■ BERT(Bidirectional Encoder Representations from Transformers)
BERT는 트렌스포머에서 인코더쪽의 구조를 사용해서 만든 구조입니다.
결국 트랜스포머의 파생입니다.
▶ NLP에서의 사전 훈련(Pre-training)
- 사전 훈련된 모델에 약간의 조정해서 TASK에 사용할 수 있는 모델입니다
- 요즘 보통은 다 사전모델을 사용하고 있습니다.
▶사전 훈련된 워드 임베딩
- 워드 임베딩 방법론들 (Word2Vec, FastText, GloVe...)
어떤 테스크를 수행할때 임베딩을 사용하는 방법으로는 크게 두가지가있다.
1. 임베딩 층을 랜덤 초기화해서 처음부터 학습하기
2. 방대한 데이터로 word2vec등과 같은 임베딩 알고리즘으로 '사전훈련된' 임베딩 벡터들을 가져와 사용하는 방법입니다.
그러나 문제점이있는데...
이 두 가지 방법 모두 하나의 단어가 하나의 벡터값으로 맵핑되므로,
문맥을 고려하지 못 하여 다의어나 동음이의어를 구분하지 못하는 문제점이 있습니다.
가령, 한국어에는 '사과'라는 단어가 존재하는데 이 '사과'는 용서를 빈다는 의미로도 쓰이지만, 먹는 과일의 의미로도 사용됩니다.
그러나 임베딩 벡터는 '사과'라는 벡터에 하나의 벡터값을 맵핑하므로 이 두 가지 의미를 구분할 수 없었습니다.
이 한계는 사전 훈련된 언어 모델을 사용하므로서 극복할 수 있었으며
아래에서 언급할 ELMo나 BERT 등이 이러한 문제의 해결책입니다.
* ELMo는 이번에는 다루지 않음
▶사전 훈련된 언어 모델

LSTM모델을 학습하고 이전단어로 부터 다음단어를 예측하도록 학습한것(왼쪽)
사전훈련된 언어모델은 사람이 굳이 레이블을 지정하지 않아도 된다는 장점이 있겠죠

동의어 ,다의어를 구분할 수 없었던 문제점을 엘모모델을 가지고 해결할 수 있었습니다.
순환신경망에서 이렇게 탈피가 됩니다.
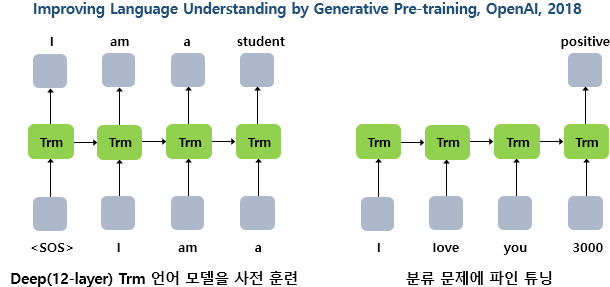
트렌스포머로 학습된 모델이 등장하게 됩니다.(Trm = 트랜스포머)
이전 단어로부터 다음 단어를 예측하게됩니다. chat GPT는 트랜스포머를 12개층으로 쌓은겁니다.
최초 GPT-1을 발표하게 됩니다. 사전학습된 모델에 TASK에 따라 추가적인학습으로 높은 성능을 얻었다는것을 알 수 있습니다.
AI모델같은경우는 먼저 만들고-> 설계 -> 돌려보고 -> 되면-> 검증 -> 가설 순으로 진행이 됩니다.

사전 훈련된 언어 모델의 이점
컴퓨팅 비용과 탄소 배출량이 줄고,
모델을 처음부터 훈련시키는 데 필요한 시간과 리소스를 절약 (파인튜닝(미세조정)가능)
다양한 분야의 태스크에 적용 가능
마스크드 언어 모델(Masked Language Model, MLM)
입력 텍스트의 단어 집합의 15%의 단어를 랜덤으로 마스킹(Masking)합니다.
마스킹이란 원래의 단어가 무엇이었는지 모르게 한다는 뜻.
그리고 인공 신경망에게 이렇게 마스킹 된 단어들을(Masked words) '예측'하도록 함.
문장 중간에 구멍을 뚫어놓고, 구멍에 들어갈 단어들을 예측하게 하는 식입니다.
예] '나는 [MASK]에 가서 그곳에서 빵과 [MASK]를 샀다'를 주고 [MASK]에 들어갈 단어를 맞추게 합니다.
버트(Bidirectional Encoder Representations from Transformers, BERT)

2018년에 구글이 공개한 사전 훈련된 모델.
BERT라는 이름은 세서미 스트리트라는 미국 인형극의 케릭터 이름이기도 한데, 앞서 소개한 임베딩 방법론인 ELMo와 마찬가지로 세서미 스트리트의 케릭터 이름을 따온 것이기도 합니다.
BERT는 2018년에 공개되어 등장과 동시에 수많은 NLP 태스크에서 최고 성능을 보여주면서 명실공히 NLP의 한 획을 그은 모델로 평가받고 있습니다.
▶ transformers 패키지
사전학습된 최첨단 모델들을 쉽게 다운로드하고 훈련시킬 수 있는 API와 도구를 제공
https://huggingface.co/docs/transformers
https://huggingface.co/docs/transformers/ko/index (한국어)
※ huggingface 란

https://huggingface.co/
Hugging Face는 자연어 처리(NLP), 컴퓨터 비전(CV), 음성 처리 등 다양한 머신 러닝 모델을 쉽게 사용하고 배포할 수 있도록 지원하는 오픈소스 플랫폼이자 커뮤니티입니다.
특히, 대규모 언어 모델(LLM) 및 전이 학습(Transfer Learning) 프레임워크를 중심으로 한 도구와 서비스를 제공합니다.
Hugging Face는 데이터 과학자, 연구자, 엔지니어들이 머신 러닝 모델을 쉽게 활용하고, 학습시키고, 배포할 수 있도록 도와주는 라이브러리와 클라우드 서비스를 제공합니다. 가장 유명한 라이브러리는 Transformers이며, 이는 NLP 및 다양한 AI 작업에 널리 사용됩니다.
설치는 하면됩니다.
코랩에는 이미 설치가 되어있습니다.
!pip install transformers1. BERT 개요
BERT는 트랜스포머를 이용하여 구현됨. 데이터는 위키디피아(25억 단어), BooksCORPUS(8억 단어)와 같은 레이블이 없는 텍스트 데이터로 '사전 훈련된 언어모델'
BERT의 성능이 높은 이유
'레이블이 없는 방대한데이터'로 '사전 훈련된'모델을 가지고., 레이블이 있는 다른작업(task)에서 '추가훈련'과 함께 하이퍼파라미터를 재조정하여 이 모델을 사용하면 성능이 높게 나오는 기존의 사례들을 참고했기때문입니다.
추가훈련과 함께 하이퍼파라미터를 재조정하여 사용하는것을 파인튜닝이라고 합니다.
파인 튜닝 Fine-tuning

다른 작업에 대해서 '파라미터 재조정'을 위한 '추가 훈련 과정'을 파인 튜닝(Fine-tuning, 미세조정)이라고 합니다
↑위의 그림은 BERT의 파인 튜닝 예시입니다
하고 싶은 태스크가 스팸 메일 분류라고 하였을 때,이미 위키피디아 등으로 '사전 학습된 BERT' 위에 '분류를 위한 신경망을 한 층 추가'합니다.
이 경우, 비유하자면 BERT가 언어 모델 사전 학습 과정에서 얻은 지식을 활용할 수 있으므로 스팸 메일 분류에서 보다 더 좋은 성능을 얻을 수 있습니다.
이전에 언급한 ELMo나 OpenAI GPT-1 등이 이러한 파인 튜닝 사례의 대표적인 예입니다.
*LLM은 거의 사전 훈련된 모델임
2. BERT의 크기(BERT-Base, BERT-Large)

BERT의 기본 구조는 트랜스포머의 인코더를 쌓아올린 구조.
-'Base 버전' 에서는 총 12개,
-'Large 버전'에서는 총 24개를 쌓았습니다.
Large 버전은 Base 버전보다
- d_model의 크기나 셀프 어텐션 헤드(Self Attention Heads)의 수가 더 큽니다.
트랜스포머 인코더 층의 수를 L, d_model의 크기를 D, 셀프 어텐션 헤드의 수를 A라고 하였을 때 각각의 크기는 다음과 같습니다.
-BERT-Base : L=12, D=768, A=12 : 110M개의 파라미터
-BERT-Large : L=24, D=1024, A=16 : 340M개의 파라미터
※ 아래 예제 에서는 편의를 위해 BERT-BASE를 기준으로 설명합니다.
3. BERT의 문맥을 반영한 임베딩(Contextual Embedding)
BERT는 문맥을 반영한 임베딩을 사합니다.

BERT의 입력
-임베딩 층(Embedding layer)를 지난 임베딩 벡터들
-d_model이 768
-768차원의 임베딩 벡터된 단어가 BERT의 입력
BERT의 출력
-내부 연산후 동일하게 각 단어에 대해서 768차원의 벡터 출력

[좌측 그림]에서
[CLS]라는 벡터는 BERT의 초기 입력으로 사용되었을 입력 임베딩 당시에는
단순히 임베딩 층(embedding layer)를 지난 임베딩 벡터였지만,
BERT를 지나고 나서는 [CLS], I, love, you라는 모든 단어 벡터들을 '모두 참고'한 후에 문맥 정보를 가진 벡터가 됩니다.
※ 모든 단어를 참고하고 있다는 것을 점선의 화살표로 표현하였습니다.
이는 [CLS]라는 단어 벡터 뿐만 아니라 다른 벡터들도 전부 마찬가지.
가령, 우측의 그림에서 출력 임베딩 단계의 love를 보면 BERT의 입력이었던
모든 단어들인 [CLS], I, love, you를 참고하고 있습니다.
하나의 단어가 모든 단어를 참고하는 연산은 BERT 의 '12개층'에서 전부 이루어지는 연산입니다.
그리고 이를 12개의 층을 지난 후에 최정적으로 출력 임베딩을 얻게되는것입니다.
↓ B ERT 첫번째 층

첫번째 층의 출력 임베딩은 ==> 두번째 층의 입력 임베딩이 됩니다.
BERT가 문맥을 반영한 출력 임베딩을 얻게 되는이유는 셀프어텐션때문인데요

BERT는 트랜스포머 인코더를 12번 쌓았습니다.
각 층마다 '멀티 헤드 셀프 어텐션'과 '포지션 와이즈 피드 포워드 신경망'을 수행합니다. (각 버트레이어마다 수행)
4. BERT의 서브워드 토크나이저 : WordPiece
BERT는 단어보다 더 작은 단위로 쪼개는 서브워드 토크나이저를 사용
BERT가 사용한 토크나이저는 WordPiece 토크나이저
서브워드 토크나이저 기본 아이디어
-자주 등장하는 단어는 그대로 단어 집합에 추가
-자주 등장하지 않는 단어의 경우에는 더 작은 단위인 '서브워드'로 분리되어 서브워드들이 단어 집합에 추가
이렇게 단어 집합이 만들어지고 나면, 이 단어 집합을 기반으로 토큰화를 수행
BERT 에서 토크화 수행 방식
준비물 : 이미 훈련 데이터로부터 만들어진 단어 집합
1.토큰이 단어 집합에 존재한다.
→ 해당 토큰을 분리하지 않는다.
2.토큰이 단어 집합에 존재하지 않는다.
→ 해당 토큰을 서브워드로 분리한다.
→ 해당 토큰의 첫번째 서브워드를 제외한 나머지 서브워드들은 앞에 "##"를 붙인 것을 토큰으로 한다.
3.[예시]
embeddings 단어가 입력으로 들어왔을때
BERT의 단어 집합에 해당 단어가 존재하지 않는다면
서브워드 토크나이저가 아니라면 OOV 문제 발생
서브워드 토크나이저의 경우 해당 단어를 더 쪼개려고 시도합니다
만약, BERT의 단어 집합에 em, ##bed, ##ding, #s (학습대상)라는 서브 워드들이 존재한다면
-> embeddings는 ==> em, ##bed, ##ding, ##s로 분리됩니다.
(단어 중간에 등장하는것은 저렇게 추가를 합니다.)
여기서 ## 은 이 서브워드들은 단어의 중간부터 등장하는 '서브워드'라는 것을 알려주기 위해 단어 집합 생성 시 표시해둔 기호입니다.
이런 표시가 있어야만 em, ##bed, ##ding, ##s를 다시 손쉽게 embeddings로 복원할 수 있을 것입니다.
조사, 어미 이런 부분이 굉장히 부드럽게 나왔는데 이 부분이 서브토크나이저를 사용해서 단어의 안에있는 서브텍스트를 분할해서 다시 합친것입니다.
품사에 대한 정보가 없는데도 이전 PREDICT에서 너무 잘 구현해왔습니다.
▶BertTokenizer
import pandas as pd
from transformers import BertTokenizer
공식링크 https://huggingface.co/transformers/v3.0.2/model_doc/bert.html#berttokenizer
BERT — transformers 3.0.2 documentation
ⓘ You are viewing legacy docs. Go to latest documentation instead. Docs » BERT View page source BERT Overview The BERT model was proposed in BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding by Jacob Devlin, Ming-Wei Chang
huggingface.co
Constructs a BERT tokenizer. Based on WordPiece.
허기에이스에 등장되어있는 모델을 로딩해서 토크나이저를 생성해보겠습니다.
주석은 해당 공식링크입니다.
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
# Instantiate a pretrained pytorch model from a pre-trained model configuration.
# https://huggingface.co/transformers/v3.0.2/main_classes/model.html#transformers.PreTrainedModel.from_pretrainedresult = tokenizer.tokenize('Here is the sentence I want embeddings for.')
print(result)['here', 'is', 'the', 'sentence', 'i', 'want', 'em', '##bed', '##ding', '##s', 'for', '.']
↑ 위에를 보면 embeddings라는 단어가 어떻게 토크나이저됐는지 확인가능합니다.
임베딩스라는 단어는 사전에 없었기때문에 서브워드 토크나이저를 하게됩니다.
약 3만 500개정도의 단어가있는것을 len을 찍어보면서 확인해볼 수 있고
특정단어를 보고싶다면 tokenizer.vocab['here'] 이렇게! 해보면됩니다.
print(tokenizer.vocab['em'])
print(tokenizer.vocab['##bed'])
print(tokenizer.vocab['##ding'])
print(tokenizer.vocab['##s'])이렇게 찍어보면 이 단어들이 다 토큰화가 되어있는지를 확인할 수 있는데
각각 7861, 8270, 4667, 2015로 정의가 되어있는것을 확인할 수 있습니다.
아까 토크나이즈 메서드를 통해서 위 단어들이 사전에 등록이 된것입니다.
# BERT 의 사전(단어 집합) 을 파일로 저장
with open('vocabulary.txt', 'w') as f:
for token in tokenizer.vocab.keys():
f.write(token + '\n')
df = pd.read_fwf('vocabulary.txt', header=None)
df를하게되면 data frame형태로 또 저장되게 됩니다.
참고] BERT에서 사용되는 특별 토큰들과 정숫값
[PAD] - 0 padding token
[UNK] - 100 unknown token
[CLS] - 101 classification token. 문장의 시작
[SEP] - 102 separator token. 문장의 끝 <sos>
[MASK] - 103 mask token (마스크언어모델 MLM 에서 사용) <eos>
▶ 포지션 임베딩(Positon Embedding)
트랜스포머에서는 sin, cos 함수를 사용하여 포지셔널 인코딩(Positional Encoding)이라는 방법을 통해 단어의 위치 정보를 표현했습니다. 포지셔널 인코딩은 사인 함수와 코사인 함수를 사용하여 위치에 따라 다른 값을 가지는 행렬을 만들어 이를 단어 벡터들과 더하는 방법입니다.
BERT 에선 학습을 통해서 얻는 포지션 임베딩(Position Embedding)이라는 방법을 사용하여 단어의 위치 정보를 표현함.
포지션 임베딩 (예시 그림) : 2개의 임베딩 층 사용
-단어의 임베딩 벡터
-포지션 임베딩 벡터

[위 그림 설명]
WordPiece Embedding은 우리가 이미 알고 있는 단어 임베딩으로 실질적인 '입력'입니다.
그리고 이 입력에 포지션 임베딩을 통해서 '위치 정보'를 더해주어야 합니다.
포지션 임베딩의 아이디어는 굉장히 간단한데, 위치 정보를 위한 임베딩 층(Embedding layer)을 하나 더 사용합니다.
가령, 문장의 길이가 4라면 4개의 포지션 임베딩 벡터를 학습시킵니다.
그리고 BERT의 입력마다 다음과 같이 포지션 임베딩 벡터를 더해주는 것입니다.
첫번째 단어의 임베딩 벡터 + 0번 포지션 임베딩 벡터
두번째 단어의 임베딩 벡터 + 1번 포지션 임베딩 벡터
세번째 단어의 임베딩 벡터 + 2번 포지션 임베딩 벡터
네번째 단어의 임베딩 벡터 + 3번 포지션 임베딩 벡터
실제 BERT에서는 문장의 최대 길이를 512로 하고 있으므로, 총 512개의 포지션 임베딩 벡터가 학습됩니다.
결론적으로 현재 설명한 내용을 기준으로는 BERT에서는 총 두 개의 임베딩 층이 사용됩니다.
단어 집합의 크기가 30,522개인 단어 벡터를 위한 임베딩 층과
문장의 최대 길이가 512이므로 512개의 포지션 벡터를 위한 임베딩 층입니다.
사실 BERT는 세그먼트 임베딩(Segment Embedding)이라는 1개의 임베딩 층을 더 사용합니다. 이에 대해서는 뒤에 언급합니다...
BERT의 사전훈련은 2가지 사전훈련방식이 있습니다.

1. BERT (Bidirectional Encoder Representations from Transformers)
-발표: 2018년 (Google)
-핵심 아이디어:
트랜스포머의 인코더 구조를 사용하며, 문장의 양방향 문맥을 동시에 학습.
두 가지 사전 학습 태스크를 사용:
Masked Language Model (MLM): 일부 단어를 가리고 이를 예측.
Next Sentence Prediction (NSP): 두 문장이 연결되는지 판단.
-특징:
양방향 문맥 표현으로 단어의 풍부한 의미를 학습.
다양한 NLP 태스크에서 state-of-the-art 성능 달성.
-장점:
ELMo보다 더 정교한 문맥 정보를 제공.
양방향 학습으로 문장 내의 더 깊은 관계를 파악 가능.
-한계:
사전 학습 비용이 매우 큼(대규모 데이터와 컴퓨팅 자원 필요).
2. GPT-1 (Generative Pre-trained Transformer 1)
-발표: 2018년 (OpenAI)
-핵심 아이디어:
트랜스포머 아키텍처를 사용하여 사전 학습(pre-training)과 미세 조정(fine-tuning) 개념을 도입했습니다.
언어 모델링(다음 단어 예측)을 통해 대규모 데이터에서 사전 학습을 수행한 후, 특정 태스크에 맞게 미세 조정.
-특징:
트랜스포머의 디코더 구조를 사용.
단방향 언어 모델(이전 토큰만 참조 가능).
-장점:
전이 학습(transfer learning)의 효과를 보여줌.
당시 기준으로 여러 NLP 태스크에서 높은 성능 달성.
-한계:
단방향 특성으로 인해 문맥을 완전히 활용하지 못함.
3. ELMo (Embeddings from Language Models)
-발표: 2018년 (AllenNLP 팀)
-핵심 아이디어:
ELMo는 단어의 의미를 문맥에 따라 동적으로 표현합니다. 이전에는 단어를 고정된 벡터(Word2Vec, GloVe 등)로 표현했지만, ELMo는 문맥에 따라 단어 임베딩이 달라지는 방식을 도입했습니다.
양방향 LSTM을 사용하여 문장의 양방향 정보를 활용합니다.
-장점:
"bank" 같은 단어의 다의성을 문맥을 통해 구별할 수 있음.
다양한 NLP 태스크(문장 분류, 개체명 인식 등)에 쉽게 적용 가능.
-한계:
LSTM 기반이라 대규모 데이터를 처리하는 데 시간이 오래 걸림.
비교요약을 하자면 아래 표처럼 나눌 수 있습니다.
| 모델 | 구조 | 방향성 | 주요특징 |
| BERT | 트랜스포머 인코더 | 양방향 | MLM,NSP 사용, 문맥 이해에 강점 |
| GPT-1 | 트랜스포머 디코더 | 단방향 | 전이학습 도입, 생성중심 |
| ELMo | LSTM | 양방향 | 문맥에 따른 동적 임배딩 |
BERT의 사전훈련 방법은 두가지로 나뉩니다.
첫번째는 마스크드 언어모델(MLM), 두번째는 다음 문장 예측(NSP)
1)마스크드 언어모델(Masked Language Model, MLM)
사전훈련을 위해서 인공 신경망의 입력으로 들어가는 입력 텍스트의 15%의 단어를 랜덤으로 마스킹합니다.
그리고 인공 신경망에게 이 가려진 단어들(Masked words)를 예측하도록 합니다.
예를 들어 '나는 [MASK]에 가서 그곳에서 빵과 [MASK]를 샀다'를 주고
슈퍼'와 '우유'를 맞추게 합니다.
더 정확히는 전부 [MASK]로 변경하지는 않고, 랜덤으로 선택된 15%의 단어들은
다시 다음과 같은 비율로 규칙이 적용됩니다.
80%의 단어들은 [MASK]로 변경한다.
Ex) The man went to the store → The man went to the [MASK]
10%의 단어들은 랜덤으로 단어가 변경된다.
Ex) The man went to the store → The man went to the dog
10%의 단어들은 동일하게 둔다.
Ex) The man went to the store → The man went to the store

전체 단어의 85%학습에 사용되지 않음
전체 단어의 15%만 학습에 사용됨
-12%는 [MASK]로 변경 후에 원래 단어를 예측
-1.5%는 랜덤으로 단어가 변경된 후에 원래 단어를 예측
-1.5%는 단어가 변경되지는 않았지만, BERT는 이 단어가 변경된 단어인지 원래 단어가 맞는지는 알 수 없슴.
이 경우에도 BERT는 원래 단어가 무엇인지를 예측하도록 합니다.
[예시]
문장 : 'My dog is cute. he likes playing'
전처리, BERT 의 서브워드 토크나이징 후 : ['my', 'dog', 'is' 'cute', 'he', 'likes', 'play', '##ing']이렇게 되겠죠?
위 토크화된 결과를 BERT 의 입력으로 사용
↓ 언어모델 학습을 위해 다음과 같이 데이터가 변경되었다고 가정
↓ 'dog' 토큰은 [MASK]로 변경
↓ BERT 모델이 원래 단어를 맞추려고 하는 모습 (소프트맥스에 의해)

오직 'dog' 위치의 출력층의 벡터만이 사용됨
다른 위치의 벡터들은 예측과 학습에 사용되지 않음
구체적으로는 BERT의 손실 함수에서 다른 위치에서의 예측은 무시
출력층에서는 예측을 위해 단어 집합의 크기만큼의 밀집층(Dense layer)에 소프트맥스 함수가 사용된 1개의 층을 사용하여 원래 단어가 무엇인지를 맞추게 됨
↓ 다음과 같이 데이터셋이 변경되었다면 어떨까?
'dog' 토큰은 [MASK]로 변경.
'he'는 랜덤 단어 'king'으로 변경.
'play'는 변경되진 않았지만 예측에 사용됨.
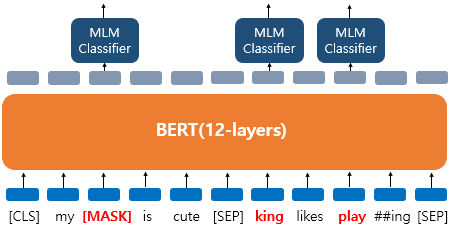
2) 다음문장 예측(Next Sentence Prdiction NSP)
BERT는 두개의 문장을 준 후에 이 문장이 이어지는 문장인지? 이어지지 않는 문장인지를 맞추는 방식으로 훈련됩니다.
입력은
실제 이어지는 두개의 문장 50%, 랜덤으로 이어붙인 두개의 문장 50%입니다.
LABEL은
이어지는 문장의 여부를 적습니다.
● 이어지는 문장의 경우
Sentence A : The man went to the store.
Sentence B : He bought a gallon of milk.
Label = IsNextSentence
● 이어지는 문장이 아닌 경우 경우
Sentence A : The man went to the store.
Sentence B : dogs are so cute.
Label = NotNextSentence

[SEP] 토큰 : BERT의 입력시 문장의 끝에 [SEP] 토큰을 사용하여 문장을 구분.
[CLS] 토큰 : 이 두 문장이 실제 '이어지는 문장인지 아닌지'를 [CLS] 토큰의 위치의 출력층에서 이진 분류 문제로 풀도록 합니다
'마스크드 언어 모델'과 '다음 문장 예측'은 따로 학습하는 것이 아닌 loss를 합하여 학습이 '동시에 이루어집니다'.
BERT가 NSP를 학습하는 이유
BERT 풀고자 하는 태스크 중에서는 QA(Question Answering)나 NLI(Natural Language Inference)와 같이 두 문장의 관계를 이해하는 것이 중요한 태스크들이 있기 때문.
7. 세그먼트 임베딩(Segment Embedding)

BERT는 QA 등과 같은 두 개의 문장 입력이 필요한 태스크를 풀기도 합니다
BERT가 '구분' 하는 '문장' 이라는 것은 [SEP] 토큰으로 구분되는 문장을 의미하는 것은 아닙니다. (다음에 설명)
Segment Embedding
'문장구분' 을 위해 BERT 에서 사용하는 또 다른 임베딩 층 (Embedding layer)
첫번째 문장에는 Sentence 0 임베딩, 두번째 문장에는 Sentence 1 임베딩을 더해주는 방식.
임베딩 벡터는 두 개만 사용됨
1.Segment A (혹은 Segment ID: 0)
첫번째 문장에 해당하는 토큰들
2. Segment B (혹은 Segment ID: 1)
두번째 문장에 해당하는 토큰들
결론적으로 BERT는 총 3개의 임베딩 층이 사용됩니다.
1.WordPiece Embedding : 실질적인 입력이 되는 워드 임베딩. 임베딩 벡터의 종류는 단어 집합의 크기로 30,522개.
2.Position Embedding : 위치 정보를 학습하기 위한 임베딩. 임베딩 벡터의 종류는 문장의 최대 길이인 512개.
3.Segment Embedding : 두 개의 문장을 구분하기 위한 임베딩. 임베딩 벡터의 종류는 문장의 최대 개수인 2개.
임베딩이라는 단어가 나오면 모두 학습대상이라는 의미입니다.
*주의! 위에서 말하는 BERT 의 입력문장이란?
단순히 [SEP] 토큰으로 나뉘는 문장의 의미가 아니다
ex) [Q,A] 두 종류의 텍스트로 입력 받아도
두 개의 문장은 실제로 두 종류의 텍스트, 두개의 문서 일수도 있다
BERT가 두 개의 문장을 입력받을 필요가 없는 경우도 있습니다.
예를 들어 네이버 영화 리뷰 분류나 IMDB 리뷰 분류와 같은 감성 분류 태스크에서는 한 개의 문서에 대해서만 분류를 하는 것이므로,
이 경우에는 BERT의 전체 입력에 Sentence 0 임베딩만을 더해줍니다.
BERT를 파인튜닝(Fine-tuning, 미세조정)
BERT의 Fine-tuning은 사전 학습된 BERT 모델을 특정 NLP 태스크(예: 문장 분류, 감정 분석, 질의응답 등)에 맞게 미세 조정하는 과정을 의미합니다. 이 과정은 사전 학습(pre-training)과 대조적으로, 특정 태스크의 데이터를 사용해 BERT 모델을 최적화하는 단계입니다. 아래에서 자세히 설명하겠습니다.
※ BERT Fine-tuning 에 대해
BERT Fine-tuning의 개념
1.사전 학습(Pre-training):
→ BERT는 대규모 비지도 데이터에서 Masked Language Model(MLM)과 Next Sentence Prediction(NSP) 태스크로 학습됩니다.
→ 이 과정에서 BERT는 언어의 일반적인 문맥과 구조를 이해하는 데 필요한 범용적인 표현(representation)을 학습합니다.
2.미세 조정(Fine-tuning):
→ 사전 학습된 모델을 기반으로, 특정 NLP 태스크(감정 분석, 문장 분류, 번역 등)에 맞게 추가 학습을 진행합니다.
→ 이때 모델은 태스크에 적합한 작은 크기의 데이터셋으로 조정되며, 태스크 전용 출력 레이어를 추가합니다.
Fine-tuning의 과정
태스크 데이터 준비:
→ 특정 태스크의 레이블이 포함된 데이터셋을 준비합니다.
예: 감정 분석 태스크라면 각 문장에 긍정/부정 레이블이 포함된 데이터셋.
→ 모델 구조 설정:
BERT 모델의 출력 위에 간단한 태스크 전용 헤드(head)를 추가합니다.
예: 문장 분류의 경우, [CLS] 토큰의 출력 위에 Softmax 분류기를 추가.
→ 태스크 데이터로 학습:
특정 태스크의 데이터를 사용해 BERT를 학습합니다.
이때 BERT의 모든 가중치(Transformer 층 포함)를 미세 조정하며, 사전 학습된 지식과 새로운 태스크 데이터를 결합합니다.
→ 최적화:
일반적으로 AdamW 옵티마이저와 Learning Rate Scheduler를 사용해 학습.
Fine-tuning 단계에서는 보통 낮은 학습률(learning rate)을 사용하여 사전 학습된 지식을 보존하면서 태스크에 맞게 조정.
Fine-tuning의 예시
→ 감정 분석(Sentiment Analysis):
입력: I love this movie!
과정:
1.문장은 BERT 입력 형식으로 변환 ([CLS] I love this movie! [SEP]).
2.[CLS] 토큰의 최종 출력(히든 상태)을 사용해 감정(긍정/부정)을 분류.
출력: 긍정(Positive).
→ 질의응답(Q&A):
입력:
1.질문: Who is the president of the United States?
2.문서: Joe Biden is the president of the United States.
과정:
1.BERT는 질문과 문서를 함께 입력받음([CLS] 질문 [SEP] 문서 [SEP]).
2.답변의 시작점과 끝점을 예측.
출력: Joe Biden.
Fine-tuning의 장점
작은 데이터셋으로 학습 가능:
BERT는 이미 사전 학습 단계에서 언어에 대한 풍부한 지식을 학습했기 때문에, 적은 양의 데이터로도 높은 성능을 달성할 수 있습니다.
다양한 태스크 적용:
문장 분류, 문장 관계 추론, 질의응답, 번역 등 다양한 태스크에 적용 가능.
사전 학습의 범용성 활용:
범용적인 언어 표현을 특정 문제에 적합하게 미세 조정하여 높은 효율을 보임.
Fine-tuning과 Feature Extraction의 차이
Fine-tuning:
사전 학습된 모델의 모든 가중치를 특정 태스크에 맞게 조정.
모델 전체를 학습 데이터에 적합하게 업데이트.
Feature Extraction:
사전 학습된 모델의 출력(예: BERT의 마지막 히든 레이어)을 고정된 특징으로 사용하고, 추가적인 모델(예: SVM, MLP)을 학습.
Fine-tuning은 대부분의 경우 더 높은 성능을 발휘하지만, 학습 시간이 오래 걸릴 수 있습니다.
BERT Fine-tuning은 NLP 태스크를 해결하는 데 매우 강력하며, 이를 통해 특정 문제에 대해 사전 학습된 언어 지식을 효과적으로 활용할 수 있습니다.
1) 하나의 텍스트에 대한 텍스트 분류 유형(Single Text Classification)
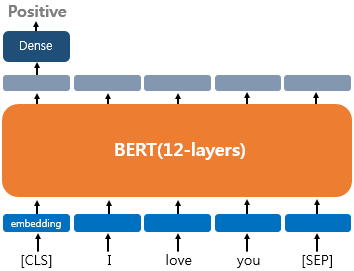
영화 리뷰 감성 분류, 로이터 뉴스 분류 등과 같이 입력된 문서에 대해서 '분류'를 하는 유형
문서의 시작에 [CLS] 라는 토큰을 입력
[CLS] 토큰은 BERT가 분류 문제를 풀기위한 특별한 토큰! → 이는 BERT를 실질적으로 사용하는 단계인 파인 튜닝 단계에서도 마찬가지입니다.
텍스트 분류 문제를 풀기 위해서 [CLS] 토큰의 위치의 출력층에서 밀집층(Dense layer), (aka. 완전 연결층(fully-connected layer))을 추가하여 분류에 대한 예측을 하게됩니다
2) 하나의 텍스트에 대한 태깅작업(Taggign)
태깅작업 예)
각 단어에 품사를 태깅하는 품사태깅, 개체를 태깅하는 '개체명 인식작업(NER:Named Entity Recognition)' <- 이부분도 자연어에서 많이 하는 작업입니다
3) 텍스트 쌍에 대한 분류 또는 회귀문제(Text Pair Classification or Regression)

텍스트의 쌍(Text Pair)을 입력받는 태스크입니다.
대표적인 예 : 자연어 추론 (NLI. Natural language inference)
두 문장이 주어졌을 때 하나의 문장이 다른 문장과 논리적으로 어떤 관계에 있는지를 분류하는 것
분류유형은 1. 모순관계(contradiction) 2.함의 관계(entailment) 3.중립관계(neutral)가 있습니다.
4) 질의 응답(Question Answering)
QA(Question Answering) 태스크
'질문' 과 '본문' 두개의 텍스트의 쌍을 입력
[예시]
'질문' : "강우가 떨어지도록 영향을 주는 것은?"
'본문' : "기상학에서 강우는 대기 수증기가 응결되어 중력의 영향을 받고 떨어지는 것을 의미합니다. 강우의 주요 형태는 이슬비, 비, 진눈깨비, 눈, 싸락눈 및 우박이 있습니다."
'정답' : '중력'
9. 그 외 기타
훈련 데이터는 위키피디아(25억 단어)와 BooksCorpus(8억 단어) ≈ 33억 단어
WordPiece 토크나이저로 토큰화를 수행 후 15% 비율에 대해서 마스크드 언어 모델 학습
두 문장 Sentence A와 B의 합한 길이. 즉, 최대 입력의 길이는 512로 제한
100만 step 훈련 ≈ (총 합 33억 단어 코퍼스에 대해 40 에포크 학습)
옵티마이저 : 아담(Adam)
학습률(learning rate) : 10−4
가중치 감소(Weight Decay) : L2 정규화로 0.01 적용
드롭 아웃 : 모든 레이어에 대해서 0.1 적용
활성화 함수 : relu 함수가 아닌 gelu 함수
배치 크기(Batch size) : 256
10. 어텐션 마스크(Attention Mask)

BERT를 실제로 실습하게 되면 어텐션 마스크 라는 시퀀스 입력이 추가로 필요
BERT가 어텐션 연산을 할 때, 불필요하게 패딩 토큰에 대해서 어텐션을 하지 않도록 실제 단어와 패딩 토큰을 구분할 수 있도록 알려주는 입력
0, 1 두가지 값을 가짐
1 은 해당 토큰은 실제 단어이므로 마스킹을 하지 않는다라는 의미
0 은 해당 토큰은 패딩 토큰이므로 마스킹을 한다는 의미
[참고] transformer 계열의 사전훈련모델 들
Transformer 계열의 사전훈련 모델들은 자연어 처리(NLP) 및 기타 작업에서 다양한 목적으로 설계된 모델들로, 대표적인 것들은 다음과 같습니다:
1. BERT 계열 (Bidirectional Encoder Representations from Transformers)
- BERT (2018, Google)
양방향으로 문맥을 이해하는 Transformer Encoder 기반의 모델로, Masked Language Model(MLM)과 Next Sentence Prediction(NSP) 방식으로 학습.- 예: BERT-base, BERT-large
- 활용: 텍스트 분류, 질의응답, 문장 관계 판단
- RoBERTa (2019, Facebook)
BERT의 변형으로, NSP를 제거하고 더 많은 데이터와 긴 학습시간으로 성능 향상.- 예: RoBERTa-base, RoBERTa-large
- ALBERT (2019, Google)
파라미터를 감소시키는 기법(예: Factorized Embedding Parameterization)을 적용해 더 효율적.- 활용: 효율적인 파라미터 사용, NLP 태스크
- DistilBERT (2019, Hugging Face)
BERT를 경량화한 모델로, 계산 비용이 적으면서도 성능 유지.- 활용: 실시간 시스템
2. GPT 계열 (Generative Pre-trained Transformers)
- GPT (2018, OpenAI)
순방향 언어 생성을 목표로 하는 Transformer Decoder 기반의 모델.- GPT, GPT-2, GPT-3, GPT-4 등이 점진적으로 발전.
- 활용: 텍스트 생성, 요약, 번역, 대화형 AI
- ChatGPT (OpenAI)
GPT-3.5, GPT-4를 기반으로 한 대화 모델.- 활용: 대화형 AI, 고객지원, 콘텐츠 생성
- CodeX (OpenAI)
코딩 특화 GPT 모델로, 코드 생성과 디버깅에 활용.
3. T5 계열 (Text-to-Text Transfer Transformer)
- T5 (2019, Google)
모든 NLP 태스크를 텍스트-텍스트 변환 문제로 통합.- 예: T5-small, T5-base, T5-large
- 활용: 번역, 문장 요약, 질의응답
- mT5 (2021, Google)
다국어에 특화된 T5 모델. - Flan-T5 (Google)
지식 학습을 추가해 정밀도를 높인 버전.
4. XLNet 계열
- XLNet (2019, Google/CMU)
BERT와 GPT의 장점을 결합한 모델로, Auto-Regressive 모델과 Auto-Encoding 모델의 혼합.- 활용: 문맥 이해 및 생성 태스크
5. ELECTRA 계열
- ELECTRA (2020, Google)
"Generator-Discriminator" 방식을 사용해 Masked Token 복원 대신, "진짜 또는 가짜" 토큰 판단.- 활용: 효율적인 사전학습
6. 다국어 및 대규모 모델
- mBERT (Multilingual BERT)
다국어 처리를 위해 설계된 BERT. - XLM-R (2020, Facebook)
RoBERTa를 기반으로 다국어 처리에 최적화. - LLaMA (2023, Meta)
연구 중심의 경량화 대규모 모델.
7. Vision-Language 및 기타 특화 모델
- BART (2019, Facebook)
Seq2Seq 기반으로 문장 생성 및 요약에 강점. - DALL-E (OpenAI)
텍스트-이미지 생성 모델. - CLIP (OpenAI)
텍스트와 이미지를 함께 학습하여 멀티모달 작업 수행. - ViT (Vision Transformer, Google)
Transformer를 컴퓨터 비전에 적용.
위의 모델들은 특정 태스크나 사용 사례에 따라 다양하게 변형되고 응용됩니다.
[참고] 사전훈련모델과 LLM 의 차이점은?
사전훈련 모델(Pretrained Model)과 대규모 언어 모델(LLM, Large Language Model)은 밀접하게 관련이 있지만, 약간의 차이가 있습니다. 이를 구분하려면 두 개념의 정의와 목적을 이해해야 합니다.
1. 사전훈련 모델 (Pretrained Model)
정의
- 사전훈련 모델은 대규모 데이터셋을 기반으로 일반적인 언어 패턴을 학습한 모델을 말합니다. 특정 태스크(예: 감정 분석, 번역 등)에 적용되기 전에 미리 학습(pre-training)된 모델입니다.
- 모델 크기와 관계없이, 사전훈련된 후 특정 작업(fine-tuning)이나 전이 학습(transfer learning)을 통해 최적화됩니다.
주요 특징
- 목적: 언어의 기본적인 구조와 의미를 학습.
- 학습 방식: 일반적으로 다음과 같은 방식으로 학습:
- Masked Language Modeling (MLM): BERT 계열
- Causal Language Modeling (CLM): GPT 계열
- Denoising Autoencoders: BART 등
- 크기: 작은 모델(BERT-base)부터 중간 크기(T5-large)까지 다양.
- 사용 사례: 특정 NLP 태스크에 특화된 모델로 발전.
- 예: 감정 분석, 질의응답, 텍스트 요약, 번역 등.
예시
- BERT, RoBERTa, T5, GPT-2 등
- BERT는 기본적으로 사전훈련 모델로 설계되어 특정 태스크에 맞춰 세밀한 조정(fine-tuning)을 거칩니다.
2. 대규모 언어 모델 (LLM, Large Language Model)
정의
- 대규모 언어 모델(LLM)은 사전훈련 모델의 한 유형이지만, 매우 큰 규모(파라미터 수와 데이터 크기 기준)로 설계되어 강력한 언어 이해 및 생성 능력을 제공합니다.
- LLM은 범용적이고, 사전학습 이후 추가적인 세밀한 조정을 거치지 않아도 다양한 태스크를 수행할 수 있습니다(Zero-shot 또는 Few-shot Learning).
주요 특징
- 목적:
- 다양한 언어 태스크를 범용적으로 해결.
- 특정 태스크 없이도(Zero-shot) 인간 수준의 언어 이해 및 생성을 목표로 함.
- 학습 방식: 대규모 텍스트 데이터를 기반으로 CLM 또는 변형된 방법 사용.
- 크기: 수십억~수조 개의 파라미터.
- 예: GPT-3 (175억 파라미터), GPT-4, PaLM-2, LLaMA
- 추가 기능:
- 다중 태스크 수행 능력.
- Zero-shot, Few-shot 학습.
- 대화형 AI(예: ChatGPT).
예시
- GPT-3, GPT-4, PaLM, Claude, LLaMA 등
- ChatGPT는 GPT-3.5 또는 GPT-4를 기반으로 추가 미세 조정을 거친 LLM의 사례입니다.
차이점 비교
구분사전훈련 모델대규모 언어 모델 (LLM)| 규모 | 크기 제한적 (수백~수십억 파라미터) | 매우 크다 (수십억~수조 파라미터) |
| 목적 | 특정 NLP 태스크에 전이학습 사용 | 범용적인 언어 이해와 생성 |
| 학습 데이터 | 일반적인 언어 데이터셋 | 대규모 데이터셋 (웹, 책, 논문 등) |
| 사용 방식 | 주로 Fine-tuning 필요 | Zero-shot, Few-shot 수행 가능 |
| 대표 모델 | BERT, RoBERTa, T5 | GPT-3, GPT-4, Claude, LLaMA |
결론
- 모든 LLM은 사전훈련된 모델입니다.
그러나 모든 사전훈련 모델이 LLM은 아닙니다.- LLM은 사전훈련 모델 중에서도 매우 큰 규모와 범용성을 갖춘 모델을 의미합니다.
- 사전훈련 모델은 크기나 사용 목적에 따라 범용적이지 않을 수 있습니다.
따라서, 사전훈련 모델은 LLM의 상위 개념이며, LLM은 사전훈련 모델의 고도화된 형태라고 볼 수 있습니다.
'AI > 자연어처리' 카테고리의 다른 글
| 한국어 BERT 를 이용한 네이버 영화 리뷰 분류 (36) (0) | 2025.01.08 |
|---|---|
| BERT 의 MLM, NSP (35) (0) | 2025.01.07 |
| Transformer (33-4 한국어 챗봇 구현하기) (1) | 2025.01.03 |
| Transformer (33-3) (1) | 2025.01.02 |
| Transformer (33-1) (3) | 2025.01.01 |



