| LSTM | GRU | bi-LSTM |
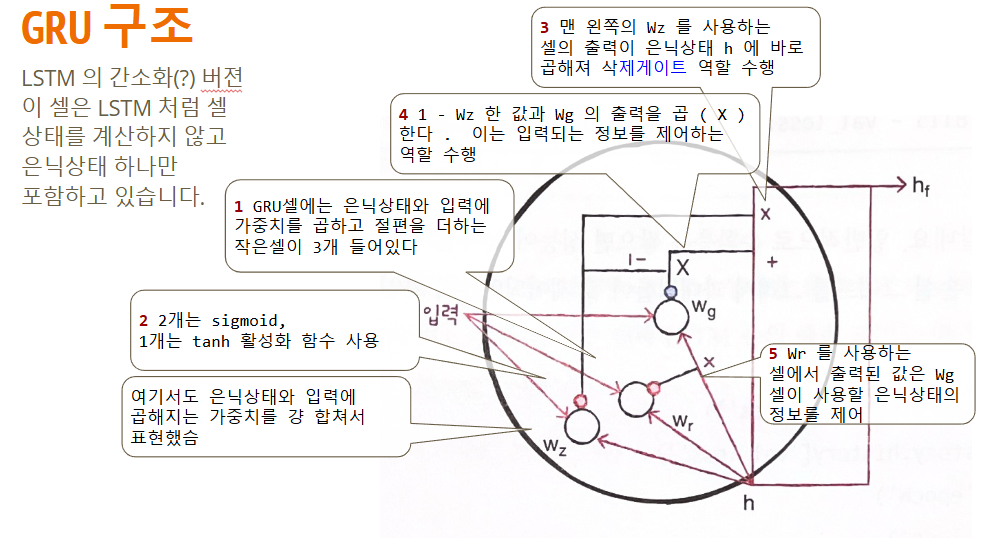
이번엔 LSTM보다 좀 더 가벼운 GRU모델에 대해서 학습해보겠습니다.
LSTM을 좀 더 간소화 한 버전이라고 볼 수 있습니다.
LSTM 보다 가중치가 적어서 '계산량'이 적지만, LSTM 못지 않은 좋은 성능을 내는것으로 알려져 있습니다.
텐서플로의 기본적으로 구현된 GRU는 GRU 초기 버전입니다
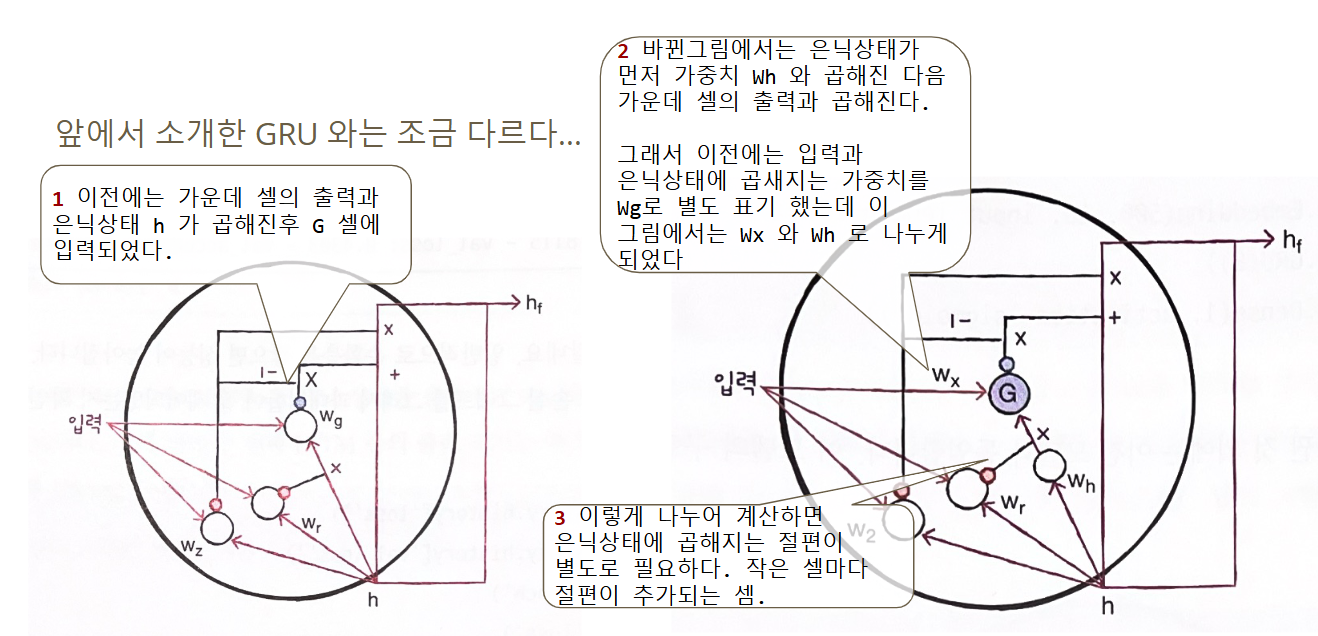
'이론' vs. '구현'
TF 가 이와 같은 계산 방식을 사용하는 이유는 GPU를 좀더 잘 활용하기 위함.
그러나, 대부분 GRU셀을 소개할때는 전자의 그림을 사용합니다
널리 통용되는 '이론'과 실질적인 '구현' 에는 차이 나는 경우가 종종 있습니다.
이로 인해 GRU 층의 모델 파라미터 개수를 혼동하진 맙시다
GRU 신경망
# ■ GRU 신경망
Gated Recurrent Unit
https://www.tensorflow.org/api_docs/python/tf/keras/layers/GRU
```python
tf.keras.layers.GRU(
units,
activation='tanh',
recurrent_activation='sigmoid',
use_bias=True,
kernel_initializer='glorot_uniform',
recurrent_initializer='orthogonal',
bias_initializer='zeros',
kernel_regularizer=None,
recurrent_regularizer=None,
bias_regularizer=None,
activity_regularizer=None,
kernel_constraint=None,
recurrent_constraint=None,
bias_constraint=None,
dropout=0.0,
recurrent_dropout=0.0,
seed=None,
return_sequences=False,
return_state=False,
go_backwards=False,
stateful=False,
unroll=False,
reset_after=True,
use_cudnn='auto',
**kwargs
)
```
모델 만들기
model = keras.Sequential()
model.add(keras.layers.Input(shape=(max_len,))) # (100, )
model.add(keras.layers.Embedding(500, 16))
model.add(keras.layers.GRU(units=8))
model.add(keras.layers.Dense(units=1, activation='sigmoid'))
model.summary()
층은 1개만 남겨두고 layers.GRU를 넣게됩니다
"""
Model: "sequential_3"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━┓
┃ Layer (type) ┃ Output Shape ┃ Param # ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━┩
│ embedding_3 (Embedding) │ (None, 100, 16) │ 8,000 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ gru (GRU) │ (None, 8) │ 624 │
# parameter 개수
# GRU 셀에는 3개의 작은셀이 있다
# 작은 셀에는 입력과 은닉상태(h) 를 곱하는 weigths 와 bias 가 있다.
# '입력' 곱하는 weight 는 16 x 8 = 128개
# '은닉상태' 에 곲하는 weight 는 8 x 8 = 64개
# 'bias' 가 뉴런마다 하나씩 있으므로 8개
# 모두 더하면 128 + 64 + 8 = 200개
# 이런 작은셀이 3개 x 200개 => 600개
# TF GRU 는 내부적으로 작은 셀마다 하나의 bias 가 추가된다.
# 작은셀 3개 x 8개 units = 24개
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ dense_3 (Dense) │ (None, 1) │ 9 │
└──────────────────────────────────────┴─────────────────────────────┴─────────────────┘
Total params: 8,633 (33.72 KB)
Trainable params: 8,633 (33.72 KB)
Non-trainable params: 0 (0.00 B)
"""
None
훈련코드는 역시 위에서 했던거 그대로 가져오고 이름만 GRU로 바꾸겠습니다.
rmsprop = keras.optimizers.RMSprop(learning_rate=1e-4)
model.compile(optimizer=rmsprop, loss='binary_crossentropy', metrics=['accuracy'])
checkpoint_cb = keras.callbacks.ModelCheckpoint(
'best-gru-model.keras',
save_best_only=True,
)
early_stopping_cb = keras.callbacks.EarlyStopping(patience=3,
restore_best_weights=True)
history = model.fit(train_seq, train_target, epochs=100, batch_size=64,
validation_data=(val_seq, val_target),
callbacks=[checkpoint_cb, early_stopping_cb])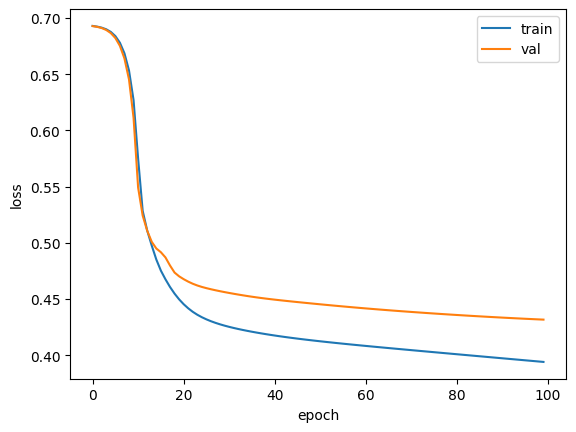
test_seq = pad_sequences(test_input, maxlen=max_len)
rnn_model = keras.models.load_model('best-gru-model.keras')
rnn_model.evaluate(test_seq, test_target)
782/782 ━━━━━━━━━━━━━━━━━━━━ 5s 5ms/step - accuracy: 0.8039 - loss: 0.4297
[0.4291016459465027, 0.8022000193595886]
위와같은 결과를 확인할 수 있습니다!
GRU 모델~ 끝!
'AI > 자연어처리' 카테고리의 다른 글
| [AI활용 자연어처리 챗봇프로젝트] 인코더 디코더 Seq2Seq (0) | 2024.12.30 |
|---|---|
| [AI활용 자연어처리 챗봇프로젝트] bi-LSTM, bi-LSTM 실습 (2) | 2024.12.23 |
| [AI활용 자연어처리 챗봇프로젝트] LSTM 실습 (1) | 2024.12.19 |
| [AI활용 자연어처리 챗봇프로젝트] LSTM이란? (1) | 2024.12.17 |
| [AI활용 자연어처리 챗봇프로젝트] 순차데이터, 순환데이터 (1) | 2024.12.13 |



