■ padiing(패딩)
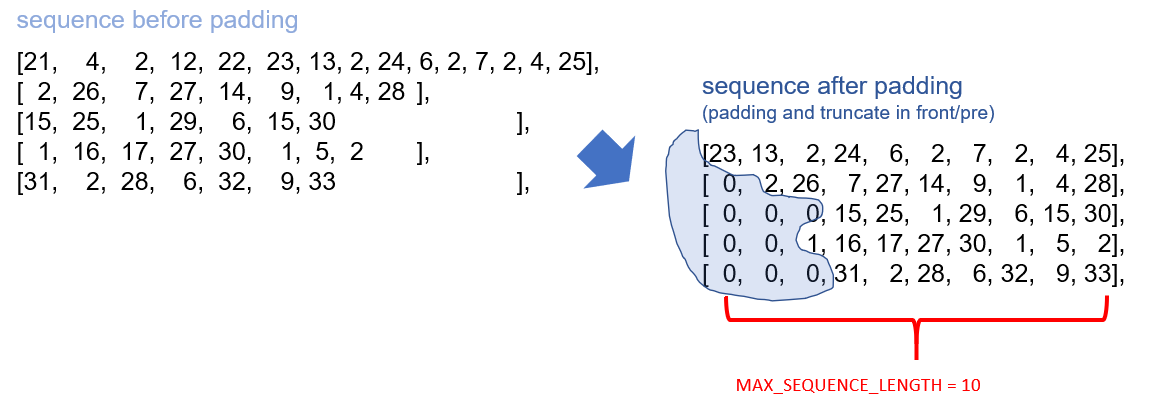
문자마다 인코딩된길이가 다르고, 우리는 입력데이터에 대한 쉐이프를 정해놓기때문에 그 모양을 맞추어야합니다.
그래서 비워있는 부분들을 다른 숫자로 채워넣는데 그 과정을 padding이라고 합니다.
왼쪽은 패딩이 뒤쪽, 오른쪽은 앞쪽! 즉! 앞쪽 뒤쪽 모두 다 붙이기 가능하다는점 기억해야합니다~
그러면 케라스로 패딩하는것을 한번 해봤는데
preprocessed_sentences를 하게되면 지난번에 했던 변수를 가져오게 됩니다.

이런식으로 구성이 되어있고 케라스 그리고 pad_sequences는 앞으로도 많이 사용될 예정이기에
꼭 숙지해둬야한다고 했습니다.
# 파라미터
https://www.tensorflow.org/api_docs/python/tf/keras/utils/pad_sequences
```python
tf.keras.utils.pad_sequences(
sequences,
maxlen=None,
dtype='int32',
padding='pre',
truncating='pre',
value=0.0
)
```encoded = tokenizer.texts_to_sequences(preprocessed_sentences)
encoded이렇게 하게되면 각 문장이 단어 인덱스의 리스트로 변환이 되어서 encoded 변수에 저장됩니다!
이미 preprocessed_sentences는 위에서 단어로 리스트를 만들었고
텍스트보다는 숫자 데이터를 처리하는것이 훨씬 효율적이기때문에 텍스트데이터를 인덱스로 변환하는것까지 알아두면 좋을것같습니다!
padded = pad_sequences(encoded)
padded

이렇게 되면 encoded는 기본적으로 encoded는 pre로 설정되어있어서 앞에 0으로 패딩이 되고 있습니다.
여기서 알아야되는건 위에서 padding= pre | 'post'가 있는데 말 그대로 pre는 문장의 앞에 패딩값 0으로 채우는것이고
post는 뒤에 패딩값을 채웁니다.
padded = pad_sequences(encoded, padding='post')
padded
padding='post'를 넣게되면 이렇게 뒤쪽으로 패딩이 맞춰지는것을 확인할 수 있습니다.
근데 뭘 기준으로 길이를 맞추냐?
가장 긴 시퀀스에 맞춰서 7개로 맞춰집니다. (그렇지만 항상 제일 긴 시퀀스에 맞추는것은 아님!!!!)
# maxlen= 값으로 패딩처리된 문장 시퀀스의 길이를 동일하게 합니다.
padded = pad_sequences(encoded, padding='post', maxlen=5)
padded그래서 maxlen=5로하면 5개로 맞춰지게됩니다.

위에는 7이지만 밑은 5개로 맞춰진 부분을 볼 수 있습니다!
근데 여기서 보면 padded를 바로 위에서 했던건 padding='post'로 했기떄문에 maxlen을 했을때 뒤부터 잘리는것을 볼 수 있습니다.
이것도 옵션을 줄 수 있는데
# truncating='pre' (기본값) 데이터 손실 발생시 '앞' 의 단어가 삭제
# truncating='post' 데이터 손실 발생시 '뒤' 의 단어가 삭제
padded = pad_sequences(encoded, padding='post', maxlen=5, truncating='post')
padded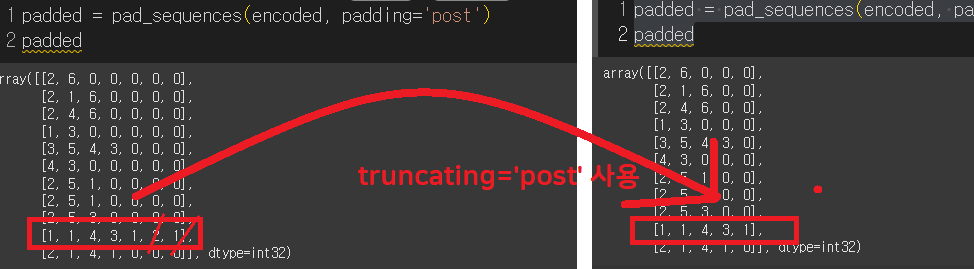
으로 turncating='post'로 사용하면 뒤쪽이 잘려나가는것을 볼 수 있습니다.
또한 패딩값은 일반적으로 위와같이 0을 사용하긴하는데 다른 숫자로도 패딩할 수 있습니다
물론 0을 하는것이 가장 가성비가 좋지만 그렇지 않은 경우도 있다는거죠~
예를들어서 단어집합의 크기에 +1 한 숫자를 패딩문자로 사용한다면 아래처럼 됩니다.
last_value = len(tokenizer.word_index) + 1
print(last_value)
#값 15토큰 워드 인덱스(14)보다 +1인 숫자의 개수로 패딩값을 프린트해보면 15입니다.
그 말은 즉 패딩을 15로 맞추기로 한거고 결과값을 보면
# value= 패딩값 지정
padded = pad_sequences(encoded, padding='post', value=last_value)
padded
짠 이렇게 15로 됩니다~
여기서도 value파라미터를 변경하면 됩니다 기본적으로는 0.0으로 지정되어있음!!
■ One-Hot-Encoding
'서로 다른 단어들의 집합'
book, books 이러한 변형형태도 '다른' 단어로 인식함!
자연어 처리에서 단어집합 작성 필요
이 단어집합을 가지고
1. 문자를 -> 숫자로 (벡터로) 변형
2. One-hot encoding 은 벡터로 변형된 형태중 하나입니다.
단어집합 만들기 위해선 고유한 정수 부여 (정수 인코딩)해야함!
keras를 이용해서 한 번 해보겠습니다 사용하는 함수는! to_categorical()
from keras.utils import to_categoricalhttps://www.tensorflow.org/api_docs/python/tf/keras/utils/to_categorical
```python
tf.keras.utils.to_categorical(
x, num_classes=None
)
```
text = "나랑 점심 먹으러 갈래 점심 메뉴는 햄버거 갈래 갈래 햄버거 최고야"
sub_text = "점심 먹으러 갈래 메뉴는 햄버거 최고야"
tokenizer = Tokenizer()
tokenizer.fit_on_texts([text])
print('단어집합:', tokenizer.word_index)
단어집합: {'갈래': 1, '점심': 2, '햄버거': 3, '나랑': 4, '먹으러': 5, '메뉴는': 6, '최고야': 7}이렇게 단어집합이 되게 됩니다.
sub_text = "점심 먹으러 갈래 메뉴는 햄버거 최고야"이제 texts_To_sequences([sub_text])[0]을 이용해서 인코딩을 해보려고 합니다.
encoded = tokenizer.texts_to_sequences([sub_text])[0]
encoded
결과값 : [2, 5, 1, 6, 3, 7]이렇게 됩니다! 이 값을 정수 인코딩된 결과로 원핫인코딩을 해보자면
ont_hot = to_categorical(encoded)
print(ont_hot)
결과괎
[[0. 0. 1. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 1. 0. 0.]
[0. 1. 0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 1. 0.]
[0. 0. 0. 1. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0. 0. 1.]]# [[0. 0. 1. 0. 0. 0. 0. 0.] # 인덱스 2의 원-핫 벡터
# [0. 0. 0. 0. 0. 1. 0. 0.] # 인덱스 5의 원-핫 벡터
# [0. 1. 0. 0. 0. 0. 0. 0.] # 인덱스 1의 원-핫 벡터
# [0. 0. 0. 0. 0. 0. 1. 0.] # 인덱스 6의 원-핫 벡터
# [0. 0. 0. 1. 0. 0. 0. 0.] # 인덱스 3의 원-핫 벡터
# [0. 0. 0. 0. 0. 0. 0. 1.]] # 인덱스 7의 원-핫 벡터
원핫인코딩의 단점, 한계
일단 0과 1로 맞는부분만 찾다보니 당연히 ML에서 다뤘던 문제와 동일하게 저장공간의 문제가 있고
단어유사도도 표현하지 못하는 단점이 있습니다.
단어의 유사성을 알 수 있다면 예를들어서 강남 라멘 맛집 검색을 하게되면 '맛집'과 유사한 결과들을 낼 수 있습니다!
그러니까
단어의 유사도 문제 해결하기 위해서는 -> 단어를 다차원 공간에 벡터화 기법 두가지가 있음
1. 카운트 기반의 벡터화 : ex) LSA(잠재 의미 분석), HAL
2. 예측 기반으로 벡터화 : NNLM, RNNLM, Word2Vec, FastText
카운트 기반과 예측 기반 두 가지 방법을 모두 사용 : ex) GloVe
즉 카운트는 통계적으로 단어의 관계를 잡아내고 예측기반은 신경망을 통해 문맥에서의 의미를 학습합니다.
지금은 Word2Vec을 좀 더 이어서 학습할 예정입니다.
'자연어(LLM)' 카테고리의 다른 글
| [AI활용 자연어처리 챗봇프로젝트] Word2Vec, 단어유사도 확인 / 완료 (6) | 2024.12.11 |
|---|---|
| 순환신경망을 이용한 IMDB 리뷰 분류해보기(28) (3) | 2024.12.10 |
| [AI활용 자연어처리 챗봇프로젝트] OOV란? oov인덱스 번호는? (0) | 2024.12.06 |
| [AI활용 자연어처리 챗봇프로젝트] 케라스를 이용한 전처리 (1) | 2024.12.05 |
| [AI활용 자연어처리 챗봇프로젝트] 정제 · 정규화 (1) | 2024.12.04 |



