면 그림만 깔끔하게 보입니다.
ax.axis('off')1줄: 전체적인 사이즈를 확인함
for문
8*8로 사이즈를 정해주고 cmap을 gray로 맞춰줍니다.
label을 타이틀로 삼고 찍어주었습니다.

#텐서형으로 변경하기
X_data = torch.FloatTensor(X_data)
y_data = torch.LongTensor(y_data)
print(X_data.shape)
print(y_data.shape)
#torch.Size([1797, 64])
#torch.Size([1797])
#데이터 나누기
x_train, x_test, y_train, y_test = train_test_split(X_data, y_data, test_size=0.2, random_state=2024)
#데이터 사이즈 확인하기
print(x_train.shape, y_train.shape)
print(x_test.shape, y_test.shape)
#데이터 분할하기
x_train, x_test, y_train, y_test = train_test_split(X_data, y_data, test_size=0.2, random_state=2024)print(x_train.shape, y_train.shape)
print(x_test.shape, y_test.shape)8:2로 잘 분할된것을 확인할 수 있습니다.
#데이터로더 구축하기
하는역할 : 데이터셋를 뭉텅이를 갖고있고 한번 학습을 할 때마다 내가원해준 배치사이즈만큼 뱉어주는 역할합니다.
직접 구현해도 되지만(이터레이터사용하기 ) 파이토치로 사용가능합니다.
loader = torch.utils.data.DataLoader(
dataset=list(zip(x_train, y_train)),
batch_size=64,
shuffle=True,
drop_last=False #짜투리를 쓸건지(true= 버려라, false=버리지마라)
)
imgs, labels = next(iter(loader)) #loader을 iterrater하게 순서를 나열해주고 next로 첫번째 블록을 뽑게 됩니다. 그러면 64개 이미지에 64개 정답이 들어가게 됩니다.
fig, axes = plt.subplots(nrows=8, ncols=8, figsize=(14, 14))
for ax, img, label in zip(axes.flatten(), imgs, labels):
ax.imshow(img.reshape(8,8), cmap='gray')
ax.set_title(str(label))
ax.axis('off')
#코드해석
#데이터 로더는 데이터를 조금씩 나누어서 가져오는 도구예요. 큰 데이터를 한 번에 처리하기 어렵기 때문에 작은 덩어리로 나누어 처리해요.
#여기서는 x_train과 y_train 데이터를 묶어서 한 번에 64개씩 가져오도록 설정해요.
#dataset=list(zip(x_train, y_train)): x_train과 y_train을 묶어서 데이터셋을 만듭니다. x_train은 이미지 데이터, y_train은 그 이미지에 해당하는 정답(라벨)입니다.
#batch_size=64: 한 번에 64개의 데이터(이미지와 라벨)를 가져옵니다.
#shuffle=True: 데이터를 무작위로 섞어서 가져옵니다.
#drop_last=False: 마지막 남은 데이터를 버리지 않습니다.
loader = torch.utils.data.DataLoader(
dataset=list(zip(x_train, y_train)),
batch_size=64,
shuffle=True,
drop_last=False)
#iter(loader): 데이터 로더를 순서대로 나열할 수 있는 도구로 만듭니다.
#next(...): 첫 번째 64개의 데이터를 가져옵니다.
#imgs에는 64개의 이미지가, labels에는 64개의 정답이 들어갑니다.
imgs, labels = next(iter(loader)
#plt.subplots(nrows=8, ncols=8, figsize=(14, 14)): 8줄과 8칸으로 이루어진 큰 그림판을 준비합니다. 전체 크기는 14인치 x 14인치입니다.
fig, axes = plt.subplots(nrows=8, ncols=8, figsize=(14, 14))
#zip(axes.flatten(), imgs, labels): 각 칸(ax), 이미지(img), 라벨(label)을 묶어서 차례대로 처리합니다.
#ax.imshow(img.reshape(8,8), cmap='gray'): 이미지를 8x8 크기로 바꾸고, 회색조(gray)로 칸에 그림을 그립니다.
#ax.set_title(str(label)): 해당 칸 위에 정답(라벨)을 제목으로 적습니다.
#ax.axis('off'): 칸 주위의 선을 없앱니다.
for ax, img, label in zip(axes.flatten(), imgs, labels):
ax.imshow(img.reshape(8,8), cmap='gray')
ax.set_title(str(label))
ax.axis('off')shuffle=True,
drop_last=False
짜투리를 쓸건지 안 쓸건지를 선택할 수있습니다.
그러면 False를 하게되면 그냥 짜투리 나머지값이 1로 돌게됩니다.

그 후 이미티, 라벨을 뱉어줄겁니다.
imgs, labels = 각각 x_train, y_train이 imgs, labels값에 들어가게 됩니다.
next라는 함수, iter함수를 사용하게되면 순서대로 나열되게 갹체를 만들어주고 next를 사용하면 가장 첫번째에있는것을 뽑게 됩니다.
그럼 imgs에 64개의 이미지 64개의 정답이 들어가게 됩니다.

이런식으로 8*8 개로 모양이 나타나게 됩니다.
#모델생성
model = nn.Sequential(
nn.Linear(64, 10),
)다중분류라서 Liner(64개의 데이터값이 들어오고, 나가는건 10개의 클래스로 아웃풋이죠)
그리고 다중분류라서 소프트맥스를 사용합니다.
소프트맥느는 크로스 앤트로피에 포함되어있기때문에 위에는 따로 적어주지앟습니다.
#옵티마이저 선언
optimizer = optim.Adam(model.parameters(), lr=0.01)아담을 사용했습니다.
#에포크
epochs = 100
#64개의 데이터를 활용해 오차값+정확도 구하기
for epoch in range(epochs + 1):
sum_losses = 0
sum_accs = 0
for x_batch, y_batch in loader:
y_pred = model(x_batch)
# 오차 값을 확인
loss = nn.CrossEntropyLoss()(y_pred, y_batch)
# 옵티마이저 초기화
optimizer.zero_grad()
# 기울기 구하기
loss.backward()
# 기울기 업데이트
optimizer.step()
# 오차를 더해서 누적시켜줌
sum_losses = sum_losses + loss
# 예측값을 넣어서 확률값을 얻기
y_prob = nn.Softmax(1)(y_pred)
# 가장 높은 값을 얻어서 변수 저장
y_pred_index = torch.argmax(y_prob, axis=1)\
# 맞췄는지 예측해보기
acc = (y_batch == y_pred_index).float().sum() / len(y_batch) * 100
# 누적시키기
sum_accs = sum_accs + acc
#전체 로스값 평균
avg_loss = sum_losses / len(loader)
#한 에폭에 대한 acc구하기
avg_acc = sum_accs / len(loader)
print(f'Epoch {epoch:4d}/{epochs} Loss: {avg_loss:.6f} Accuracy: {avg_acc:.2f}%')이렇게되면 학습이 잘 되고 에포크값을 50으로 주었다가 맨 마지막 값이 98로 정확도가 살짝 떨어져서
100으로 올렸습니다. 학습빈도를 높이니 확연하게 정확도가 100%로 높아진것을 확인할 수 있었습니다.
물론 오버피팅이되어서 테스트값에는 잘 되지않을수도 있다는점도 염두에 두어야 합니다.
#시각화하기
plt.imshow(x_test[10].reshape((8, 8)), cmap='gray')
print(y_test[10])x_test변수의 10번째를 8*8로 다시 모양을 만들어서 보면
tensor[7]이고 8*8 사이즈로 잘 보여지는것을 확인할 수 있습니다.

#테스트 확인해보기
y_pred = model(x_test)
y_pred[10]
#tensor([ -8.1957, -2.1434, -13.2778, -4.5141, -2.2247, -8.6100, -17.3419,
# 14.4257, 0.3651, 4.5746], grad_fn=<SelectBackward0>)
이건 값일뿐입니다.(확률아님)
#확률
y_prob = nn.Softmax(1)(y_pred)
y_prob[10]
#tensor([1.4984e-10, 6.3693e-08, 9.3007e-13, 5.9502e-09, 5.8723e-08, 9.9016e-11,
# 1.5976e-14, 9.9995e-01, 7.8263e-07, 5.2686e-05],
# grad_fn=<SelectBackward0>)이것도 실수가 꽤 깊어서 for문을 돌려서 다시 표현해보겠습니다.
for i in range(10):
print(f'숫자 {i}일 확률: {y_prob[10][i]:.2f}')
#숫자 0일 확률: 0.00
#숫자 1일 확률: 0.00
#숫자 2일 확률: 0.00
#숫자 3일 확률: 0.00
#숫자 4일 확률: 0.00
#숫자 5일 확률: 0.00
#숫자 6일 확률: 0.00
#숫자 7일 확률: 1.00
#숫자 8일 확률: 0.00
#숫자 9일 확률: 0.00
#테스트 정확도 알아보기
오버피팅될수도있으니 테스트 정확도를 확인해보기
y_pred_index = torch.argmax(y_prob, axis=1)
# y_test, y_pred_index 비교하기
accuracy = (y_test == y_pred_index).float().sum() / len(y_test) * 100
print(f'테스트 정확도는: {accuracy:.2f}% 입니다.')
#테스트 정확도는: 95.83% 입니다.
'AI 컴퓨터 비전프로젝트 > [ML,DL]머신러닝,딥러닝' 카테고리의 다른 글
| [DL] CNN 기초, 체험사이트 (0) | 2024.07.27 |
|---|---|
| [DL] 비선형 활성화 함수, 역전파 (0) | 2024.07.26 |
| [DL] 딥러닝_뉴런, 퍼셉트론,히든레이어... (1) | 2024.07.25 |
| [ML/DL] 파이토치,텐서,GPU (0) | 2024.07.18 |
| [ML/DL] 파이토치로 구현한 선형회귀_단항,최적화, 다중 선형회귀 (2) | 2024.07.18 |



