둘다 포즈쪽에서는 꽤 높은 정확도를 보이는 점에서 어떤 모델이 더 효율적인지 비교해보는것으로 마무리하려고 한다.
▶ 욜로포즈로 낙상감지했던 코드를 기반으로 미디어파이프 포즈로 낙상감지 시도
import cv2
import numpy as np
import mediapipe as mp
# MediaPipe Pose 모델 로드
mp_pose = mp.solutions.pose
pose = mp_pose.Pose()
# 동영상 경로 설정
input_video = '/content/00015_H_A_SY_C5.mp4' # 낙상 동영상
# input_video = '/content/00005_H_A_N_C5.mp4' # 비낙상 동영상
output_video = '/content/output_mp_pose.mp4'
# 동영상 읽기 및 저장 설정
cap = cv2.VideoCapture(input_video)
out = cv2.VideoWriter(
output_video,
cv2.VideoWriter_fourcc(*'mp4v'),
int(cap.get(cv2.CAP_PROP_FPS)),
(int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)), int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)))
)
# 변수 초기화
prev_centers = {} # 이전 프레임 중심 좌표 저장
danger_frame_count = 0 # 위험 상태 프레임수 저장
frame_idx = 0
# 속도 임계값 설정
danger_speed_threshold = 0.02 # 낙상위험 속도 임계값
move_speed_threshold = 0.018 # 낙상->정상 속도 임계값
danger_frame_threshold = 3 # 낙상 판단 프레임 수 (FPS 기준)
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
# MediaPipe Pose 추적 수행
results = pose.process(frame)
if results.pose_landmarks:
landmarks = results.pose_landmarks.landmark
# 중심 좌표 계산 / 왼쪽 어깨[11], 오른쪽 어깨[12] (정규화)
center_x = (landmarks[12].x + landmarks[11].x) / 2
center_y = (landmarks[12].y + landmarks[11].y) / 2
# 속도 계산 (이전 중심 좌표와 비교)
if prev_centers:
prev_x, prev_y = prev_centers
speed = np.sqrt((center_x - prev_x)**2 + (center_y - prev_y)**2)
else:
speed = 0 # 첫 프레임에서는 속도를 0으로 설정
# 위험 상태가 일정 시간 지속되면 낙상 처리
if danger_frame_count < danger_frame_threshold:
# 상태 판별
if speed <= danger_speed_threshold:
state = "Normal" # 정상
color = (0, 255, 0) # 초록
elif speed > danger_speed_threshold:
state = "Danger" # 위험
color = (255, 0, 0) # 파란색
danger_frame_count += 1 # 위험 상태 프레임 카운트
elif danger_frame_count >= danger_frame_threshold:
if speed < move_speed_threshold:
state = "Fall" # 낙상
color = (0, 0, 255) # 빨간색
elif speed >= move_speed_threshold:
danger_frame_count = 0
# 상태 텍스트 그리기
cv2.putText(frame, f"{state}", (0,0), cv2.FONT_HERSHEY_SIMPLEX, 0.5, color, 2)
cv2.circle(frame, (int(center_x * (frame.shape[1])), int(center_y * (frame.shape[0]))), 10, color, -1)
# 현재 중심 좌표 저장
prev_centers = center_x, center_y
# 결과를 출력 동영상에 저장
out.write(frame)
frame_idx += 1
cap.release()
out.release()
print(f"처리가 완료되었습니다! 결과 파일: {output_video}")
print(f"danger_frame_threshold: {danger_frame_count}")
* yolo-pose모델을 돌렸던 코드를 일부 수정하여 미디어파이프 포즈를 실행해주었다.
* 이때 미디어파이프 모델은 좌표를 기본적으로 정규화된 값을 가져온다고 하여 기존 좌표를 이용하였다.
* 그런데 위험은 감지가 됐는데 '낙상'의 감지상태가 잡히지 않았다.
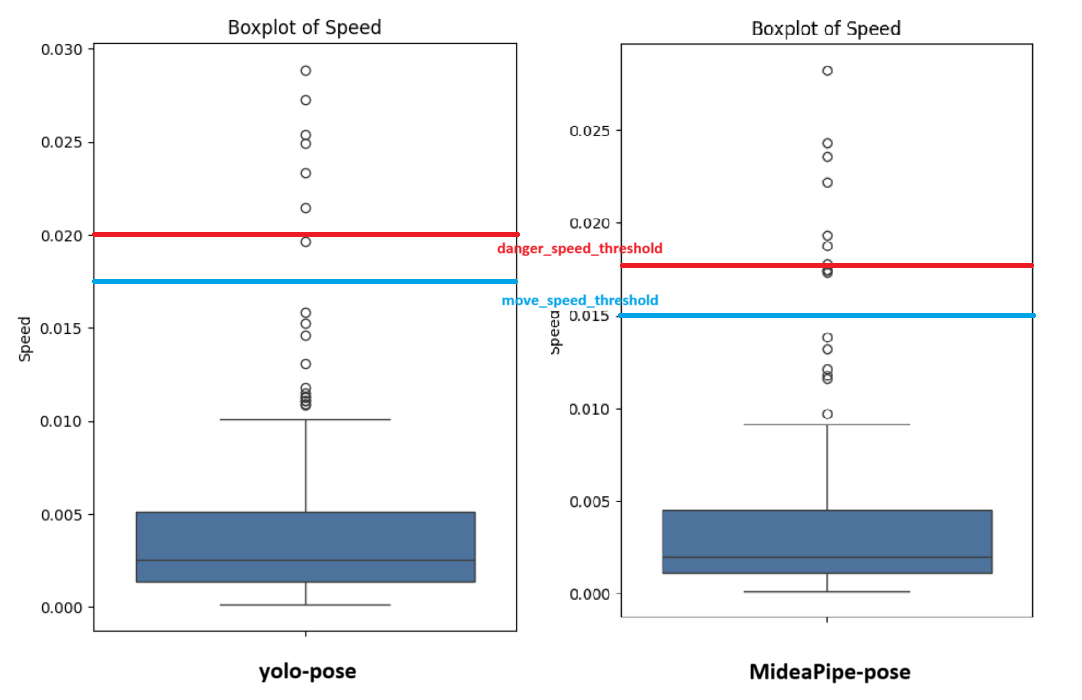
* 시각화가 잘 표현된 것을 보아서 임계값 부분을 건드리는게 좋을듯하여 다시 speed값을 박스 플롯으로 변환하여 비교해보기로 하였다.
* 위와 같이 speed가 다르게 잡혀서 이를 기반으로 Treshold값을 아래를 기준으로 세밀하게 조정을 해보았다.
# 속도 임계값 설정
danger_speed_threshold = 0.015 # 낙상위험 속도 임계값
move_speed_threshold = 0.013 # 낙상->정상 속도 임계값
danger_frame_threshold = 3 # 낙상 판단 프레임 수 (FPS 기준)